


|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2189 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 13:
Сбалансированные деревья
Слоеные списки
В этом разделе мы рассмотрим способ разработки быстрых реализаций операций с таблицами символов, который на первый взгляд кажется совершенно не похожим на рассмотренные методы на базе деревьев, хотя в действительности они очень тесно связаны. Этот подход основан на рандомизированной структуре данных и практически наверняка обеспечивает почти оптимальную производительность всех базовых операций для АТД таблицы символов. Лежащая в основе алгоритма структура данных, которая была разработана Пуфом (Pugh) в 1990 г. (см. раздел ссылок), называется слоеным списком (skip list, часто переводится как " список пропусков " ). В ней используются дополнительные ссылки в узлах связного списка для пропуска больших частей списка во время поиска.
На рис. 13.22 приведен простой пример, в котором каждый третий узел в упорядоченном связном списке содержит дополнительную ссылку, которая позволяет пропустить три узла списка. Эти дополнительные ссылки можно использовать для ускорения операции найти: сначала выполняется просмотр верхнего списка до тех пор, пока не будет найден ключ или узел с меньшим ключом, содержащий ссылку на узел с большим ключом; затем используются нижние ссылки для проверки двух промежуточных узлов. Этот метод ускоряет выполнение операции найти в три раза, поскольку при успешном поиске k-го узла в списке проверяется лишь около к/3 узлов.
Эту конструкцию можно размножить и добавить вторую дополнительную ссылку, позволяющую быстрее просматривать узлы с дополнительными ссылками, и т.д. Кроме того, можно обобщить это построение, пропуская с помощью каждой ссылки различное количество узлов.
Определение 13.5. Слоеный список — это упорядоченный связный список, в котором каждый узел содержит различное количество ссылок, причем i-е ссылки в узлах образуют односвязные списки, пропускающие узлы с менее чем i ссылками.
На рис. 13.23 изображен этот же слоеный список и приведен пример поиска и вставки нового узла. Для выполнения поиска просматривается верхний список, пока не будет найден ключ поиска или узел с меньшим ключом, содержащий ссылку на узел с большим ключом. Затем мы переходим ко второму сверху списку и повторяем эту процедуру, продолжая этот процесс, пока не будет найден искомый ключ или пока на нижнем уровне не будет обнаружено его отсутствие. Для вставки выполняется поиск со вставкой в списки нового узла при переходе с уровня k на уровень k — 1, если новый узел содержит не менее k дополнительных ссылок.
Внутреннее представление узлов предельно простое. Единственная ссылка односвязного списка заменяется массивом ссылок и целочисленной переменной, содержащей количество ссылок в узле.
Каждый третий узел в этом списке содержит вторую ссылку, поэтому можно " скакать " по списку с почти в три раза большей скоростью по сравнению с использованием только первых ссылок. Например, до двенадцатого узла в списке (P), можно добраться из начала списка, пройдя лишь по пяти ссылкам: по вторым ссылкам на C, G, L, N, а затем по первой ссылке узла N на P.
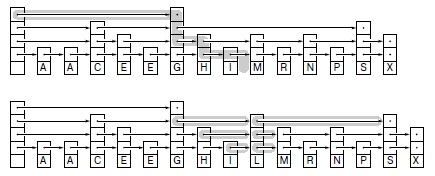
Добавляя дополнительные уровни к структуре, показанной на рис. 13.22, и позволяя ссылкам пропускать различное количество узлов, мы получаем пример обобщенного списка пропусков. Для поиска ключа в этом списке процесс начинается с самого верхнего уровня с переходом вниз при каждой встрече ключа, который не меньше ключа поиска. Вот как выполняется (вверху) поиск ключа L: начав с уровня 3, следуем по первой ссылке, затем спускаемся по G (считая пустые ссылки ссылками на сигнальные узлы), затем до I, спускаемся на уровень 2, поскольку S больше чем L, затем спускаемся на уровень 1, поскольку M больше L. Для вставки узла L с тремя ссылками мы связываем его с тремя списками там, где при поиске были обнаружены ссылки на большие ключи.
Управление памятью — вероятно, наиболее сложный аспект использования слоеных списков. Объявления типов и код для выделения памяти под новые узлы будут рассмотрены при обсуждении алгоритма вставки. Пока же достаточно отметить, что доступ к узлу, который следует за узлом t на (к + 1)-ом уровне слоеного списка, обеспечивается выражением t->next[k]. Рекурсивная реализация в программе 13.7 демонстрирует, что поиск в слоеных списках не только является очевидным обобщением поиска в односвязных списках, но и подобен бинарному поиску или поиску в BST-деревьях. Вначале проверяется, содержится ли ключ поиска в текущем узле; если нет, ключ в текущем узле сравнивается с ключом поиска. Если он больше, выполняется один рекурсивный вызов, а если меньше — другой.
