Шаблоны
14.1. Пример шаблона: hello, world
Листинг 14.1 XUL-документ, содержащий простейший шаблон, выводящий "hello, world" один или несколько раз.
<?xml version="1.0"?> <window xmlns="http://www.mozilla.org/keymaster/ gatekeeper/there.is.only.xul"> <vbox datasources="test.rdf" ref="urn:test:seqroot"> <template> <label uri="rdf:*" value="Content: rdf:http://www.example.org/Test#Data"/> </template> </vbox> </window>Листинг 14.1. XUL-приложение "hello, world", использующее технологию шаблонов.
Как видно из листинга, система шаблонов состоит из собственных тегов, подобных тегу <template>, и специальных атрибутов для других тегов, таких, как атрибут ref.
Mozilla предоставляет несколько типов синтаксиса правил, образующих систему запросов в шаблонах. В данном примере использовался простейший синтаксис: только одно правило, причем подразумеваемое. Оно гласит: обработать все сообщения конкретного контейнера RDF и сгенерировать XUL-контент, представляющий эти сообщения. Контейнер имеет URI urn:test:seqroot, а контент, представляющий сообщения, определяется тегом <label>. Обратите внимание, что и внутри, и снаружи тега шаблона <template> могут быть теги обычного типа, не относящиеся к системе шаблонов.
В листинге 14.2 приведен RDF файл, соответствующий структуре DRF графа, которую ожидает данный шаблон.
<?xml version="1.0"?>
<RDF xmlns:Test="http://www.example.org/Test#"
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#" >
<Description about="http://www.example.org/">
<Test:Container>
<Seq about="urn:test:seqroot">
<li resource="urn:test:welcome"/>
<li resource="urn:test:message"/>
</Seq>
</Test:Container>
<Description about="urn:test:welcome" Test:Data="hello, world"/>
<Description about="urn:test:message" Test:Data="This is a test"/>
</RDF>
Листинг
14.2.
Простейший пример RDF файла, использующего шаблон.
Данный файл RDF не имеет иных параметров, кроме тега <Seq>, имя ресурса которого использовалось в коде XUL-шаблона в листинге 14.1. Это унифицированное имя ресурса (URN) используется как стартовая точка шаблона. Test - пространство имен xmlns. Data и Container - специальные свойства (предикаты) имен в этом пространстве имен. Имена URN и URL вида "http://www.example.org/Test" одинаково искусственны. Никакого формального процесса для выбора имен нет; нужно просто придумать подходящие. Свойство Data также присутствует в теге <label> листинга 14.1, где оно указано со своим полным URL.
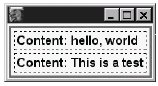
Если сохранить эти два листинга в файлы и загрузить первый, то мы увидим картинку, приведенную на рисунке 14.1. Диагностические стили включены, чтобы выявить структуру окна, полученного в результате.
На рисунке видно, что в финальном XUL были сгенерированы два тега <label>. Значения каждого тега определяются и фиксированным значением ("Content: "), и строкой, определяемой одним из двух фактов <Description> в документе RDF. Тег vbox, напротив, появляется лишь один раз. Структуру финального документа можно исследовать с помощью приложения DOM Inspector. На рисунке 14.2 приведен вид DOM Inspector, соответствующий рисунку 14.1.
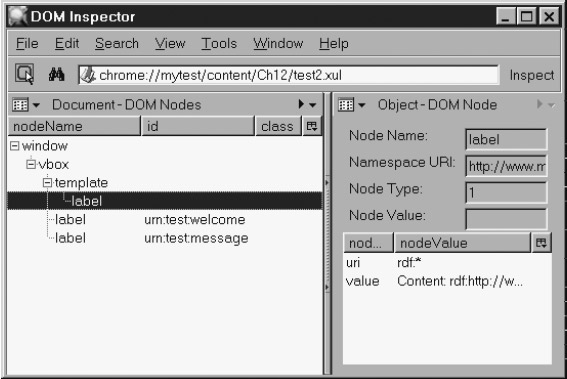
На снимке видно, что система шаблонов добавила два тега в финальный документ, по одному на каждый факт в файле RDF. Подсвеченный тег <label> - метка из исходного файла шаблона, другие два тега <label> - контент, сгенерированный шаблоном. Таким образом, финальный документ содержит два поддерева - одно для спецификации шаблона, а другое для сгенерированного контента. Поддерево, начинающееся тегом <template>, никак не отражается на внешнем виде документа. Когда система шаблонов генерирует теги для другого поддерева, она присваивает им ids, равные URN ресурса в соответствующем факте RDF.
