Лекция 11: Расширение возможностей группы ресурсов
Изменение существующей группы ресурсов для использования политики DNP
Нельзя изменить политику перемещения при сбое на DNP, если какие-либо ресурсы на данный момент являются частью группы ресурсов. При попытке изменения группы ресурсов через SMIT выдается ошибка, если прежде не удалить ресурсы. Для изменения политики можно сделать одно из двух:
- Удалить группу ресурсов и заново создать ее, выбрав политику перемещения при сбое Dynamic Node Priority (Динамический приоритет узлов).
- Перейти в экран Change/Show Resources and Attributes for a Resource Group (Изменить/показать ресурсы и атрибуты группы ресурсов), обнулить все ресурсы, входящие в группу ресурсов и нажать Enter. Затем следует выполнить переход Extended Configuration (Расширенное конфигурирование) > Extended Resource Configuration (Расширенное конфигурирование ресурсов) > Extended Resource Group Configuration (Расширенное конфигурирование групп ресурсов) > Change a Resource Group (Изменение группы ресурсов) и установить политику перемещения при сбое DNP. Затем можно выполнить назначение ресурсов в группу ресурсов и синхронизацию кластера, чтобы изменения вступили в действие.
Принцип работы динамического приоритета узлов
Начиная с HACMP 5.2 определение динамического приоритета узлов больше не опрашивает службы управления событиями (Event Management Services, emsvcs). Вместо этого clstrmgrES каждые 2 мин. опрашивает демон Resource Monitoring and Control (ctrmc) и ведет таблицу, в которой хранятся показатели текущего объема памяти, загруженности процессора и дискового ввода-вывода для каждого узла.
Мониторы ресурсов, содержащие информацию по каждой политике, следующие:
- IBM.PhysicalVolume,
- IBM.Host.
Каждый из этих мониторов может быть опрошен во время функционирования путем выполнения команд, представленных в примере 11.6
#lsrsrc -Ad IBM.Host | grep TotalPgSpFree TotalPgSpFree = 123076 PctTotalPgSpFree = 93.8995 flsrsrc -Ad IBM.Host I grep PetTotalTimeldle PctTotalTlrtieldle = 99.6649 #1srsrc -Ap IBM.PhysicalVolume resource 1: Name = "vpath7"Пример 11.6. Верификация показателей ресурсов
Текущую таблицу, которую ведет clstrmgrES, можно вывести путем выполнения команд, представленных в примере 11.7 .
#l5src -Is clstrmgrES Current state: ST_STABLE sccsid = "@(#)36 1.135.1.37 src/haes/usr/sbin/cluster/hacmprd/main.C, hacmp.pe, 51haes_r530, r5300525a 6/20/05 14:13:01" i_local_nodeid 1, i_1ocal_siteid -1, my_handle Z ml_1dx[l]=0 ml_idx[2] = l ml_idx[3]=2 There are 0 events on the Ibcast queue There are 0 events on the RM Ibcast queue CLversion: 8 local node vrmf is 5300 cluster fix level is "0" The following timer(s) are currently active: Current DNP values DNP Values for Nodeld - 1 NodeName - cobra PgSpFree = 130771 PvPctBusy = 0 PctTotalTimeldle = 99.947917 DNP Values for Nodeld - 2 NodeName - python PgSpFree = 130741 PvPctBusy = 0 PctTotalTimeldle - 99.879167 DNP Values for Nodeld - 3 NodeName - viper PgSpFree = 124489 PvPctBusy = 0 PctTotalTimeldle = 99.941667Пример 11.7. Значения DNP, выводимые диспетчером кластера
Значения в таблице употребляются для определения DNP в случае перемещения при сбое. Если в процессе опроса текущего состояния демоном clstrmgrES происходит перемещение при сбое, для определения DNP используется значение, имевшее место, когда кластер последний раз был в стабильном состоянии.
Сценарий тестирования динамического приоритета узлов
Для тестирования функций динамического приоритета узлов мы установили кластер из трех узлов с двумя группами ресурсов, использующими различные политики DNP. Первая группа ресурсов A (APP1_RG) использует значение cl_highest_idle_cpu, тогда как группа ресурсов B (APP2_RG) применяет значение cl_highest_free_mem для определения узла для перемещения при сбое. Для каждой группы ресурсов мы выполнили тестирование различных сценариев перемещения при сбое и задокументировали результаты. На рис. 11.3 представлена схема используемой конфигурации.