Программа 13.7. Поиск в слоеных списках
Для k, равного 0, этот код эквивалентен программе 12.6, выполняющей поиск в односвязных списках. Для общего случая k мы переходим к следующему узлу списка на уровне k, если его ключ меньше ключа поиска, и вниз на уровень k-1, если его ключ не меньше.
private:
Item searchR(link t, Key v, int k)
{ if (t == 0) return nullItem;
if (v == t->item.key()) return t->item;
link x = t->next[k];
if ((x == 0) || (v < x->item.key()))
{ if (k == 0) return nullItem;
return searchR(t, v, k-1);
}
return searchR(x, v, k);
}
public:
Item search(Key v)
{ return searchR(head, v, lgN); }
Первой задачей, с которой мы сталкиваемся при необходимости вставки нового узла в слоеный список, является определение количества ссылок, которые должен содержать узел. Все узлы содержат по меньшей мере одну ссылку; следуя интуитивному представлению, отображенному на рис. 13.22, на втором уровне можно пропускать сразу по t узлов, если один из каждых t узлов содержит по меньшей мере две ссылки; продолжая далее, мы приходим к заключению, что один из каждых tj узлов должен содержать по меньшей мере j + 1 ссылок.
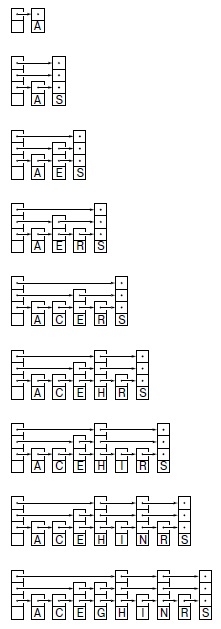
Для создания узлов с таким свойством мы выполняем рандомизацию с помощью функции, которая возвращает значение j + 1 с вероятностью 1/tj . Имея j, мы создаем новый узел с j ссылками и вставляем его в слоеный список, применяя рекурсивную схему, которая используется для операции найти, как показано на рис. 13.23. После достижения уровня j мы включаем новый узел в список при каждом спуске на уровень ниже. К этому моменту уже установлено, что элемент в текущем узле меньше ключа поиска и указывает (на уровне j) на узел, не меньший ключа поиска.
Здесь показан процесс вставки элементов с ключами A S E R C H I N G в первоначально пустой слоеный список. Узлы содержат j ссылок с вероятностью 1/2j .
При инициализации слоеного списка создается ведущий узел с максимальным количеством уровней, разрешенным в этом списке, и пустыми ссылками на всех уровнях. В программах 13.8 и 13.9 реализованы инициализация и вставка для слоеных списков.
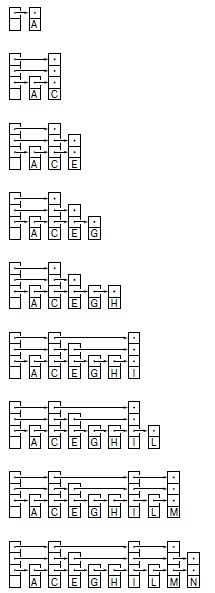
На рис. 13.24 показано построение слоеного списка из набора ключей, вставляемых в случайном порядке; а на рис. 13.25 приведен более объемный пример. На рис. 13.26 показано построение слоеного списка для тех же ключей, что и на рис. 13.24, но вставляемых в порядке возрастания. Как и для рандомизированных BST-деревьев, стохастические свойства слоеных списков не зависят от порядка вставки ключей.
Лемма 13.10. Для поиска и вставки в рандомизированный слоеный список с параметром t в среднем требуется порядка 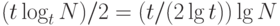 сравнений.
сравнений.
Мы ожидаем, что слоеный список должен иметь порядка 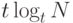 уровней, поскольку больше наименьшего значения j, для которого
tj = N
. На каждом уровне мы ожидаем, что на предыдущем уровне было пропущено примерно t узлов, а перед спуском на следующий уровень придется перебрать приблизительно половину из них. Как видно из примера на
рис.
13.25, количество уровней мало, но точное аналитическое обоснование этого свойства довольно сложно (см. раздел ссылок).
уровней, поскольку больше наименьшего значения j, для которого
tj = N
. На каждом уровне мы ожидаем, что на предыдущем уровне было пропущено примерно t узлов, а перед спуском на следующий уровень придется перебрать приблизительно половину из них. Как видно из примера на
рис.
