Составляющие высокой доступности
Накопители на магнитной ленте
Некоторые накопители на магнитной ленте с подключением SCSI или Fibre Channel могут быть сконфигурированы как ресурсы высокой доступности в составе любой группы ресурсов (кроме concurrent).
Ресурсы Fast Connect
Сервер приложений Fast Connect не требует конфигурирования скриптов запуска и остановки, так как они уже интегрированы в HACMP. После конфигурирования Fast Connect в качестве ресурса HACMP система HACMP начинает поддерживать запуск, остановку, перемещение при сбое, возврат после восстановления и восстановление служб Fast Connect. Службы Fast Connect не могут выполняться в кластере в момент его старта, так как HACMP требуется осуществлять управление Fast Connect.
Если сконфигурирован перехват IP-адреса и аппаратного адреса, клиентам не требуется повторно устанавливать свое подключение.
Интеграция с WLM
Диспетчер рабочей нагрузки (workload manager, WLM) представляет собой инструмент администрирования ресурсов AIX, позволяющий устанавливать целевые значения и ограничения по использованию процессора, физической памяти и пропускной способности дискового ввода-вывода для приложений и пользователей. Могут быть сконфигурированы WLM-классы, каждому из которых соответствует определенный набор системных ресурсов. Затем определяются правила назначения приложений или групп пользователей классу и, таким образом, набор используемых ими ресурсов.
Применяя конфигурацию HACMP, WLM запускается либо при подключении узла к кластеру, либо в результате использования WLM системой DARE, и только на узлах, входящих в группы ресурсов, содержащие классы WLM. HACMP работает с WLM двумя способами:
- если WLM уже выполняется, HACMP сохраняет работающую конфигурацию, останавливает WLM и выполняет перезапуск с файлами конфигурации HACMP. Когда HACMP останавливается на узле, активизируется предыдущая конфигурация WLM;
- если WLM не выполняется, он запускается с конфигурацией HACMP и останавливается, когда HACMP останавливается на узле.
Внимание! HACMP может выполнять только ограниченную проверку конфигурации WLM. Необходимо заранее выполнить надлежащее планирование.
Конфигурация, используемая WLM на узле, настраивается отдельно для каждого узла и групп ресурсов, которые могут быть переведены в подключенный режим на этом узле. Классы диспетчера нагрузки могут быть назначены группам ресурсов как:
При интеграции узла в кластер HACMP выполняет проверку каждой группы ресурсов, соответствующей данному узлу в списке узлов. Используемые классы WLM зависят от политики запуска для каждой группы ресурсов и приоритета узлов в списке узлов.
Основной класс WLM
Если политика группы ресурсов предусматривает ее запуск либо только на домашнем узле (online on home node only), либо на первом доступном узле (online on first available node), то:
- если узел имеет наивысший приоритет в списке узлов, используется основной класс WLM;
- если узел не является узлом с наивысшим приоритетом и не определен дополнительный класс WLM, узел использует основной класс WLM;
- если узел не является узлом с наивысшим приоритетом и определен дополнительный класс WLM, узел использует дополнительный класс WLM.
Если группа ресурсов имеет политику запуска либо для подключенного режима на всех доступных узлах (online on all available nodes, одновременный доступ), либо для подключенного режима с использованием политики распределения узлов (online using a node distribution policy), то узел применяет основной класс WLM.
Дополнительный класс WLM
Является необязательным и используется только на узлах, не являющихся основными узлами для групп ресурсов с политикой запуска либо только на домашнем узле, либо на первом доступном узле.
Группы ресурсов
Для обеспечения высокой доступности в HACMP каждый ресурс должен быть включен в группу ресурсов (resource group, RG). Группы ресурсов позволяют HACMP осуществлять управление соответствующим набором ресурсов как единым объектом. Например, приложение может содержать скрипты запуска и остановки, базу данных и IP-адрес. Эти ресурсы включаются в группу ресурсов, которой HACMP управляет как единым объектом.
