|
Вы уверены, что строка верна? config vlan v2 add untagged 9-16 Как в таком случае пользователи v2 получат доступ к разделяемым ресурсам? По-моему, должно быть config vlan v2 add untagged 9-24 |
Московский государственный технический университет им. Н.Э. Баумана
Опубликован: 25.06.2013 | Доступ: свободный | Студентов: 4237 / 1048 | Длительность: 18:32:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Лекция 1:
Основы коммутации
Архитектура коммутаторов
Одним из основных компонентов всего коммутационного оборудования является коммутирующая матрица (switch fabric). Коммутирующая матрица представляет собой чипсет, соединяющий множество входов с множеством выходов на основе фундаментальных технологий и принципов коммутации. Коммутирующая матрица выполняет три функции:
- переключает трафик с одного порта матрицы на другой, обеспечивая их равнозначность;
- предоставляет качество обслуживания (Quality of Service, QoS);
- обеспечивает отказоустойчивость.
Поскольку коммутирующая матрица является ядром аппаратной платформы, к ней предъявляются требования по масштабированию производительности и возможности быстрого развития системы QoS.
Производительность коммутирующей матрицы (switch capacity) определяется как общая полоса пропускания (bandwidth), обеспечивающая коммутацию без отбрасывания пакетов трафика любого типа (одноадресного, многоадресного, широковещательного).
"Неблокирующей" коммутирующей матрицей (non-blocking switch fabric) является такая матрица, у которой производительность и QoS не зависят от типа трафика, коммутируемого через матрицу, и производительность равна сумме скоростей всех портов:
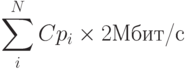
где1Умножение на 2 для дуплексного режима работы 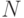 — количество портов,
— количество портов, 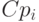 — максимальная производительность протокола, поддерживаемого i-м портом коммутатора.
— максимальная производительность протокола, поддерживаемого i-м портом коммутатора.
Например, производительность коммутатора с 24 портами 10/100 Мбит/с и 2 портами 1 Гбит/с вычисляется следующим образом:
((24 х 100 Мбит/с) + (2 х 1 Гбит/с)) х 2 = 8.8 Гбит/с
Коммутатор обеспечивает портам равноправный доступ к матрице, если в системе не установлено преимущество одних портов над другими.
Поскольку коммутирующая матрица располагается в ядре платформы коммутатора, то одним из наиболее важных вопросов остается ее отказоустойчивость. Этот вопрос решается за счет реализации отказоустойчивой архитектуры, предусматривающей резервирование критичных для работы коммутатора блоков.
Одним из ключевых компонентов архитектуры современных коммутаторов является контроллер ASIC (Application Specific Integrated Circuit). Контроллеры ASIC представляют собой быстродействующие и относительно недорогие кремниевые кристаллы, которые предназначены для выполнения определенных операций. Использование в архитектуре коммутаторов контроллеров ASIC повышает производительность системы, т.к. ASIC выполняет операции аппаратно, благодаря чему не возникают накладные расходы, связанные с выборкой и интерпретацией хранимых команд. Современные контроллеры ASIC часто содержат на одном кристалле 32-битные процессоры, блоки памяти, включая ROM, RAM, EEPROM, Flash, и встроенное программное обеспечение. Такие ASIC получили название System-on-a-Chip (SoC).
* Умножение на 2 для дуплексного режима работы.
В настоящее время существует много типов архитектур коммутирующих матриц. Выбор архитектуры матрицы во многом определяется ролью коммутатора в сети и количеством трафика, которое ему придется обрабатывать. В действительности, матрица обычно реализуется на основе комбинации двух или более базовых архитектур. Рассмотрим самые распространенные типы архитектур коммутирующих матриц.
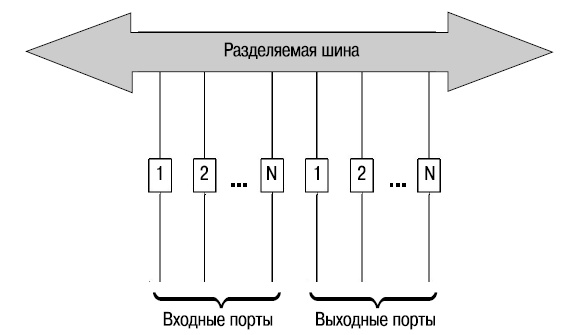
Архитектура с разделяемой шиной
Архитектура с разделяемой шиной (Shared Bus), как следует из ее названия, использует в качестве разделяемой среды шину, которая обеспечивает связь подключенных к ней устройств ввода-вывода (портов). Шина используется в режиме разделения времени, т.е. в каждый момент времени только одному источнику разрешено передавать по ней данные. Управление доступом к шине осуществляется через централизованный арбитр, который предоставляет источнику право передавать данные.
