Опубликован: 12.07.2012 | Доступ: свободный | Студентов: 356 / 26 | Оценка: 4.00 / 4.20 | Длительность: 11:07:00
Тема: Программирование
Специальности: Программист
Лекция 6:
Optimizing compiler. Auto parallelization
Profitability of auto parallelization
Let’s consider simple fortran test:
REAL :: a(1000,1000),b(1000,1000),
c(1000,1000)
integer i,j,rep_factor
DO I=1,1000
DO J=1,1000
A(J,I) = I
B(J,I) = I+J
C(J,I) = 0
END DO
END DO
DO rep_factor=1,1000
C=B/A+rep_factor
END DO
END

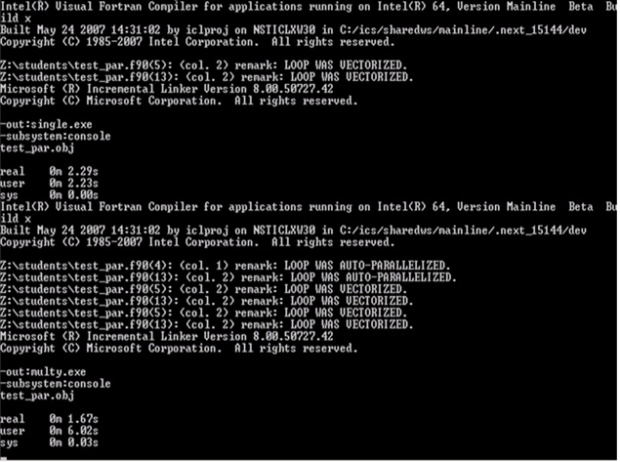
This slide demonstrates auto parallelization speedup. We have improvement on real time from 2.29 s. to 1.67 s. User time has been changed from 2.23 s. to 6.02 s. It means that amount of work was increased.
void matrix_mul_matrix(int n,
float C[n][n], float A[n][n],
float B[n][n]) {
int i,j,k;
for (i=0; i<n; i++)
for (j=0; j<n; j++) {
C[i][j]=0;
for(k=0;k<n;k++)
C[i][j]+=A[i][k]*B[k][j];
}
}
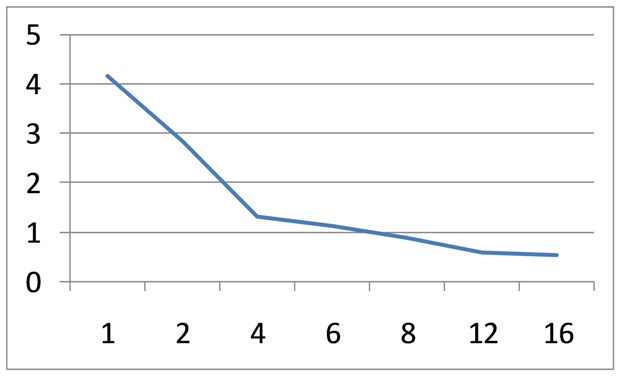
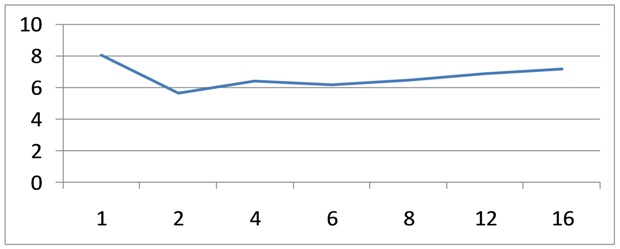
CPU cores may compete for some processor resources, for example for cash subsystem and for system bus. Bus bandwidth can be bottleneck for some algorithms. The right picture demonstrates the relation between time and number of threads for matrix multiplication loop. It is an example of highly scalable algorithm.
void matrix_add(int n, float Res[n][n],float A1[n][n], float A2[n][n],
float A3[n][n],float A4[n][n], float A5[n][n], float A6[n][n],
float A7[n][n], float A8[n][n]) {
int i,j;
for (i=0; i<n; i++)
for (j=1; j<n-1; j++)
Res[i][j]=A1[i][j]+A2[i][j]+A3[i][j]+A4[i][j]+
A5[i][j]+A6[i][j]+A7[i][j]+A8[i][j]+
A1[i][j+1]+A2[i][j+1]+A3[i][j+1]+A4[i][j+1]+
A5[i][j+1]+A6[i][j+1]+A7[i][j+1]+A8[i][j+1];