13.25, количество уровней мало, но точное аналитическое обоснование этого свойства довольно сложно (см. раздел ссылок). 
Программа 13.8. Структуры данных и конструктор слоеного списка
Узлы в слоеных списках содержат массив ссылок, поэтому конструктор класса node должен выделить памяти под этот массив и обнулить все его ссылки. Константа lgNmax — максимальное количество уровней, которое разрешено в списке: ее значение можно задать равным пяти для совсем маленьких списков или 30 — для огромных. Переменная N, как обычно, содержит количество элементов в списке, а lgN — количество уровней. Пустой список является ведущим узлом с lgNmax пустыми ссылками, при этом N и lgN должны быть равны 0.
private:
struct node
{ Item item; node **next; int sz;
node(Item x, int k)
{ item = x; sz = k; next = new node*[k];
for (int i = 0; i < k; i++) next[i] = 0;
}
};
typedef node *link;
link head;
Item nullItem;
int lgN;
public:
ST(int)
{ head = new node(nullItem, lgNmax); lgN = 0; }
Программа 13.9. Вставка в слоеные списки
Мы генерируем новый j-связный узел с вероятностью 1 / 2j , затем перемещаемся по пути поиска точно так же, как в программе 13.7, но включаем новый узел при спуске на каждый из j нижних уровней.
private:
int randX()
{ int i, j, t = rand();
for (i = 1, j = 2; i < lgNmax; i++, j += j)
if (t > RAND MAX/j) break;
if (i > lgN) lgN = i;
return i;
}
void insertR(link t, link x, int k)
{ Key v = x->item.key(); link tk = t->next[k];
if ((tk == 0) || (v < tk->item.key()))
{ if (k < x->sz)
{ x->next[k] = tk; t->next[k] = x; }
if (k == 0) return;
insertR(t, x, k-1); return;
}
insertR(tk, x, k);
}
public:
void insert(Item v)
{ insertR(head, new node(v, randX()), lgN); }
Здесь показан результат вставки в случайном порядке 50 ключей в первоначально пустой список. Доступ к каждому из ключей можно получить, пройдя не более чем по 7 ссылкам.
Лемма 13.11. Слоеные списки содержат в среднем (t / (t — 1)) N ссылок.
Имеется N ссылок на нижнем уровне, N/t ссылок на первом уровне, около N/t2 ссылок на втором уровне и т.д., что в сумме дает примерно 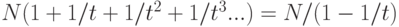 ссылок во всем списке.
ссылок во всем списке.
Выбор подходящего значения t приводит нас к обычному балансу между временем выполнения и требуемым объемом памяти. При t = 2 в слоеных списках требуется в среднем около lg N сравнений и 2N ссылок — показатель, сравнимый с лучшей производительностью при использовании BST-деревьев. Для больших значений t время поиска и вставки увеличивается, но объем дополнительной памяти, требуемой для ссылок, уменьшается. Продифференцировав выражение из свойства 13.10, можно определить, что ожидаемое количество сравнений, требуемое для выполнения поиска в слоеном списке, минимально при t = e.
В следующей таблице приведены значения коэффициента при Nlg N в выражении, где определяется количество сравнений, необходимых для построения таблицы из N элементов:
Если для выполнения сравнений, переходов по ссылкам и рекурсивного спуска требуются затраты, которые существенно отличаются от приведенных значений, можно аналогично выполнить более точные расчеты (см. упражнение 13.83).
Поскольку время выполнения поиска является логарифмическим, перерасход памяти можно уменьшить (если объем памяти ограничен), чтобы он не слишком превышал объем памяти, требуемый для односвязных списков — увеличив значение t. Точная оценка времени выполнения зависит от распределения относительных затрат на переходы по ссылкам в списках и на спуск на следующий уровень. В "Внешний поиск" мы вернемся к этому балансу между временем и памятью при рассмотрении задачи индексирования очень больших файлов.
Реализация других функций таблицы символов с помощью слоеных списков очевидна. Например, в программе 13.10 приведена реализация операции удалить, в которой применяется та же рекурсивная схема, что и для операции вставить в программе 13.9. Для удаления узла он удаляется из всех списков (в которые он был включен операцией вставить), и после удаления узла из нижнего списка он освобождается (в отличие от его создания перед просмотром списка для вставки). Операция объединить реализуется с помощью объединения списков (см. упражнение 13.78); для реализации операции выбрать в каждый узел добавляется поле, содержащее количество узлов, пропущенных ссылкой на него самого высокого уровня (см. упражнение 13.77).
