Планирование
Планирование групп ресурсов
В HACMP управление ресурсами осуществляется с использованием групп ресурсов.
Каждая группа ресурсов обрабатывается как контейнер, который может содержать следующие типы ресурсов: IP-метки, приложения, файловые системы и группы томов. Каждая группа ресурсов имеет настройки, которые определяют, когда и каким образом осуществляется ее перехват или освобождение. Можно выполнить точную настройку работы группы ресурсов без одновременного доступа при запуске узла, перемещении группы ресурсов на другой узел при отказе узла или при возврате группы ресурсов при реинтеграции узла.
К ресурсам и группам ресурсов применимы следующие правила и ограничения:
- Для обеспечения высокой доступности ресурса кластера в HACMP он должен быть частью группы ресурсов. Если требуется, чтобы ресурс содержался отдельно, можно определить группу для одного этого ресурса. В группе ресурсов может быть определен один или несколько ресурсов.
- Ресурс не может входить в несколько групп ресурсов.
- Мы рекомендуем поместить сервер приложения вместе с требуемыми им ресурсами в одну группу ресурсов (если нет причин поступить иначе).
- При включении одного узла в списки узлов для нескольких групп ресурсов следует убедиться, что этот узел способен обслуживать все группы ресурсов одновременно.
На рис. 3.20 упрощенно показана взаимосвязь между приложениями, группами томов и сервисными адресами, а также их совмещение в группах ресурсов. Группировка позволяет объединить приложение вместе с его общим дисковым хранилищем и сервисной IP-меткой в одну группу ресурсов. При этом все, что необходимо приложению, будет доступно, когда HACMP активизирует группу ресурсов.
После того как было решено, какие компоненты должны быть включены в группу ресурсов, необходимо выполнить планирование режимов работы группы ресурсов.
В таблице 3.13 приведены основные режимы работы (запуск, перемещение при сбое, возврат после восстановления), которые можно сконфигурировать для групп ресурсов в HACMP 5.3.
| Запуск | Перемещение при сбое | Возврат после восстановления |
|---|---|---|
| Подключение только на домашнем узле (Online on home node only, OHNO) для группы ресурсов | Перемещение на следующий по приоритету узел в списке | Без возврата после восстановления |
| Перемещение с использованием динамического приоритета узла | Возврат после восстановления на узел с более высоким приоритетом в списке | |
| Подключение с использованием политики распределения узлов | Перемещение на следующий по приоритету узел в списке | Без возврата после восстановления |
| Перемещение с использованием динамического приоритета узла | ||
| Подключение на первом доступном узле (Online on first available node, OFAN) | Перемещение на следующий по приоритету узел в списке | Без возврата после восстановления |
| Перемещение с использованием динамического приоритета узла | Возврат после восстановления на узел с более высоким приоритетом в списке | |
| Перевод в отключенный режим (только на ошибочном узле) | ||
| Подключение на всех доступных узлах | Перевод в отключенный режим (только на отказавшем узле) | Без возврата после восстановления |
Атрибуты группы ресурсов
Время установления при запуске
Атрибут времени установления (settling time) относится только к группам ресурсов с подключением на первом доступном узле (Online on First Available Node, OFAN) и устанавливает ожидание в течение заданного количества времени, прежде чем активизировать группу ресурсов. По истечении времени установления HACMP активизирует группу ресурсов на доступном узле с наивысшим приоритетом. Этот атрибут используется для того, чтобы избежать многократного перемещения групп ресурсов с одного узла на другой по мере подключения узлов с более высоким приоритетом.
Если узел запуска является домашним узлом для заданной группы ресурсов, время установления не выдерживается, вместо этого HACMP сразу же пытается подхватить группу ресурсов на этом узле.
Политика динамического приоритета узла
Настройка политики динамического приоритета узла (dynamic node priority, DNP) позволяет выбирать резервный узел на основе определенных критериев производительности. При этом для выбора резервного узла используется переменная ресурсов RMC, например "наименьшая нагрузка на процессор". При включенной политике динамического приоритета порядок резервных узлов определяется состоянием кластера на момент события, измеряемый выбранной переменной ресурсов RMC.
Если вы решите определить политики динамического приоритета узлов с использованием переменных ресурсов RMC для определения резервного узла для группы ресурсов, следует учитывать следующее:
- политика динамического приоритета узла наиболее полезна в кластере, где все узлы имеют одинаковую вычислительную мощность и объем памяти;
- политика динамического приоритета узла неприменима в кластерах, содержащих меньше трех узлов;
- политика динамического приоритета узла неприменима для групп ресурсов с одновременным доступом.
Необходимо помнить о том, что выбор резервного узла также зависит от таких факторов, как доступность сетевого интерфейса на узле.
Таймер отсроченного возврата после восстановления
Таймер отсроченного возврата (delayed fallback timer) после восстановления позволяет выполнить для группы ресурсов возврат после восстановления на узел с более высоким приоритетом в заданное время. Группа ресурсов, для которой сконфигурирован таймер отсроченного возврата после восстановления и которая в заданный момент времени находится не на домашнем узле, выполняет возврат на узел с более высоким приоритетом.
Зависимости групп ресурсов
HACMP 5.3 предлагает множество конфигураций, где можно задавать отношения между группами ресурсов, для которых следует обеспечивать управление запуском, перемещением при сбое и возвратом после восстановления.
Можно сконфигурировать:
- зависимости "родительский объект/дочерний объект", чтобы все связанные приложения в различных группах ресурсов обрабатывались в правильном порядке;
- зависимости расположения, чтобы определенные приложения в различных группах ресурсов подключались вместе на одном узле или сайте либо подключались на разных узлах.