Применительно к системам с разделяемой шиной под термином "неблокирующая" понимается то, что сумма скоростей портов матрицы меньше, чем скорость шины. Т.е. производительность системы ограничена производительностью шины. Даже если общая полоса пропускания ниже производительности шины, количество и производительность устройств ввода-вывода ограничены производительностью централизованного арбитра.
Архитектура с разделяемой памятью
Улучшения архитектуры с разделяемой шиной привели к появлению высокопроизводительной архитектуры с разделяемой памятью (Shared Memory). Архитектура с разделяемой памятью обычно основана на использовании быстрой памяти RAM большой емкости в качестве общего буфера коммутационной системы, предназначенного для хранения входящих пакетов перед их передачей. Память обычно организуется в виде множества выходных очередей, ассоциирующихся с одним из устройств ввода-вывода или портом. Для обеспечения неблокирующей работы полоса пропускания памяти для операции "запись" и операции "чтение" должна быть равна максимальной суммарной полосе пропускания всех входных портов.
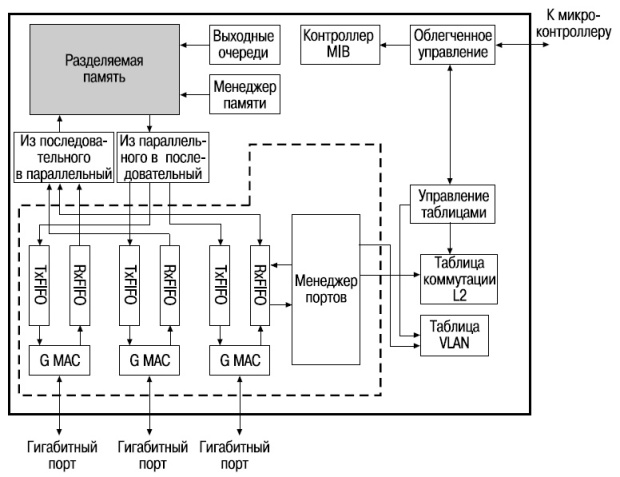
Типовая архитектура коммутаторов с разделяемой памятью показана на рис. 1.13 . Входящие пакеты преобразуются из последовательного формата в параллельный и затем записываются в двухпортовую память. Запись в память осуществляется по принципу мультиплексирования с разделением по времени (Time Division Multiplexing, TDM), поэтому в каждый момент времени только один входной порт может поместить кадр в ячейку разделяемой памяти. Заголовки каждого кадра передаются в контроллер памяти. На основе этой информации он определяет выходной порт назначения и выходную очередь, в которую необходимо поместить кадр. Порядок, в котором выходные кадры будут считываться из памяти, определяется контроллером памяти с помощью механизма арбитража. Считанные кадры отправляются на соответствующие выходные порты (выходные кадры демультиплексируются с разделением по времени таким образом, что только один выходной порт может получить доступ к разделяемой памяти), где они вновь преобразуются из параллельного формата в последовательный.
Одним из преимуществ использования общего буфера для хранения пакетов является то, что он позволяет минимизировать количество выходных буферов, требуемых для поддержания скорости потери пакетов на низком уровне. С помощью централизованного буфера можно воспользоваться преимуществами статического разделения буферной памяти. При высокой скорости трафика на одном из портов он может захватить большее буферное пространство, если общий буферный пул не занят полностью.
Архитектура с разделяемой памятью обладает рядом недостатков. Так как пакеты записываются и считываются из памяти одновременно, она должна обладать суммарной пропускной способностью портов, т.е. операции записи и чтения из памяти должны выполняться в N (количество портов) раз выше скорости работы портов. Т.к. доступ к памяти физически ограничен, необходимость ускорения работы в N раз ограничивает масштабируемость архитектуры. Более того, контроллер памяти должен обрабатывать пакеты с той же скоростью, что и память. Такая задача может быть трудно выполнимой в случае управления множеством классов приоритетов и сложными операциями планирования. Коммутаторы с разделяемой памятью обладают единой точкой отказа, поскольку добавление еще одного общего буфера является сложным и дорогим. В результате этого в чистом виде архитектура с разделяемой памятью используется для построения коммутаторов с небольшим количеством портов.
Сергей Некрасов
Антон Донсков
|
Есть ли какой-либо эмулятор DES-3200-28 т.к. читать то это читать, а практика оно лучше, а за неимением железки, которая для простого смертного все таки денег стоит, как то тоскливо.... |