Здесь показан процесс вставки элементов с ключами A C E G H I N R S в первоначально пустой слоеный список. Стохастические свойства списка не зависят от порядка вставки ключей.
Программа 13.10. Удаление в слоеных списках
Для удаления из слоеного списка узла с заданным ключом мы удаляем его из списка каждого уровня, в который он включен, а затем, по достижении нижнего уровня, удаляем сам узел.
private:
void removeR(link t, Key v, int k)
{ link x = t->next[k];
if (!(x->item.key() < v))
{ if (v == x->item.key())
{ t->next[k] = x->next[k]; }
if (k == 0) { delete x; return; }
removeR(t, v, k-1); return;
}
removeR(t->next[k], v, k);
}
public:
void remove(Item x)
{ removeR(head, x.key(), lgN); }
Слоеные списки легко обобщить в качестве систематического способа быстрого перемещения по связному списку, однако важно понимать, что лежащая в их основе структура данных — всего лишь альтернативное представление сбалансированного дерева. Например, на рис. 13.27 приведено представление в виде слоеного списка сбалансированного 2-3-4-дерева с рис. 13.10.
Алгоритмы для сбалансированного 2-3-4-дерева из раздела 13.3 можно реализовать, используя абстракцию слоеного списка, а не абстракцию RB-дерева из раздела 13.4. Результирующий код получается при этом несколько сложнее кода рассмотренных представлений (см. упражнение 13.80). В "Внешний поиск" мы еще вернемся к этой взаимосвязи между слоеными списками и сбалансированными деревьями.
Идеальный слоеный список, показанный на рис. 13.22, является жесткой структурой, которую трудно поддерживать при вставке нового узла (как и упорядоченный массив для реализации бинарного поиска), поскольку вставка требует изменения всех ссылок во всех узлах, следующих за вставленным. Один из способов сделать структуру более гибкой заключается в построении списков, в которых каждая ссылка пропускает одну, две или три ссылки находящегося под ней уровня: как видно из рис. 13.27, эта организация соответствует 2-3-4-деревьям. Еще одним эффективным способом уменьшения жесткости структуры является рандомизированный алгоритм, рассмотренный в этом разделе; другие альтернативы будут рассмотрены в "Внешний поиск" .
Здесь представлено 2-3-4-дерево с рис. 13.10 в виде слоеного списка. В общем случае слоеные списки соответствуют сбалансированным многопутевым деревьям с одной или более ссылкой на узел (допускаются и 1-узлы без ключей и с 1 ссылкой). Для построения слоеного списка, соответствующего дереву, мы присваиваем каждому узлу количество ссылок, равное его высоте в дереве, а затем связываем узлы по горизонтали. Для построения дерева, соответствующего слоеному списку, мы группируем пропущенные узлы и рекурсивно связываем их с узлами на следующем уровне.
Упражнения
13.75. Нарисуйте слоеный список, образованный вставками элементов с ключами E A S Y Q U T I O N в указанном порядке в первоначально пустой список, если функция randX возвращает последовательность значений 1, 3, 1, 1, 2, 2, 1, 4, 1 и 1.
13.76. Нарисуйте слоеный список, образованный вставками элементов с ключами E A I N O Q S T U Y в указанном порядке в первоначально пустой список, если функция randX возвращает такие же значения, как и в упражнении 13.75.
13.77. Реализуйте операцию выбрать для таблицы символов на основе слоеного списка.
13.78. Реализуйте операцию объединить для таблицы символов на основе слоеного списка.
13.79. Измените реализации операций найти и вставить, приведенные в программах 13.7 и 13.9, так, чтобы списки заканчивались не пустыми ссылками, а сигнальными узлами.
13.80. С помощью слоеных списков реализуйте операции создать, найти и вставить для таблиц символов, использующих абстракцию сбалансированного 2-3-4-дерева.
13.81. Сколько случайных чисел требуется в среднем для построения слоеного списка с параметром t, если используется функция randX из программы 13.9?
13.82. Для t = 2 измените программу 13.9 так, чтобы в функции randX исключить цикл for. Совет: последние j разрядов в двоичном представлении числа t принимают значение любого отдельного разряда j с вероятностью 1/2j.
13.83. Подберите значение t, которое минимизирует затраты на поиск для случая, когда затраты на переход по ссылке в а раз превышают затраты на выполнение сравнения, а затраты на переход на один уровень рекурсии вниз в р раз превышают затраты на выполнение сравнения.
13.84. Разработайте реализацию слоеного списка, в которой узлы содержат сами ссылки, а не ссылку на массив ссылок, как в программах 13.7 — 13.10. Совет: поместите массив в конец узла.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |