
|
Добрый день. Подскажите формулы при решении задачи на рис. 2.2 в лекции №2. Закон Ома, какие должны использоваться формулы для I и R |
Тверской государственный университет
Опубликован: 13.09.2006 | Доступ: свободный | Студентов: 5178 / 412 | Оценка: 4.23 / 3.83 | Длительность: 28:12:00
Специальности: Программист, Менеджер
Лекция 8:
Анализ деятельности офиса
Свойства и методы объекта PivotCache
У объекта PivotCache 23 свойства. Большинство из них я рассмотрю:
-
Connection - позволяет задать соединение с источником данных. Возвращает или устанавливает строку, имеющую разный синтаксис в зависимости от типа источника данных. Строка может задавать:
- OLE DB установки для связи Excel с OLE DB источниками данных,
- ODBC установки для связи Excel с ODBC источниками данных,
- URL, когда Excel связывается с данными Web-страниц,
- Полный путь, задающий текстовый файл или файл, задающий Web-запрос или базу данных.
Установка значения для свойства Connection не означает непосредственного соединения с источником данных. Необходимо вызывать метод Refresh, чтобы такая связь была в действительности установлена.ActiveWorkbook.PivotCaches.Add(SourceType:=xlExternal).Connection = _ "OLEDB; Provider=Microsoft.jet.oledb.4.0;" & _ "Data Source=c:\!O2000\DSCD\Ch18\dbPP2000.mdb"
- LocalConnection, UseLocalConnection - эти два свойства используются при работе с сохраненными в отдельном файле OLAP кубами. Когда в качестве источника данных используется OLAP куб, то вместо задания свойства Connection следует использовать свойство LocalConnection, предварительно установив значение True для свойства UseLocalConnection.
-
CommandType, CommandText - два хорошо знакомых по ADO свойства. Первое из них определяет тип команды, а второе значение команды, выполняющей запрос к источнику данных. Первое свойство может иметь четыре значения, заданное константами: xlCmdCube, xlCmdDefault, xlCmdSQL, xlCmdTable. В зависимости от установленного значения свойство CommandText задает:
- Имя куба для OLAP кубов,
- Текст команды, учитывающий специфику и требования провайдера,
- Текст SQL-запроса,
- Имя таблицы.
- MemoryUsed As Long - свойство имеет статус "только для чтения", возвращает количество байтов памяти занятой в текущий момент под кэш. Если объект PivotTable не присоединен к объекту PivotCache, то возвращается значение 0.
- OptimizeCache - булево свойство, при установке значения True, кэш будет оптимизироваться при его конструировании. Для OLE DB источников данных свойство имеет статус "только для чтения" и имеет значение по умолчанию - False.
- QueryType - свойство имеет статус "только для чтения", возвращает константу типа xlQueryType, которая определяет тип запроса, используемого Excel для заполнения кэша.
- Recordset - очень важное и полезное свойство при программной работе со сводными таблицами. Оно позволяет вернуть или установить хорошо знакомый объект Recordset, задающий набор записей, используемый при построении кэша. Тем самым появляется возможность программного создания и наполнения данными объекта PivotCache. Связь с источником данных можно организовать средствами ADO и получить объект Recordset. После чего остается только установить свойство объекта PivotCache. Зачастую, это более эффективный способ работы с источником данных. Пример такого способа работы будет приведен.
- RecordCount - как обычно, задает число записей в наборе Recordset.
- RefreshDate, RefreshName, RefreshOnFileOpen, RefreshPeriod - свойства, задающие различную информацию, связанную с обновлением данных.
Рассмотрим теперь методы объекта PivotCache. Их немного - всего три:
-
Function CreatePivotTable(TableDestination, [TableName], [ReadData]) As PivotTable. Этот метод (функция) создает объект PivotTable, основанный на данном кэше - объекте PivotCache. Это основной способ создания и появления объектов PivotTable.
- Аргумент TableDestination представляет объект Range, задающий область построения сводной таблицы. Аргумент задает ячейку в левом верхнем углу этой области. Напомню, что объект PivotTable связан с определенным листом рабочей книги, поэтому аргумент должен определять и нужный рабочий лист, в противном случае будет выбран активный лист рабочей книги.