XUL этого шаблона можно сделать гораздо сложнее, используя свойства системы правил шаблонов.
Перед тем, как углубиться в синтаксис XUL системы шаблонов, нам следует отступить далеко назад, чтобы увидеть, что все это означает с точки зрения фактов. В конце концов, шаблону для работы нужен RDF контент, а это подразумевает обработку фактов.
14.2. Понятие шаблона
Система шаблонов Mozilla затрагивает все стандартные отличительные черты приложений Mozilla: XUL, JavaScript и RDF. Она касается и работы с источниками данных. Эти ее свойства будут рассмотрены по очереди и затем сведены воедино на примере.
14.2.1. Запросы RDF и унификация
Система шаблонов XUL - это система запросов. Она осуществляет поиск в массиве данных и возвращает элементы массива, соответствующие спецификации запроса. Данные, по которым осуществляется поиск, - это множество фактов RDF. Запрос шаблона - часть процесса обработки, также имеющая дело с RDF.
Запросы, выполняемые XUL-шаблоном, часто описываются как система сравнивания с образцом. В самом общем смысле слова "образец", принятого в computer science, это верно, но сравнение с образцом имеет также и простой каждодневный смысл. Он употребляется, например, когда мы говорим о масках имени файла, как *.txt или о регулярных выражениях, таких как "^[a-zAZ]*66$". Такие инструменты, как командная строка, Perl, grep, vi, и даже JavaScript используют обычное сравнение с образцом, которое попросту очень напоминает фильтрацию. При простой фильтрации большой список элементов (или символов) сокращается.
Шаблоны XUL не являются фильтрами и не выполняют сравнение с образцом в этом каждодневном смысле слова. Если документ RDF содержит некое сообщение, XUL шаблон, обрабатывающий этот документ, должен не только принять или проигнорировать это сообщение. Запросы в шаблонах - это не просто фильтры.
В отличие от простой фильтрации, запросы в шаблонах выполняют унификацию. Унификация имеет место тогда, когда множество элементов данных комбинируется в конечный результат. Пример из реальной жизни - собирание паззла. Когда все кусочки паззла собраны вместе, решение найдено (получена картинка). Если дано больше элементов, чем нам понадобилось (предположим, было перемешано несколько наборов паззлов), часть элементов будут отброшены, как незначащие. Унификация может дать больше, чем один результат. Если элементов головоломки достаточно, можно собрать несколько картинок. Если элементы имеют подходящую форму, то несколько результатов может быть получено даже из одного набора.
В Mozilla элементы головоломки это подлежащие, сказуемые и дополнения набора RDF сообщений (фактов). Желаемый результат определен в запросе XUL шаблона. Любая комбинация элементов, удовлетворяющая спецификации запроса (правилам в шаблоне), будет найдена как новый порядок информации - новый кортеж. Если более одной комбинации элементов удовлетворяют запросу, будет образовано более одного нового кортежа.
Это кажется знакомым. Инструкция SELECT в SQL ведет себя точно так же, когда выполняет запрос join - то есть выбирает данные из двух или более таблиц. Данные в полученных колонках не соответствуют данным ни в одной из исходных строк, они соответствуют информации в строках разных таблиц. Этим способом может быть обнаружено более одной строки.
Фактически, запросы XUL-шаблонов являются примерами реляционных вычислений, так же как запросы SQL - примеры реляционной алгебры. Исследователи в университетах показали, что оба реляционных подхода - по сути одно и то же, хотя программируются по-разному и имеют мало общего в синтаксисе.
Синтаксис шаблонов XUL необычен и лучше начинать не с него. Чтобы разобраться в структуре запросов шаблонов, давайте вернемся к примеру с мальчиком, собакой и мячиком из "RDF" , "RDF".
Вспомним, что этот пример использовался для описания "чистой" системы сообщений, без RDF или XML синтаксиса. Мы снова используем его здесь, чтобы привести пример "чистого" запроса и унификации сообщений. Пример сообщений из "RDF" , "RDF", повторяется в листинге 14.3.