HACMP обеспечивает высокую доступность групп ресурсов путем их перемещения с узла на узел при изменении состояния кластера. Существуют следующие основные состояния кластера и соответствующие им действия групп ресурсов:
- Запуск кластера. Узлы кластера стартуют, и после этого группы ресурсов распределяются по ним в соответствии с политикой запуска.
- Отказ/восстановление ресурса. Когда определенный ресурс, являющийся частью группы ресурсов, становится недоступным, группу ресурсов можно переместить на другой узел. Подобным образом можно выполнить ее обратное перемещение, когда ресурс становится доступным.
- Завершение работы HACMP на узле. Существует множество способов остановить HACMP на узле. Один метод вызывает перемещение групп ресурсов узла на другие узлы. Другой метод переводит группы ресурсов в отключенный режим. При определенных обстоятельствах можно остановить службы кластера на узле, оставив ресурсы активными.
- Отказ/восстановление узла. При отказе узла группы ресурсов, которые были активными на узле, распределяются по другим узлам в кластере, в зависимости от их политик распределения перемещения при сбое. После восстановления узла и его реинтеграции в кластер группы ресурсов могут быть снова перемещены на него, в зависимости от политик перемещения при восстановлении.
- Завершение работы кластера. После завершения работы кластера все группы ресурсов переводятся в отключенный режим. Однако существует несколько конфигураций, при которых ресурсы могут остаться активными, но ресурсы кластера останавливаются.
Прежде чем разбирать режимы работы и атрибуты, конфигурируемые для групп ресурсов, необходимо рассмотреть следующие термины:
- Список узлов (node list). Представляет перечень узлов, способных содержать определенную группу ресурсов. Каждый узел должен быть способен получить доступ к ресурсам, составляющим группу ресурсов.
- Приоритет узла по умолчанию (default node priority). Представляет порядок, в котором узлы определяются в группе ресурсов. При отказе узлов группа ресурсов с атрибутами по умолчанию будет перемещаться с узла на узел в этом порядке.
- Домашний узел (home node). Узел с наивысшим приоритетом в списке узлов по умолчанию. По умолчанию указывает на узел, на котором группа ресурсов будет изначально активизироваться. Под этим термином не подразумевается узел, на котором группа ресурсов активна в данный момент.
- Запуск (startup). Процесс перевода группы ресурсов в подключенное состояние (online).
- Перемещение при сбое (fallover). Процесс перемещения группы ресурсов, находящейся в подключенном состоянии, с одного узла на другой узел в кластере в ответ на событие.
- Возврат после восстановления (fallback). Процесс перемещения группы ресурсов, находящейся в подключенном состоянии, с узла, не являющегося ее домашним узлом, на узел, для которого выполняется реинтеграция.
Режимы работы группы ресурсов-политики и атрибуты
Работа группы ресурсов определяется путем конфигурирования политик и режимов работы группы ресурсов. Ранние версии HACMP (до 5.1) поддерживали три предопределенные группы ресурсов:
-
Каскадные группы ресурсов (cascading). Изначально предназначались для
того, чтобы группы ресурсов имели сродство (affinity) с определенным узлом –
имели преимущество запуска на этом узле и осуществляли возврат после восстановления, когда он снова становится доступным. Режим работы может контролироваться сочетанием трех атрибутов:
- Переход при неактивности (Inactive takeover, ITO). Управляет переводом группы ресурсов в подключенное состояние узлами, отличными от узла с наибольшим приоритетом в списке узлов группы ресурсов.
- Каскадирование без возврата после восстановления (Cascading without fallback, CWOF). Определяет, возможен ли переход группы ресурсов на узел с более высоким приоритетом при его интеграции в кластер.
- Динамический приоритет узла (Dynamic Node Priority, DNP). Соответствует такому же атрибуту в настраиваемых группах ресурсов (custom resource groups).