- Аргумент TableName задает имя сводной таблицы - имя объекта PivotTable, которым можно пользоваться при работе с коллекцией PivotTables.
- Булев аргумент ReadData позволяет установить способ чтения записей в кэш. Он имеет значение True, если в кэш читаются все записи.
- Sub Refresh(). Обновляет кэш текущим состоянием источника данных.
- Sub ResetTimer(). Восстанавливает значение таймера. Это может быть важно, когда используется свойство RefreshPeriod, задающее период времени между последующими обновлениями источника данных.
На этом я закончу рассмотрение свойств и методов объекта PivotCache. Примеры создания этого объекта приведу чуть позже, после рассмотрения объекта PivotTable, поскольку создавать эти объекты, тесно связанные между собой, следует в одной процедуре.
Объект PivotTable и коллекция PivotTables
Если коллекция PivotCaches связана с рабочей книгой, то коллекция PivotTables связана с отдельным листом этой книги. Коллекция PivotTables возвращается при вызове одноименного свойства объекта Worksheet. Обе коллекции устроены одинаково и имеют один и тот же набор свойств и методов. У коллекции PivotTables имеются следующие свойства: Application, Count, Creator, Parent. У нее есть также два метода - Item и Add. Из всего этого набора заслуживает рассмотрения только метод Add, позволяющий создать новый объект. Вот его синтаксис:
Function Add(PivotCache As PivotCache, TableDestination, [TableName], [ReadData]) As PivotTable
Чуть выше я рассматривал, как основной способ создания объектов PivotTable, вызов метода CreatePivotTable объекта PivotCache. Я называл этот способ основным по той причине, что создание кэша не является самоцелью, - это не самостоятельный объект. Всегда он создается для того, чтобы связать с ним отчет сводной таблицы - объект PivotTable. Поэтому разумно, создав объект PivotCache тут же вызвать его метод CreatePivotTable, чтобы создать и объект PivotTable.
Тем не менее, для создания объекта PivotTable есть возможность использовать метод Add коллекции PivotTables. Он выполняет ту же работу, что и метод CreatePivotTable, и имеет тот же набор аргументов. Дополнительно, в качестве первого аргумента, естественно, указывается объект PivotCache, на основе которого создается объект PivotTable.
Чуть позже я приведу примеры, где будет показано применение обоих способов создания объекта PivotTable.
Свойства и методы объекта PivotTable
Объект PivotTable, задающий отчет сводной таблицы - его внешнее представление устроен, естественно, более сложно. У него значительно больше свойств, чем у объекта PivotCache, - их 54, да и методов в четыре раза больше. Замечу, что для программного создания сводной таблицы достаточно использовать лишь малую часть из этого набора. Большая часть этих свойств и методов необходима, если Вы хотите программно поддерживать работу пользователя со сводной таблицей.
Давайте рассмотрим основные свойства этого объекта:
- ColumnFields([Index]) As Object, DataFields([Index]) As Object, PageFields([Index]) As Object, RowFields([Index]) As Object. Все эти свойства имеют статус "только для чтения" и возвращают коллекцию или отдельный элемент коллекции, если указан индекс. Возвращаемые объекты задают поля сводной таблицы по соответствующему измерению - поля столбцов, данных, страниц или строк. Вне зависимости от измерения все возвращаемые объекты принадлежат единому классу PivotField или PivotFields для коллекций.
-
ColumnRange, DataLabelRange, DataBodyRange, PageRange, RowRange - возвращают объект Range, задающий соответствующую область. Вот простенькая процедура, поочередно выделяющая указанные области сводной таблицы:
Public Sub SelectRange() ThisWorkbook.Worksheets("Лист1").Activate Range("A3").Select ActiveCell.PivotTable.ColumnRange.Select ActiveCell.PivotTable.DataLabelRange.Select ActiveCell.PivotTable.DataBodyRange.Select ActiveCell.PivotTable.PageRange.Select ActiveCell.PivotTable.RowRange.Select End Sub - ColumnGrand, RowGrand - булевы свойства, имеющие значение True, если сводная таблица подводит итоги по столбцам и строкам.
- CubeFields - для сводных таблиц, основанных на OLAP кубе, возвращает одноименную коллекцию, задающую поля куба. Каждый объект этой коллекции содержит свойства поля.