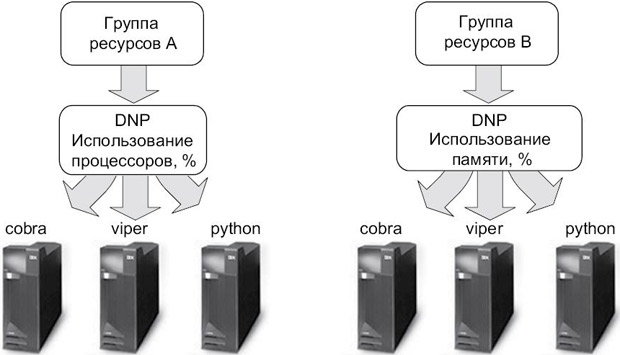
В нашей среде мы установили для каждой группы ресурсов использование следующих политик запуска/перемещения при сбое/возврате после восстановления:
Startup = Online Using Distribution Policy Fallover = Fallover Using Dynamic Node Priority Fallback = Never Fallback Мы установили следующий порядок узлов для обеих групп ресурсов: cobra viper python
Наша топология содержит сеть Ethernet с применением IP-синонимов. Это означает, что в случае перемещения при сбое на одном узле могли располагаться несколько групп ресурсов. Это может произойти только в том случае, если определение узла с наименьшим использованием процессора и определение узла с наименьшим употреблением памяти указывают на один и тот же узел.
Этапы сценария тестирования DNP
В целях упрощения тестирования мы не использовали реальные рабочие нагрузки приложений для перегрузки процессоров или памяти узла. Вместо этого мы запустили цикл, чтобы загрузить два процессора, и применили команду rmss, чтобы логически сократить количество памяти, видимой в системе, инициируя выполнение операций подкачки.
Ниже приведен перечень действий, которые мы выполнили, чтобы убедиться в применении политик DNP.
- Мы запустили службы кластера на узле cobra. Только первая группа ресурсов (APP1_RG) была подключена в связи с установленной политикой Online Using Distribution Policy (Подключение с использованием политики распределения).
- Мы перешли в smit hacmp > System Management (C-SPOC) > HACMP Resource
Group and Application Management (Управление группами ресурсов и приложениями
HACMP) > Bring a Resource Group Online (Перевести группу ресурсов в подключенное
состояние), после чего выбрали APP2_RG, затем выбрали Restore_Node_Priority_Order
и нажали Enter. Это вызвало подключение второй группы ресурсов (APP2_RG) на узле
cobra, как показано в
примере 11.8
:Это позволило освободить узлы ( viper и python ), что дает нам возможность применять два узла для выполнения перемещения при сбое. Это также позволило нам протестировать определение показателей неиспользуемой памяти и процессора на следующем этапе.
f/usr/es/sbin/cluster/uti)ities/clRGinfo APP1_RG ONLINE cobra OFFLINE viper OFFLINE python APP2_R6 ONLINE cobra OFFLINE viper OFFLINE python
Пример 11.8. Информация о группах ресурсов - Мы выполнили такую последовательность команд на узле viper, чтобы уменьшить количество доступной памяти и инициировать операции подкачки, как показано в
примере 11.9
:Сначала мы сократили объем памяти на узле viper до 2 Гб, уменьшив, таким образом, объем доступной памяти. Затем мы использовали команду lptest, чтобы сгенерировать запись большого количества символов в файл, что инициирует операции подкачки. Мы осуществляли мониторинг изменений значения TotalPgSpFree в классе IBM.Host. В результате повышенной нагрузки на память узла viper узел python стал следующим логичным вариантом при определении DNP для группы ресурсов APP1_RG.
cobra-#rmss -p Simulated memory size is 8192 Mb. viper-#rmss -p Simulated memory size is 8192 Mb. viper-#rmss -c 2000 Simulated memory size changed to 2000 Mb. viper-#lptest 80 1000000000 > /appl/garbageJ41e.out viper-#lsps -s Total Paging Space Percent Used 512MB 7% viper-#lsrsrc -Ad IBM.Host grep PctTotalPgSpFree PctTotalPgSpFree = 93.8995
Пример 11.9. Инициирование операций подкачки - Мы выполнили два скрипта ksh, чтобы сгенерировать цикл для загрузки двух
процессоров на узле viper (
пример 11.10
).В результате выполнения двух экземпляров скрипта в фоновом режиме два процессора оказались перегружены. Результаты приведены в примере 11.11 :
#vi cpu_loopl while true do done #./cpu_loopl #./cpu_loop2
Пример 11.10. Инициирование нагрузки на процессорМы перегрузили два процессора на узле viper, так как он был следующим узлом в списке узлов группы ресурсов. Таким образом, в результате уменьшение количества неиспользуемых процессоров узел python стал следующим логичным вариантом при определении DNP для группы ресурсов APP2_RG.#sar -P ALL 5 AIX p630nO2 3 5 000685BF4C00 07/08/05 System configuration: lcpu=4 11:56:46 cpu %usr %sys %wio %idle 11:56:51 0 0 0 0 100 1 100 0 0 0 2 100 0 0 0 3 0 0 0 100 50 0 0 50
Пример 11.11. Проверка нагрузки на процессор - Мы выполнили постепенную остановку HACMP с передачей ресурсов на резервные узлы (graceful with takeover) на узле cobra.