- Ротационные группы ресурсов (rotating). Позволяют осуществлять распределение групп ресурсов по узлам в кластере. При запуске узла он пытается запустить все неактивные ротационные группы ресурсов, для которых он является узлом с наивысшим приоритетом5Другими словами, ротационная группа ресурсов запускается на первом доступном узле в кластере, а каскадная (без атрибута ITO) дожидается запуска своего домашнего узла. . При интеграции другого узла в кластер активные ротационные группы ресурсов не перемещаются. При наличии нескольких ротационных групп ресурсов в кластере приоритет узла определяется порядком узлов в списке узлов. При подключении каждого узла к кластеру на него перемещается ротационная группа ресурсов, для которой он является узлом с наивысшим приоритетом. Если количество групп ресурсов превышает количество узлов, в подключенный режим переводятся дополнительные группы ресурсов. Если не определено несколько сетей HACMP, то каждый узел получает по одной группе ресурсов для каждой сети.
- Группы ресурсов с одновременным доступом (concurrent). Предназначены для приложений с одновременным доступом (работающих в параллельном режиме) – группа ресурсов активна на каждом узле из списка узлов; она переходит в отключенный режим на узле, на котором возникают проблемы, и переходит в подключенный режим на узле, интегрируемом в кластер.
Настраиваемые группы ресурсов
Что в действительности важно для проектировщиков и администраторов HACMP, так это работа групп ресурсов при запуске, перемещении при сбое и возврате после восстановления. HACMP 5.1 поддерживает и "настраиваемые" (custom), и "классические" группы ресурсов, однако начиная с версии 5.2 доступны только "настраиваемые" группы ресурсов. Существуют следующие опции работы настраиваемых групп ресурсов.
Опции запуска (startup options)
Эти опции контролируют работу группы ресурсов при первом запуске.
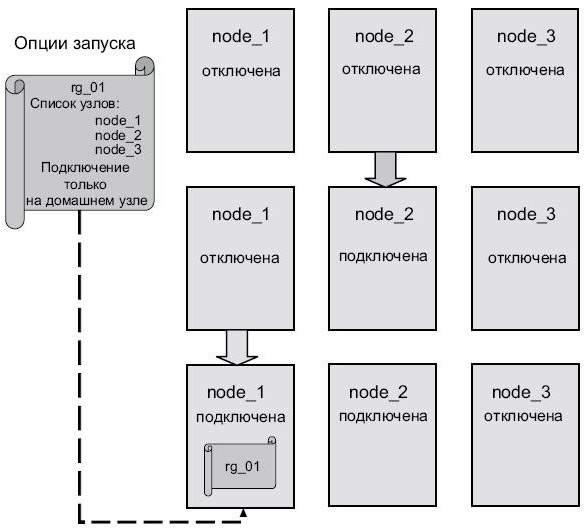
- Подключение только на домашнем узле (online on home node only). Группа ресурсов переводится в подключенный режим, когда ее домашний узел подключается к кластеру. Если домашний узел недоступен, группа ресурсов будет находиться в отключенном состоянии, пока он не будет доступен ( рис. 2.15).
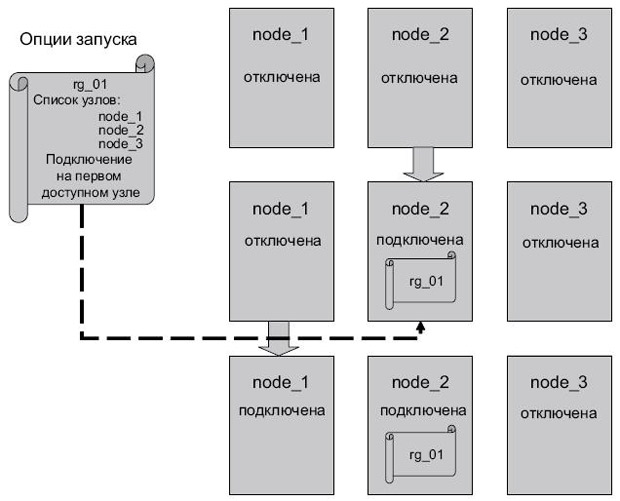
- Подключение на первом доступном узле (online on first available node). Группа ресурсов переводится в подключенный режим при подключении первого узла из списка узлов к кластеру ( рис. 2.16).