Несмотря на то что по умолчанию все группы ресурсов обрабатываются параллельно, обработка зависимых групп ресурсов в HACMP осуществляется в соответствии с порядком, определенным зависимостью, и не обязательно параллельно. Зависимости групп ресурсов имеют действие в масштабе кластера и замещают любые настройки последовательного порядка обработки для любых групп ресурсов, входящих в зависимость.
Зависимости между группами ресурсов представляют прогнозируемый и надежный способ построения кластеров с многоуровневыми приложениями.
Метод перехвата IP-адреса и группы ресурсов
Нельзя смешивать метки IPAT посредством синонимов и IPAT посредством замены в одной группе ресурсов. Это ограничение применяется во время верификации ресурсов кластера.
Перехват IP-адреса не применяется к группам ресурсов с одновременным доступом.
Группа ресурсов может включать несколько сервисных IP-меток. При перемещении группы ресурсов с перехватом IP-адреса посредством синонимов все сервисные метки в группе ресурсов перемещаются в виде синонимов на доступный сетевой интерфейс.
Планирование диспетчера рабочей нагрузки
Диспетчер рабочей нагрузки (Workload Manager, WLM) дает возможность пользователям задавать целевые значения и ограничения применения процессора, физической памяти и пропускной способности дисковой подсистемы для различных процессов и приложений. Это обеспечивает более эффективный контроль использования критических системных ресурсов при пиковых нагрузках. HACMP позволяет выполнять конфигурирование классов WLM в группах ресурсов HACMP таким образом, чтобы запуск и остановка WLM и активная конфигурация WLM были под контролем кластера.
HACMP не проверяет каждый аспект конфигурации WLM, так что ответственность за целостность файлов конфигурации WLM возлагается на вас. После добавления классов WLM в группу ресурсов HACMP утилита верификации проверяет только лишь существование требуемых классов WLM. Таким образом, вы должны в полной мере понимать принципы работы WLM и внимательно выполнять конфигурирование классов WLM.
Заполнение таблицы планирования групп ресурсов
Таблица планирования групп ресурсов содержит всю требуемую информацию о планировании для групп ресурсов ( табл. 3.14).
| ТАБЛИЦА КЛАСТЕРА HACMP – ЧАСТЬ 11 из 11 ГРУППЫ РЕСУРСОВ | ДАТА: июль 2005 | |
|---|---|---|
| ИМЯ РЕСУРСА | C10RG1 | C10RG2 |
| Политика межсайтового управления | Игнорируется | Игнорируется |
| Имена узлов-участников | node01 node02 | node02 node01 |
| Политика запуска | Подключение только на домашнем узле (OHNO) | Подключение только на домашнем узле (OHNO) |
| Политика перемещения при сбое | Перемещение на следующий по приоритету узел в списке (FONP) | Перемещение на следующий по приоритету узел в списке (FONP) |
| Политика возврата после восстановления | Возврат на узел с более высоким приоритетом (FBHP) | Возврат на узел с более высоким приоритетом (FBHP) |
| Таймер отсроченного возврата | ||
| Время установления | ||
| Политики времени выполнения | ||
| Политика динамического приоритета узла Порядок обработки (параллельная, последовательная или настраиваемая) | ||
| Сервисная IP-метка | app1svc | app2svc |
| Серверы приложений | app1 | app2 |
| Группы томов | app1vg | app2vg |
| Файловые системы | /app1 | /app2 |
| Проверка согласованности файловой системы | fsck | fsck |
| Метод восстановления файловой системы | Последовательный | Последовательный |
| Файловые системы или каталоги для экспорта | ||
| Файловые системы или каталоги для подключения NFS | ||
| Сеть для подключения NFS | ether10 | ether10 |
| Основной класс WLM | ||
| Автоматический импорт групп томов | Нет | Нет |
| Подключение файловых систем перед конфигурированием IP | Нет | Нет |
| КОММЕНТАРИИ | Обзор двух групп ресурсов | |
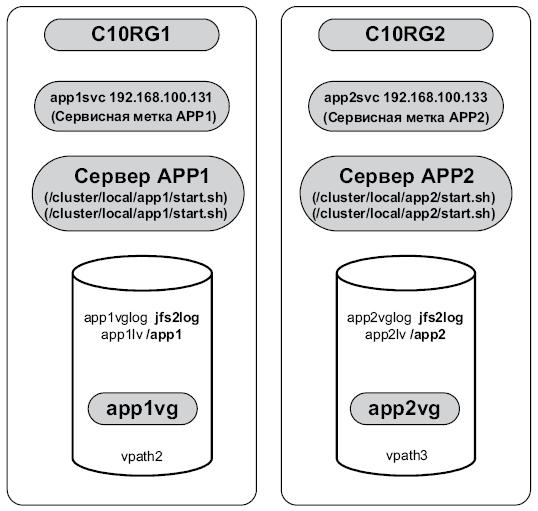
Подробная схема кластера
Собрав все вместе и используя информацию, собранную при планировании кластера и записанную в таблицах планирования, теперь можно перейти к построению простой для восприятия подробной схемы кластера. На рис. 3.21 представлена подробная схема кластера из нашего примера. Эту схему можно использовать в качестве вспомогательного средства при конфигурировании кластера и диагностике проблем.
Разработка плана тестирования кластера
Разработка соответствующего плана тестирования для проверки работы кластера при отказах так же важна, как и планирование и конфигурирование кластера HACMP. Другими словами, нужно проверить, соответствует ли обработка отказов кластером ожиданиям. Необходимо протестировать (или подтвердить) возможности восстановления кластера, прежде чем кластер станет частью рабочей среды.