- HiddenFields([Index]) As Object, VisibleFields([Index]) As Object - коллекции спрятанных и видимых полей. Для сводных таблиц, основанных на OLAP кубах спрятанных полей нет - все поля являются видимыми.
- ErrorString As String, DisplayErrorString As Boolean. Первое из свойств позволяет задать строку, представляющую сообщение об ошибке, второе - позволяет включить или отключить появление этой строки в вычисляемых полях, где возникает ошибка.
- PivotFormulas As PivotFormulas - возвращает одноименную коллекцию объектов. Каждый элемент этой коллекции является объектом класса PivotFormula и представляет формулу, используемую в вычисляемых полях.
На этом я закончу рассмотрение свойств и перейду к рассмотрению методов:
- Function AddFields([RowFields], [ColumnFields], [PageFields], [AddToTable]). Позволяет добавить поля к соответствующему измерению. Последний булев параметр позволяет указать, будут ли поля добавляться или заменять существующий набор полей. В предыдущей версии
- Function CalculatedFields() As CalculatedFields. Возвращает одноименную коллекцию вычисляемых полей.
- Sub Format(Format As xlPivotFormatType). Производит форматирование сводной таблицы. Аргумент Format задает один из возможных типов форматирования.
- Function GetData(Name As String) As Double. Позволяет получить данные из отдельной ячейки сводной таблицы. Аргумент Name задает поля таблицы, однозначно определяющие ячейку. Он имеет достаточно сложный синтаксис, на деталях которого останавливаться не буду.
- Function PivotCache() As PivotCache - возвращает объект PivotCache, связанный с отчетом.
- Function PivotFields([Index]) As Object - возвращает одноименную коллекцию, а при указании индекса элемент этой коллекции, задающий поле сводной таблицы. В качестве индекса можно использовать имя поля. Возвращаемые объекты принадлежат классу PivotField. Позже в примере я продемонстрирую работу с этими объектами при программном формировании структуры сводной таблицы.
- Sub PivotTableWizard([SourceType], [SourceData], [TableDestination], [TableName], [RowGrand], [ColumnGrand], [SaveData], [HasAutoFormat], [AutoPage], [Reserved], [BackgroundQuery], [OptimizeCache], [PageFieldOrder], [PageFieldWrapCount], [ReadData], [Connection]). Этим методом, но не в виде процедуры, а в виде функции обладает и объект Worksheet. Вызванный этим объектом метод позволяет создать объект PivotTable. В предыдущих версиях Office этот способ был основным для создания подобных объектов. Теперь надобность в нем практически отпала. Метод моделирует работу Мастера сводных таблиц и имеет многочисленные аргументы, позволяющие определить сводную таблицу. Поскольку, как я сказал, теперь не следует пользоваться этим методом, то я не буду останавливаться на деталях его описания.
- Function RefreshTable() As Boolean - обновляет данные сводной таблицы и возвращает значение True, если обновление прошло удачно.
- Function ShowPages([PageField]) - создает новый отчет для каждого элемента в поле страниц. Каждый отчет создается на отдельной странице.