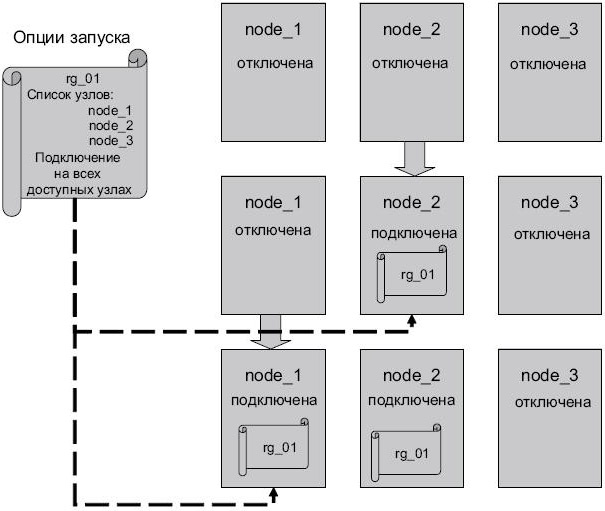
- Подключение на всех доступных узлах (online on all available nodes). Группа ресурсов будет подключена на всех узлах из списка узлов при их подключении к кластеру ( рис. 2.17).
- Подключение с использованием политики распределения (online using distribution policy). Группа ресурсов подключается, только если на узле не подключена другая группа ресурсов такого же типа.
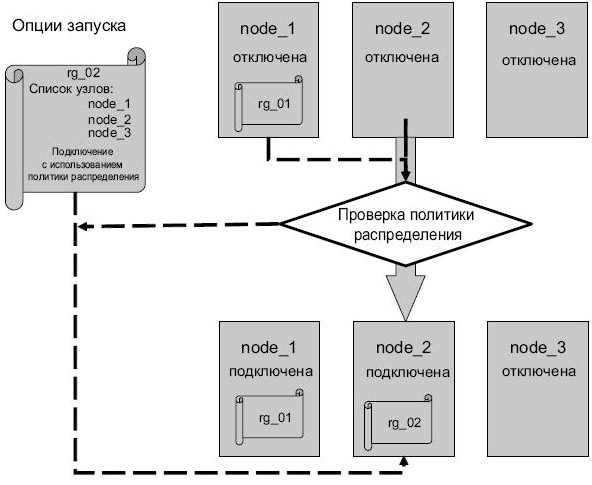
Если при подключении узла к кластеру существует несколько групп ресурсов такого типа, HACMP выбирает группу ресурсов с меньшим количеством узлов в списке узлов. Если этот показатель одинаков для всех групп ресурсов, HACMP выбирает первый узел в алфавитном порядке. Однако если один из узлов имеет зависимую группу ресурсов (т. е. является родительским объектом в отношениях зависимости), он будет иметь приоритет ( рис. 2.18).
Опции перемещения при сбое (fallover options)
Эти опции контролируют работу группы ресурсов, если HACMP придется переместить ее на другой узел в ответ на событие.
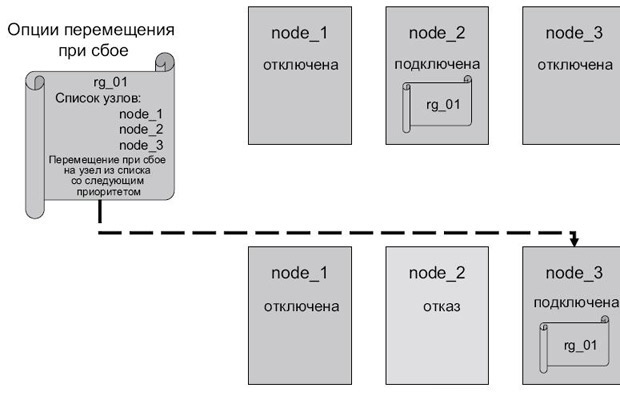
- Перемещение при сбое на узел из списка со следующим приоритетом (fallover to next priority node in list). Группа ресурсов выполняет перемещение при сбое на следующий узел в списке узлов группы ресурсов ( рис. 2.19).
