Лекция 10: Динамические LPAR (DLPAR) и виртуализация (VIO)
Сценарий 4: перемещение при сбое для рабочих LPAR в обратном порядке
Этот сценарий также состоит из двух частей. В начале мы имеем точно такую же конфигурацию, как и в сценарии 3 изначально службы кластера запущены на всех узлах и для каждого из них назначены следующие ресурсы:
- Jordan (фрейм 1) имеет 4 процессоров и 4 Гб памяти;
- Jessica (фрейм 1) имеет 2 процессора и 4 Гб памяти;
- Alexis (фрейм 2) имеет 1 процессор и 1 Гб памяти;
- свободный пул (фрейм 2) содержит 7 процессоров и 7 Гб памяти.
На этот раз мы сначала инициируем отказ узла Jessica своим предпочтительным методом или командой reboot -q. Это приводит к тому, что узел Alexis получает группу ресурсов app2 и оптимальное количество ресурсов, как показано на рис. 10.10.
Здесь необходимо отметить, что теперь Alexis имеет 3 процессора и 3 Гб памяти. Обычно группа ресурсов app2 имеет только 2 процессора и 2 Гб памяти на узле Jessica. Технически это может превышать необходимое количество ресурсов. Как видим, при предоставлении доступа к приложениям в конце может использоваться другое количество ресурсов, в зависимости от того, на каком LPAR/профиле раздела группа ресурсов оказывается в конечном итоге.
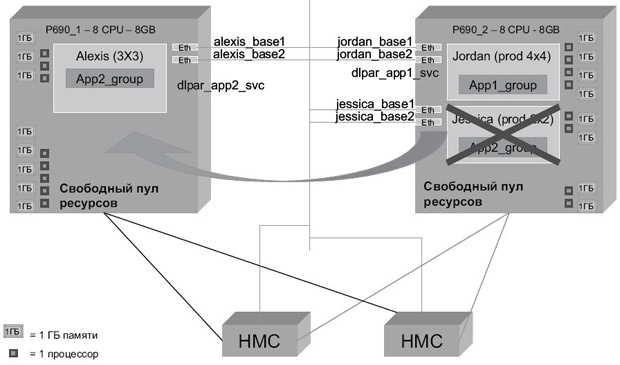
Вторая часть сценария начинается со следующей конфигурации:
- Jordan (фрейм 1) имеет 4 процессора и 4 Гб памяти;
- узел Jessica отключен;
- Alexis (фрейм 2) имеет 3 процессора и 3 Гб памяти;
- свободный пул (фрейм 2) содержит 5 процессоров и 5 Гб памяти.
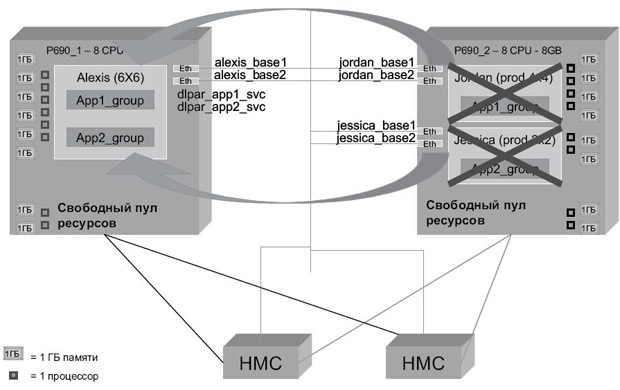
Теперь мы инициируем отказ узла Jordan командой reboot -q. Узел Alexis перехватывает группу ресурсов app1 и получает желаемые ресурсы, как показано на рис. 10.11. В итоге получаем то же, что и в предыдущем сценарии.
Сценарий 5: повторное получение группы ресурсов через rg_move
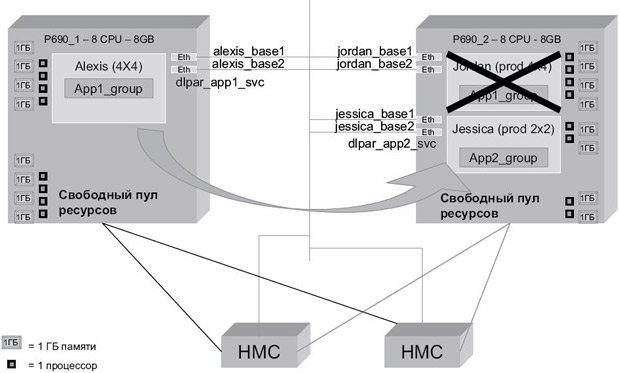
В этом сценарии мы начинаем с конфигурации, полученной в результате выполнения сценария 4 после перезапуска узлов Jordan и Jessica в кластере. Стартовая конфигурация имеет следующий вид:
- Jordan (фрейм 1) имеет 1 процессор и 1 Гб памяти;
- Jessica (фрейм 1) имеет 1 процессор и 1 Гб памяти;
- Alexis (фрейм 2) имеет 6 процессоров и 6 Гб памяти;
- свободный пул (фрейм 1) содержит 6 процессоров и 6 Гб памяти.
Узел Alexis на данный момент содержит две группы ресурсов. Мы выполняем rg_ move для перемещения группы ресурсов app2_rg с узла Alexis обратно на домашний узел Jessica. Узел Alexis освобождает 2 процессора и 2 Гб памяти, тогда как узел Jessica получает только 1 процессор и 1 Гб памяти, как показано на рис. 10.12. Это опять же является прямым следствием сочетания настроек обеспечения приложений ресурсами и параметров LPAR.
Сценарий 6: тестирование избыточности HMC
В этом сценарии мы тестируем избыточность HMC путем физического отключения сетевого подключения на одной из консолей HMC. В самом начале службы кластера выполняются на всех узлах и имеют следующие выделенные ресурсы:
- Jordan (фрейм 1) имеет 4 процессора и 4 Гб памяти;
- Jessica (фрейм 1) имеет 2 процессора и 4 Гб памяти;
- Alexis (фрейм 2) имеет 1 процессор и 1 Гб памяти;
- свободный пул (фрейм 2) содержит 7 процессоров и 7 Гб памяти.
Мы физически отключили кабель Ethernet из первой указанной консоли HMC с адресом 192.168.100.69. После этого мы инициировали отказ узла Jordan, чтобы вызвать перемещение при сбое. Это показано на рис. 10.13.
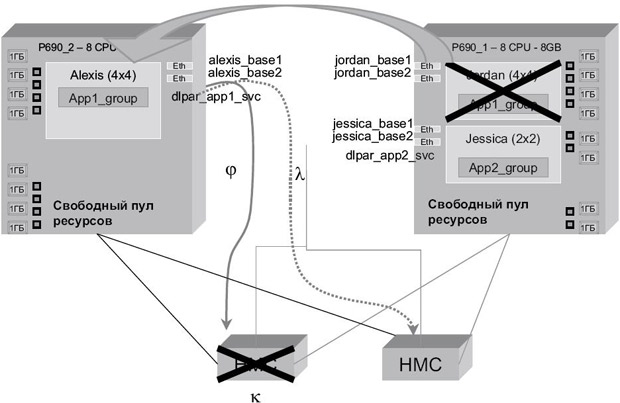
В процессе перемещения при сбое и попыток получения доступа к HMC происходит следующее:
- HACMP выдает ping-запрос на первую консоль HMC.
- Первая консоль HMC отключена и не реагирует.
- HACMP выдает ping-запрос на вторую консоль HMC, которая работает нормально и продолжает обрабатывать операции командной строки DLPAR.
Операции тестирования HMC можно просмотреть в файле /tmp/hacmp.out с использованием утилиты clhmcexec.