<- 1, is-named, Tom -> <- 1, owner, 2 -> <- 1, plays-with, 5 -> <- 2, is-named, Spot -> <- 2, owned-by, 1 -> <- 2, plays-with, 5 -> <- 5, type-of, tennis -> <- 5, color-of, green ->Листинг 14.3. Предикатные триплеты из примера о мальчике и собаке, лекция 11.
Эта информация моделирует сообщение "Том и его собака Спот играют с зеленым теннисным мячиком". Каждый элемент модели имеет идентификационный номер. Мы можем запрашивать это множество сообщений с помощью простых, или единичных (single-fact), либо множественных (multi-fact) запросов.
14.2.1.1. Простые (single-fact) запросы
В "RDF" , "RDF", мы видели, что бывают основные (от ground - основа) факты (и RDF документы). Основные факты - это хорошо, потому что каждая часть основного факта есть попросту литерал, без неизвестных. С литералами легко работать. Примеры неосновных фактов в "RDF" , "RDF", приводились также. Вот немного измененный, неосновной факт:
<- 1, owner, ??? ->
Поскольку дополнение (объект) в этом триплете неизвестно, это не основной факт. Его нельзя использовать как данные, но можно - как стартовую точку для запроса о других фактах. Используем переменную для неизвестной части. Переменная начинается с символа вопросительного знака, точно как переменные в DOS начинаются и заканчиваются знаком '%', а переменные в оболочке UNIX начинаются со знака '$'. Переменная не может быть в основном состоянии, иначе она не переменная, а литерал. Будем называть процесс перевода переменной с неизвестным значением в переменную с известным - обоснованием переменной.
<- 1, owner, ?dogId ->
При выполнении запроса унификация означает, что все переменные из множества доступных фактов будут преобразованы в литералы. Причудливым образом можно сказать так: "Обоснуй-ка мне все переменные, пожалуйста". Для нашего простого примера данному перегруженному переменными запросу отвечает второй факт из листинга 14.3.
<- 1, owner, 2 ->
Переменная ?dogId не имеет значения, и если значение 2 заменит ее, будет получен факт, соответствующий существующему факту. Таким образом, переменная ?dogId может быть обоснована значением 2. Это тривиальный пример запроса, возвращающего один результирующий факт. Предположим, у Тома есть вторая собака, по кличке Фидо. Значит, есть дополнительный факт:
<- 1, owner, 3 -> <- 3, is-named, Fido ->
Если факт, содержащий переменную ?dogId, снова использовать как запрос, ему будут соответствовать уже два факта:
<- 1, owner, 2 -> <- 1, owner, 3 ->
?dogId может быть обоснована либо значением 2, либо 3, так что теперь есть два решения. Мы можем говорить, что результирующее множество содержит два факта, две строки, или два элемента.
Предшествующий факт, используемый как запрос, также может быть расширен. Его можно указать так:
<- ?personId, owner, ?dogId ->
В этом случае соответствие требует комбинации значений, удовлетворяющих обеим переменным одновременно (обосновывается и ?personId, и ?dogId ). Если мы используем существующие факты, результирующее множество также будет иметь две строки: ( ?personId обосновывается 1 и ?dogId обосновывается 2) даст один факт, а ( ?personId обосновывается 1 и ?dogId обосновывается 3) даст второй. Увеличение количества переменных не всегда означает увеличение количества результирующих фактов. Это лишь означает, что нужно найти соответствие большему количеству предметов.
Предположим, что Джейн (чей person id = 4) также владеет Фидо, но не Спотом. Фидо, таким образом, принадлежит двум хозяевам, но Спотом владеет только Том. В списке фактов добавятся два новых:
<- 4, is-named, Jane -> <- 4, owner, 3 ->
Если последний запрос выполнить вновь, мы получим три результата:
?personId обосновывается 1 (Tom) and ?dogId обосновывается 2 (Spot) ?personId обосновывается 1 (Tom) and ?dogId обосновывается 3 (Fido) ?personId обосновывается 4 (Jane) and ?dogId обосновывается 3 (Fido)
Хотя ?personI может иметь значение 4 (Джейн), а ?dogId - 2 (Спот), результата это не даст, потому что такого факта (Джейн владеет Спотом) в списке фактов нет. Когда факт соответствует факту запроса, он ему соответствует целиком, а не частично.