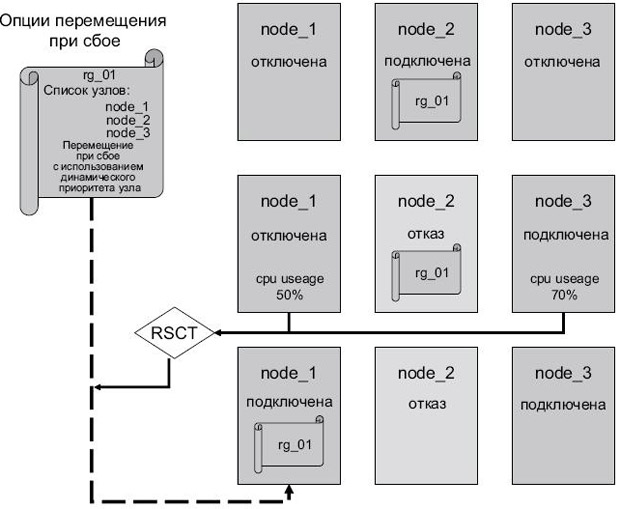
- Перемещение при сбое с использованием динамического приоритета узла (fallover using dynamic node priority). Узел, на который выполняется перемещение, может быть выбран на основе доступности процессора, доступности памяти или наименьшего использования дисков. HACMP применяет RSCT для сбора данных по выбранному показателю со всех узлов в списке узлов, после чего осуществляется перемещение группы ресурсов на узел, который лучше всего соответствует критериям ( рис. 2.20).
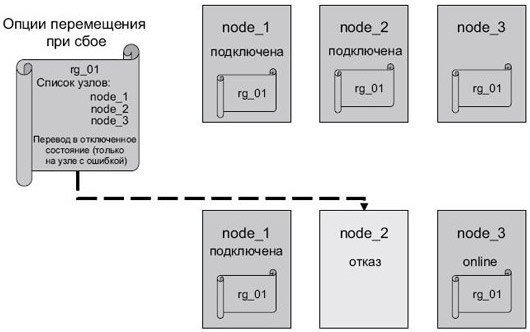
- Перевод в отключенное состояние (только на узле с ошибкой) [Bring offline (on error only)]. В случае ошибки группа ресурсов переводится в отключенное состояние. Эта опция предназначена для групп ресурсов с подключением на всех доступных узлах ( рис. 2.21).
Опции возврата после восстановления (Fallback options)
Эти опции контролируют работу подключенной группы ресурсов при подключении узла к кластеру.
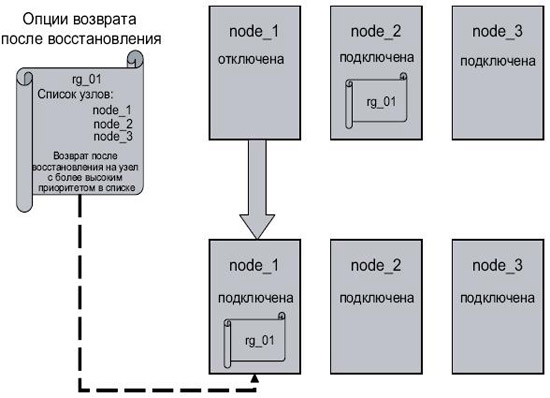
- Возврат после восстановления на узел с более высоким приоритетом в списке (fallback to higher priority node in list). Группа ресурсов осуществляет возврат после восстановления на узел с более высоким приоритетом при его подключении к кластеру ( рис. 2.22).