Два способа создания объектов PivotCache и PivotTable
Я уже говорил, что объекты PivotCache и PivotTable можно создавать несколькими способами, и рассмотрел методы, используемые в этих способах. Теперь пришла пора привести соответствующие процедуры, решающие эти задачи. Я приведу две процедуры, в каждой из которых создаются оба эти объекты, но в каждой из них это делается по-разному. Вот код первой из этих процедур:
Public Sub CreatePivotCacheAndTable()
'Создание объекта PivotCache
'и на его основе - объекта PivotTable
'при заполнении данными используются
'свойства объекта: Connection,CommandText,CommandType
Dim myCache As PivotCache
Dim DbDir As String, DbPath As String
DbDir = ThisWorkbook.Path
DbPath = DbDir & "\dbPP2000.mdb"
Set myCache = ThisWorkbook.PivotCaches.Add(xlExternal)
With myCache
.Connection = "OLEDB; Provider=Microsoft.jet.oledb.4.0;" & _
"Data Source=" & DbPath
.CommandType = xlCmdSql
.CommandText = _
"SELECT Заказано.НазваниеКниги, Заказано.Стоимость, " & _
"Заказано.Количество, " & "Заказы.Заказчик, Заказы.Сотрудник, " & _
"Заказы.ДатаЗаказа" & Chr(13) & "" & Chr(10) & _
"FROM `C:\!O2000\DsCd\Ch18\dbPP2000`.Заказано Заказано, " & _
"`C:\!O2000\DsCd\Ch18\dbPP2000`.Заказы Заказы" & _
Chr(13) & "" & Chr(10) & _
"WHERE Заказано.КодЗаказа = Заказы.КодЗаказа"
'Создать отчет сводной таблицы
With ThisWorkbook.Worksheets("Лист1")
.Activate
If .PivotTables.Count > 0 Then
'Очистить область сводной таблицы
ClearRegion
End If
End With
.CreatePivotTable TableDestination:=Range("A3"), _
TableName:="Анализ продаж"
End With
End SubОбратите внимание, как создается объект PivotCache, - вначале он добавляется в коллекцию методом Add, но при этом объект не связан еще ни с каким источником данных и, следовательно, данных не содержит. На следующем этапе при заполнении свойств этого объекта - Connection, CommandType и CommandText - осуществляется связь с источником данных и выполняется команда, задающая запрос на получение данных. Соответствующий участок текста процедуры подсвечен.
Так кэш становится заполненным. После этого, к нему можно привязать и отчет сводной таблицы. В данном варианте для построения объекта PivotTable используется метод CreatePivotTable объекта PivotCache.
Заметьте, нельзя размещать сводную таблицу в области уже занятой другой сводной таблицей. По этой причине в процедуре проводится соответствующая проверка и область очищается, если она была занята. Приведу текст вызываемой процедуры ClearRegion:
Public Sub ClearRegion() Dim myr As Range Set myr = ActiveSheet.UsedRange myr.Clear End Sub
Надеюсь, она не требует особых пояснений. Напомню лишь, что свойство UsedRange возвращает всю область, занятую на рабочем листе. Эта область и очищается.
Давайте рассмотрим теперь другой способ создания объектов PivotCache и PivotTable. Приведу код процедуры для этого варианта:
Public Sub CreatePivotCacheAndTableWithADO()
'Создание объекта PivotCache
'и на его основе - объекта PivotTable
'Связь с базой данных осуществляется с использованием
'объектов ADO: Connection,Command,Recordset
'Объект Recordset является основой для построения кэша
Dim myCache As PivotCache
'Соединение с базой данных и получение набора записей
CreateRecordset
Set myCache = ThisWorkbook.PivotCaches.Add(xlExternal)
With myCache
Set .Recordset = Rst1
'Создать отчет сводной таблицы
With ThisWorkbook.Worksheets("Лист1")
.Activate
If .PivotTables.Count > 0 Then
'Очистить область сводной таблицы
ClearRegion
End If
.PivotTables.Add PivotCache:=myCache, _
TableDestination:=Range("A3"), _
TableName:="Анализ продаж"
End With
End With
End SubВ этом варианте построения кэша сводной таблицы за доставку данных от источника данных в программу отвечают хорошо нам знакомые объекты ADO. Этот вариант имеет несомненные достоинства, поскольку объекты ADO обеспечивают эффективную доставку данных и, что не менее важно, способны получать данные из самых разнообразных источников данных, которые теперь можно использовать для построения сводных таблиц.
Работа с объектами ADO заканчивается построением объекта Recordset, задающего набор записей. Теперь остается ссылку на этот объект сделать значением одноименного свойства объекта PivotCache.
Так кэш становится заполненным. После этого, к нему можно привязать и отчет сводной таблицы. В данном варианте для построения объекта PivotTable используется метод Add коллекции PivotTables.