Наконец, заметим, что информация, которую нужно обосновать в последнем простом запросе, имеет иную нотацию. Она может быть записана как набор неизвестных, которые нужно найти. Этот набор можно записать как кортеж. В этом примере кортеж - двойка, а не триплет. Этот кортеж может быть записан так:
<- ?personId, ?dogId ->
Этот кортеж еще не запрос. Он просто описывает, какие есть неизвестные и какие переменные будут найдены, когда запрос вернет результат. Это полезная информация для программиста, что-то подобное части INTO в SQL запросе SELECT. Если кто-то другой писал запрос, такая информация - все, что вам нужно, чтобы понять полученный результат.
В последнем примере три строки соответствуют этому кортежу:
<- 1, 2 -> <- 1, 3 -> <- 4, 3 ->
Кортеж из двух переменных аккуратно собирает всю неизвестную информацию вместе. Процессору запроса все еще нужна информация из хранилища фактов, соответствующая этой структуре. Вот почему запросы имеют полный синтаксис, использованный нами ранее.
Если процессору запросов не дать достаточно информации, он не будет знать, что ему делать. Недостаточно сказать, "компьютер, умница, найди-ка мне эти переменные". Запрос должен указать процессору, на что смотреть. В случае простого запроса предписание может быть очень простое: "комп, тупица, просмотри-ка все триплеты данных и найди все, соответствующие этому триплету-запросу".
Система шаблонов Mozilla поддерживает простые (single-fact) запросы. Простые запросы должны быть сформулированы с использованием расширенного синтаксиса запросов. Простые запросы не могут быть сформулированы с помощью простого синтаксиса.
Слегка заглядывая вперед, скажем, что в запросе о единичном факте тег <conditions> должен быть записан одним из двух способов. Если искомый факт содержится в RDF-контейнере с предикатами rdf:_1, rdf:_2 и так далее, то в теге <conditions> должны содержаться <content> и <member>. Если же искомый факт содержит хорошо известные предикаты, <conditions> должен содержать теги <content> и <triple>. Простые запросы шаблонов обсуждаются далее в разделе "Распространенные образцы запросов".
Резюме: простой запрос пытается обосновать запрашиваемый факт множеством реальных фактов. И если это получается, найденные основные, т.е. литеральные результаты называются решением запроса.
14.2.1.2. Комплексные (Multifact) запросы
Система XUL шаблонов поддерживает комплексные (multifact) запросы. Комплексные запросы напоминают SQL запрос join и также напоминают навигацию по древообразной структуре данных.
Комплексные запросы - это вопросы, требующие для ответа, чтобы два или более реальных факта были скомбинированы. Другими словами, требуется некая дедукция. Поддержка дедукции в Mozilla напоминает упрощенные вычисления предикатов в Прологе, за исключением того, что это подобие хорошо замаскировано синтаксисом. Сначала мы рассмотрим "чистые" комплексные запросы, а потом обратимся к XUL синтаксису.
Используя пример о мальчике и собаке, предположим, что нужно задать запрос: "Как зовут собаку, которой владеет Том"?
<- ?personId, is-named, Tom -> <- ?personId, owner, ?dogId -> <- ?dogId, is-named, ?dogName ->
Формулирование комплексных запросов требует некоторой практики. Это тот же вид практики, который требуется, чтобы освоить SQL запросы join для нескольких таблиц или регулярные выражения с несколькими переменными. Ключевая проблема состоит в том, что запрос приходится писать сразу, усилием воли, с чистого листа.
Данный запрос был построен следующим образом. Сначала было установлено уже нам известное ("Том"). Затем мы определили то, что нам не известно, но мы хотим узнать: dogName. Мы просмотрели доступные нам кортежи, чтобы узнать, каким из них могут соответствовать известные и неизвестные нам элементы. Это дало нам два кортежа, первый и третий в результирующем запросе. Глядя на эти кортежи, мы увидели, что некоторые предикаты обязательны: is-named используется в обоих кортежах. Чтобы полностью обосновать этот кортеж, нужно найти неизвестные (в данных кортежах это подлежащие), а именно personId и dogId. Мы добавили их в список неизвестных. Мы заметили, что эти два кортежа не имеют общих неизвестных, т.е. что они "не связаны". Мы снова просматриваем список известных кортежей, в поисках тех, которые могут их связать. Теперь мы обнаруживаем второй кортеж, связывающий personId и dogId. Итак, мы получаем список кортежей, где все неизвестные присутствуют, и все они соединены, так что этот список образует единый запрос.