После остановки служб кластера на узле было выполнено определение DNP по
значениям в текущей таблице clstrmgrES. Значения на момент перемещения при
сбое представлены в табл. 11.2.Как видим из результатов, наилучшим целевым узлом является узел python. Процесс выполнения определения DNP можно просмотреть в файле /tmp/clstrmgr.debug во время перемещения при сбое ( пример 11.12 ).
Таблица 11.2. Определение целевого узла DNP для перемещения при сбое по первому сценарию Узлы кластера Наибольший показатель бездействия процессора Наибольший показатель свободной памяти viper 93.8995 93.8995 python 93.8995 93.8995 Наилучший целевой узел python python #more /tmp/clstrmgr.debug Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: Using resource attribute IBM.Host.PctTotalTimeldle Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: for nodes 3, 2. Wed Jul 13 10:40:53 NodeList: :RmcComputeNodePrion'ty: using values , 0.0000, 0.0000. Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: condition is DNPJargest Wed Jul 13 10:40:53 In largest_comparison Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: Computed node order 3, 2. Wed Jul 13 10:40:53 For Resource Group APP1_RG, BestNode got node order Wed Jul 13 10:40:53 NodeList::showNodeList: Got the following 2 node IDs: Wed Jul 13 10:40:53 NodeList::showNodeList: 3 2 Wed Jul 13 10:40:53 The best node for group APP1_RG is python. Wed Jul 13 10:40:53 RGPA got viper as highest priority node. Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: Using resource attribute IBM.Host.TotalPgSpFree Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: for nodes 3, 2. Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: using values , 0.0000, 0.0000. Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: condition is DNPJargest Wed Jul 13 10:40:53 In largest_comparison Wed Jul 13 10:40:53 NodeList::RmcComputeNodePriority: Computed node order 3, 2. Wed Jul 13 10:40:53 For Resource Group APP2_RG, BestNode got node order Wed Jul 13 10:40:53 NodeList::showNodeList: Got the following 2 node IDs: Wed Jul 13 10:40:53 NodeList::showNodeList: 3 2 Wed Jul 13 10:40:53 The best node for group APP2_RG is python. Wed Jul 13 10:40:53 RGPA got viper as highest priority node.
Пример 11.12. Сообщения отладки диспетчера кластера во время перемещения при сбое - Мы выполнили реинтеграцию узла cobra в кластер.
- Мы внесли изменения в параметры памяти и процессора во второй раз. На этот
раз настройка узлов cobra и viper делается таким образом, чтобы при определении
DNP выполнялось распределение двух групп ресурсов на узле python между двумя
разными узлами (
пример 11.13
).Мы перегрузили два процессора на узле viper и инициировали операции подкачки на узле cobra, чтобы политика DNP в каждой группе ресурсов распределила их по разным узлам.
viper-#rmss -r Simulated memory size is 8192 Mb. viper-#./cpuloop1 viper- #./cpuloop2 viper-#sar -P ALL 5 AIX p630n02 3 5 00065BF4C00 07/08/05 System configuration: lcpu=4 18:03:20 cpu %usr %sys %wio %idle 18:03:25 0 0 0 0 100 1 100 0 0 0 2 100 0 0 0 3 0 0 0 100 50 0 0 50 viper-A*lsps -s Total Paging Space Percent Used 512MB 1% cobra-#rmss -c 2000 Simulated memory size changed to 2000 Mb. cobra-#lptest 80 1000000000 > /app1/garbage_file.out cobra-#lsps -s Total Paging Space Percent Used 512MB 6 %
Пример 11.13. Инициирование нагрузки на процессор и память - Мы выполнили halt -q на узле python. Это вызвало перемещение группы ресурсов APP1_RG на узел cobra, так как на нем были доступны все процессоры. Группа ресурсов APP2_RG была перемещена на узел viper, так как на нем не выполнялись операции подкачки и он имел больше свободной памяти. Табл. 11.3 показывает текущие значения clstrmgrES на момент перемещения при сбое.
| Узел кластера | Наибольший показатель бездействия процессора | Наибольший показатель свободной памяти |
|---|---|---|
| viper | 93.8995 | 93.8995 |
| python | 93.8995 | 93.8995 |
| Наилучший целевой узел | cobra | viper |
Результаты тестирования сценария DNP
В результате выполнения сценария тестирования мы смогли доказать, что во время перемещения при сбое порядок в списке узлов по умолчанию игнорировался. После реинтеграции отказавшего узла мы изменили нагрузку на память и процессоры на двух бездействующих узлах и выполнили тестирование отказа узла, содержащего группы ресурсов. При определении DNP во второй раз было успешно выполнено распределение групп ресурсов по двум разным дежурным узлам.
В нашей среде мы использовали практичные команды для изменения нагрузки на процессоры и память систем. Мы считаем, что результаты будут такими же, когда нагрузка будет вызвана выполняющимся приложением. Во время настройки своей среды DNP обязательно протестируйте все возможные сценарии перемещения при сбое и выполните команды lsrscr -Ad и lssrc -ls clstrmgrES, описанные в этом руководстве, для мониторинга текущей нагрузки на процессоры, память и дисковый ввод-вывод на узлах кластера.