Чтобы закончить рассмотрение, остается привести текст вызываемых процедур CreateConnection и CreateRecordset:
Public Sub CreateConnection() 'Создание соединения с тестовой базой данных Access Dim strConnStr As String If Con1.State = adStateOpen Then Con1.Close 'закрыть соединение 'Конфигурирование соединения Con1 Con1.Provider = "Microsoft.jet.oledb.4.0" Con1.ConnectionString = "Data Source=c:\!O2000\DsCd\Ch14\dbPP2000.mdb" Con1.CursorLocation = adUseClient 'Открытие соединения Con1.Open End Sub Public Sub CreateRecordset() 'Связывание с базой данных Access 'получение набора записей Dim strSQL1 As String 'Задание SQL оператора strSQL1 = _ "SELECT Заказано.НазваниеКниги, Заказано.Стоимость, " & _ "Заказано.Количество, " & "Заказы.Заказчик, Заказы.Сотрудник, " & _ "Заказы.ДатаЗаказа" & Chr(13) & "" & Chr(10) & _ "FROM `C:\!O2000\DsCd\Ch18\dbPP2000`.Заказано Заказано, " & _ "`C:\!O2000\DsCd\Ch18\dbPP2000`.Заказы Заказы" & _ Chr(13) & "" & Chr(10) & _ "WHERE Заказано.КодЗаказа = Заказы.КодЗаказа" CreateConnection 'задание свойств объекта Command Cmd1.ActiveConnection = Con1 Cmd1.CommandText = strSQL1 Cmd1.CommandType = adCmdText Cmd1.Prepared = True 'вызов команды на исполнение методом Execute Set Rst1 = Cmd1.Execute End Sub
Процедуры CreateConnection и CreateRecordset нам хорошо знакомы, - их аналоги уже появлялись в главе 15 при рассмотрении объектов ADO. При работе с ними, как и ранее, используются глобальные объекты - Con1, Cmd1, Rst1.
Программное формирование структуры сводной таблицы
Теперь, когда объекты PivotCache и PivotTable уже созданы, можно приступить к завершающему этапу - формированию структуры отчета сводной таблицы. Это означает, что нужно поля таблицы, содержащиеся в коллекции PivotFields распределить по измерениям. И здесь существует несколько способов выполнения этой работы. В предыдущих версиях я применял метод AddFields, который, правда, имел ряд ограничений. Теперь всю эту работу удобнее выполнять, работая непосредственно с объектами PivotField. Полного описания этих объектов давать не буду, но поясню, какими свойствами я пользовался, на примере формирования отчета сводной таблицы. Процедура, которую я сейчас приведу, полностью решает вопрос программного создания сводной таблицы, начиная от этапа связывания с источником данных, кончая этапом формирования структуры таблицы и группирования ее данных. Вот ее текст:
Public Sub MyCreatePT()
'Создание отчета сводной таблицы
'Создание кэша и отчета сводной таблицы - объектов PivotCache, PivotTable
'CreatePivotCacheAndTable
'Другой вариант создания кэша - через ADO
CreatePivotCacheAndTableWithADO
'Формирование отчета сводной таблицы
With ThisWorkbook.Worksheets("Лист1").PivotTables("Анализ продаж")
With .PivotFields("ДатаЗаказа")
.Orientation = xlRowField
.Position = 1
End With
With .PivotFields("Сотрудник")
.Orientation = xlRowField
.Position = 2
End With
With .PivotFields("НазваниеКниги")
.Orientation = xlColumnField
.Position = 1
End With
With .PivotFields("Заказчик")
.Orientation = xlPageField
.Position = 1
End With
With .PivotFields("Стоимость")
.Orientation = xlDataField
.Position = 1
End With
With .PivotFields("Количество")
.Orientation = xlDataField
.Position = 2
End With
End With
Range("A5").Select
Selection.Group Start:=True, End:=True, By:=7, Periods:=Array(False, _
False, False, True, False, False, False)
End SubЯ приведу несколько комментариев:
- На первом этапе работы создаются объекты PivotCache и PivotTable, для чего вызываются уже рассмотренные нами процедуры. Реально вызывается одна из этих процедур, вызов другой закомментирован. Какой вариант предпочесть - дело вкуса. О достоинствах этих вариантов я говорил.
- После создания указанных объектов формируется структура отчета сводной таблицы. Для каждого из полей сводной таблицы задается соответствующее измерение и порядок расположения. Для этого используются свойства объектов PivotField - Orientation и Position. Первое из них задает измерение, второе - порядок в измерении. Добраться до нужного поля позволяет коллекция PivotFields, где в качестве индекса используется имя поля.