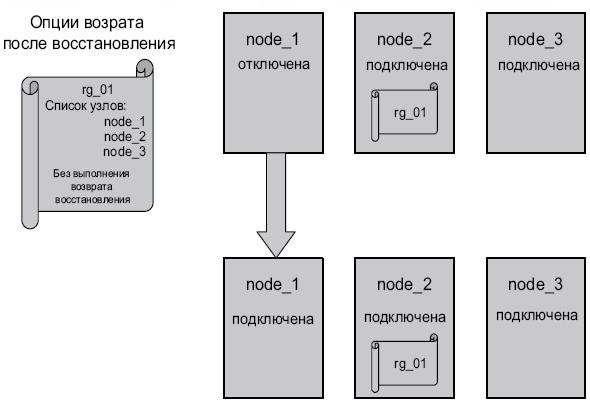
- Без выполнения возврата после восстановления (never fallback). Группа ресурсов не переносится на узел с более высоким приоритетом при его подключении к кластеру. Эта опция должна использоваться в группах ресурсов с подключением на всех доступных узлах. См. рис. 2.23
Примечание. ITO – Inactive takeover (Переход при неактивности); CWOF – Cascading without fallback (Каскадирование без возврата после восстановления); DNP – Dynamic Node Priority (Динамический приоритет узла).
Табл. 2.4 показывает соответствие опций запуска, перемещения при сбое и возврата после восстановления оригинальным каскадным группам ресурсов, ротационным группам ресурсов и группам ресурсов с одновременным доступом.
Атрибуты группы ресурсов
Работу группы ресурсов можно настроить с использованием таких атрибутов группы ресурсов, как:
- время установления (settling time);
- таймеры отсроченного возврата после восстановления (delayed fallback timers);
- политика распределения (distribution policy);
- динамические приоритеты узлов (dynamic node priorities);
- порядок обработки групп ресурсов (resource group processing order);
- расположение, отменяющее приоритет (Priority override location);
- зависимости групп ресурсов – отношения "родительский объект/дочерний объект" (resource group dependencies – parent/child);
- зависимости групп ресурсов – расположение (resource group dependencies – location).
Время установления (settling time)
Представляет собой атрибут кластера, влияющий на работу групп ресурсов с политикой запуска, настроенной на подключение на первом доступном узле. Если атрибут не установлен, эти группы ресурсов запускаются на первом узле в группе ресурсов, интегрируемом в кластер. Если время установления для группы ресурсов определено, и узел, интегрируемый в кластер, является узлом с наивысшим приоритетом, группа ресурсов подключается немедленно, в противном случае выполняется ожидание в течение времени установления на случай, если подключится другой узел с более высоким приоритетом.
Это позволяет предотвратить запуск группы ресурсов на первом подключенном узле с низким приоритетом с последующим перемещением на узлы с более высоким приоритетом по мере их подключения.
Таймеры отсроченного возврата после восстановления (delayed fallback timers)
Используются для настройки времени, в которое следует выполнить возврат группы ресурсов. Может быть задано либо выполнение в заданный день и время, либо выполнение в определенное время ежедневно, еженедельно, ежемесячно или ежегодно.
Таймер отсроченного возврата после восстановления обеспечивает возврат группы ресурсов на узел с наивысшим приоритетом в определенное время. Это обеспечивает возникновение небольшого перерыва в обслуживании в удобное для пользователей время. При этом ресурс не должен находиться на узле с наивысшим приоритетом.
Политика распределения (distribution policy)
Политика распределения на основе узлов обеспечивает "подхват" каждым узлом при запуске только одной группы ресурсов с заданным набором политик.
В HACMP 5.2 была реализована также политика распределения на основе сетей, которая обеспечивала подключение только одной группы ресурсов в одной сети и на одном узле, так что узлы с несколькими сетями могли содержать несколько групп ресурсов одного типа.
Динамический приоритет узла (dynamic node prioritiy)
При наличии трех и более узлов в кластере можно осуществлять настройку политики динамического приоритета узла. Для определения того, на какой узел следует переместить группу ресурсов, можно выбрать один из трех показателей:
- максимальный показатель свободной памяти;
- максимальный показатель бездействия процессора;
- минимальная нагрузка на диск.
Диспетчер кластера ведет таблицу значений этих показателей для каждого узла в кластере. Так что на момент перемещения при сбое диспетчер кластера может быстро определить, какой узел лучше всего соответствует требуемым критериям. Эти значения обновляются каждые 2 мин., если только не отсутствует доступ к узлу; в этом случае предыдущие значения остаются без изменений.
Важно! При определении максимального показателя свободной памяти HACMP вычисляет показатель используемой виртуальной памяти, а не показатель применяемой физической памяти.