Если эти три факта, как единый запрос, направить в процессор запросов, то, чтобы решение нашлось, все неизвестные должны быть обоснованы одновременно. Поскольку каждая из переменных ?personId и ?dogId присутствует в двух кортежах, любое значение, которое они могут принимать, должно удовлетворять обоим кортежам одновременно. Единственным возможным решением на массиве нам известных фактов может быть лишь следующее:
<- 1, is-named, Tom -> <- 1, owner, 2 -> <- 2, is-named, Spot ->
Сравните эти три факта с запросом. Решение ставит в соответствие неизвестным переменным
<- ?personId, ?dogId, ?dogName ->
единственную возможность:
<- 1, 2, Spot ->
Спот - искомое значение, остальные переменные использовались, только чтобы связать факты вместе. Теперь на вопрос получен ответ - имя собаки, которой владеет Том, Спот. Остальные переменные можно или исследовать далее, или проигнорировать. Этот комплексный запрос поясняет, почему говорят, что переменные должны быть "унифицированы" а не просто "найдены": чтобы найти решение, всем кортежам должны быть найдены соответствия одновременно.
Как процессор запросов в Mozilla ищет решение? Существует много возможных техник. Простейшая - перебирать все комбинации из трех реальных фактов и сравнивать каждую комбинацию с запросом. Это решение проблемы "грубой силой", оно очень неэффективно. Так в Mozilla не делается. Mozilla использует более тонкий метод, заключающийся в исследовании части графа структуры фактов. Скоро мы сможем в этом убедиться.
Если снова поместить в список исходных фактов Фидо и Джейн, тот же самый запрос даст два решения:
<- 1, is-named, Tom -> <- 1, owner, 2 -> <- 2, is-named, Spot -> <- 1, is-named, Tom -> <- 1, owner, 3 -> <- 3, is-named, Fido ->
Здесь значения, обосновывающие неизвестные переменные, следующие:
<- 1, 2, Spot -> <- 1, 3, Fido ->
Обратите внимание, как конструируется запрос для сравнения с фактами списка. Подлежащие и дополнения соответствуют переменным, таким как ?personId. Результат, напротив, просто набор обоснованных переменных в кортежах, по одному кортежу на решение. В данном случае у нас три переменные, поэтому кортеж является триплетом.
Этот пример эквивалентен SQL запросу join из трех таблиц. Листинг 14.4 показывает воображаемый SELECT запрос, выполняющий ту же работу, что и наш последний запрос. Каждая из трех воображаемых таблиц соответствуют одному факту из нашего списка.
SELECT p.personId, d.dogId, d.dogName FROM persons p, owners o, dogs d WHERE p.personName = "Tom" AND p.personId = o.personId AND o.dogId = d.dogIdЛистинг 14.4. SQL SELECT запрос, аналогичный комплексному запросу.
Точно как join в SQL-запросе связывает таблицы (реляционность), переменные в запросе о фактах связывают вместе факты. Сравните использование переменной personId в двух типах запросов, и вы увидите подобие, несмотря на абсолютно разный синтаксис.
В общем случае этот пример демонстрирует, как большой массив фактов может быть исследован с помощью правильно сконструированных запросов, содержащих переменные. Если массив фактов - это RDF документ, то шаблоны в Mozilla могут выполнять простые, но универсальные запросы на этом массиве.
Система шаблонов поддерживает комплексные шаблоны двумя способами. Простой синтаксис шаблона автоматически выполняет запрос по двум фактам, при условии, что RDF-данные организованы корректно. Расширенный синтаксис позволяет задавать комплексные запросы любой длины, соединяя вместе один тег <content>, любое количество тегов <member> и <triple>, и любое количество тегов <binding>. Каждый из этих тегов (за исключением тега <content> ) представляет в запросе один факт.