- На заключительном шаге производится группирование данных по полю "Дата заказа". В данном случае я группирую данные по неделям. Скажу несколько слов о методе группирования данных - Group, производящем эту операцию. Он является методом класса Range и, следовательно, может вызываться объектом Selection. Здесь применяется его форма, специально созданная для группирования данных сводной таблицы. При группировании дат булев массив Periods указывает одну из 7 возможных единиц группирования (секунду, минуту, час, день, месяц, квартал, год), а параметр BY задает количество единиц в группе.
Единственное, что осталось сделать для завершения рассказа о программном создании отчета сводной таблицы, - это посмотреть на результаты работы нашей процедуры:
Методы прогнозирования
Сводные таблицы позволяют анализировать прошлое и настоящее. Прогнозирование - это способ заглянуть в будущее. Любая направленная деятельность предполагает построение прогноза параметров, определяющих эту деятельность. Есть два пути прогнозирования. Первый - построить модель поведения исследуемого параметра, основанную на причинно-следственных связях, изучении законов его поведения. Так, довольно просто описать траекторию полета ракеты, подчиняющуюся законам небесной механики. Траекторию управляемого пилотом самолета описать труднее. Еще сложнее описать "траекторию" спроса на тот или иной продукт, поскольку она определяется действиями большого числа "пилотов", которые в любой момент могут начать или перестать покупать фирменный продукт.
Второй путь - статистическое прогнозирование, позволяет, не вдаваясь в механику движения, предсказать будущее поведение, анализируя полученную статистику поведения в прошлом. Статистическое прогнозирование - неотъемлемый атрибут экономической деятельности любого масштаба. Подобный прогноз может быть краткосрочным или среднесрочным. В первом случае прогноз базируется на данных за короткий период времени (например, месяц) и строится на один-два момента вперед. Такой прогноз обычно должен быть оперативным и непрерывным. Среднесрочный прогноз определяет поведение в отдаленном будущем, скажем, на год вперед. Он требует больше данных и специальных методов, отличных от методов краткосрочного прогноза.
О методах прогноза написано много. В документации можно найти обширный список литературы, использованной при построении стандартных процедур. Мы пользовались другими, доступными для нас источниками, и позволим себе без подробных обоснований привести несколько методов. О регрессионном анализе и оценках по методу наименьших квадратов можно прочитать в любом хорошем учебнике по математической статистике. Замечу, что те, кому экскурс в разделы статистики покажется утомительным, могут без особого ущерба пропустить его, и перейти к чтению разделов, где непосредственно рассматриваются соответствующие средства Excel.
Методы краткосрочного прогноза
Применяемые при краткосрочном прогнозе методы основываются на разных моделях поведения спроса. Наиболее часто используются модели:
- устойчивого (постоянного) спроса;
- линейно изменяющегося спроса (возрастающего или убывающего);
- сезонного спроса;
- комбинации этих моделей.
Метод экспоненциального сглаживания
В модели устойчивого спроса методы прогноза основаны на скользящем среднем, где вычисляется средневзвешенное значение по результатам предыдущих измерений. Весь вопрос в том, какой временной интервал учитывать и какие веса приписывать данным. Один из простых и лучших методов - экспоненциальное сглаживание, описываемое соотношением:
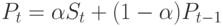
где St - фактический спрос в момент времени t, а Pt - его оценка, экстраполируемая на будущее. Формула показывает, что оценка является взвешенной суммой последнего полученного значения спроса и предыдущей оценки. Параметром метода, устанавливаемым эмпирически, является весовой коэффициент  . Чем меньше , тем большее значение придается прошлым данным. Если же большего доверия заслуживают последние данные, следует увеличивать. Рекомендуемые значения обычно выбираются из интервала 0.1-0.5.
. Чем меньше , тем большее значение придается прошлым данным. Если же большего доверия заслуживают последние данные, следует увеличивать. Рекомендуемые значения обычно выбираются из интервала 0.1-0.5.
Метод Чоу адаптивного прогнозирования позволяет подбирать в процессе прогноза. Его суть состоит в том, чтобы одновременно вести три прогноза с разными значениями , например 0.1, 0.15 и 0.2. Если реальный спрос ближе к одной из границ, скажем, верхней, система перестраивается, и новыми значениями будут 0.15, 0.2 и 0.25.