Опубликован: 26.10.2007 | Доступ: свободный | Студентов: 2364 / 792 | Оценка: 4.04 / 3.76 | Длительность: 17:47:00
ISBN: 978-5-94774-810-9
Лекция 10:
Кодирование с адаптивным предсказанием
Вокодерное оборудование
Полосовой вокодер
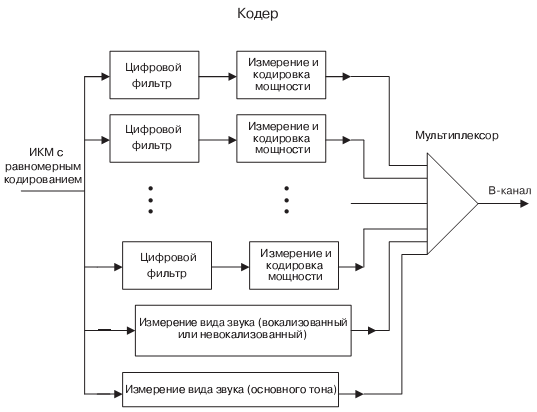
На рис. 10.6 и рис. 10.7 показан полосовой (канальный) вокодер [10.6, 10.7]. Основная задача процесса кодирования в вокодере — определить спектр сигнала, мощности в каждом диапазоне частот за достаточно длинный отрезок времени, в который существует форманта. На передающей стороне аналоговый сигнал поступает на аналогоцифровое устройство преобразования (АЦП). После этого он проходит ряд цифровых фильтров, каждый из которых выделяет узкую полосу. Чем меньше полоса, тем лучше будет качество речи на приемном конце. Но чем больше информации о частотных полосах, тем больше придется передавать информации по цифровому тракту. Далее используются устройства, измеряющие и кодирующие значение мощности спектра в каждом диапазоне частот. В дополнение к информации о спектре вокодеры определяют характер возбуждения (гласный или звонкий согласный, в отличие от глухого согласного) и частоту основного тона для гласных или звонких согласных звуков.
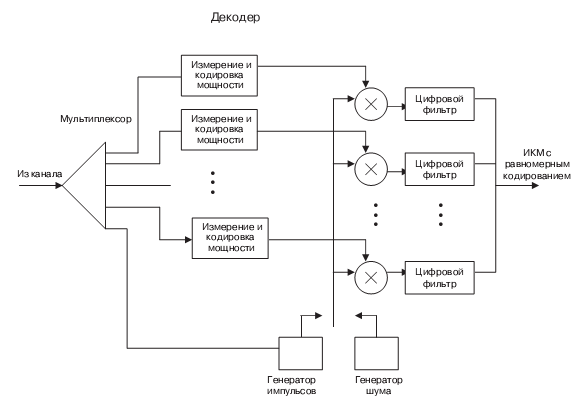
Полученная информация передается на приемный конец, где она используется для управления цифровым генератором. Он представляет память, где хранятся временные отсчеты частот, из которых необходимо выбрать нужную по частоте и мощности. Возбуждение гласных происходит с помощью генератора импульсов, который открывает на определенное время генерацию основного тона. Возбуждение глухих звуков имитируется шумовым генератором.
Ортогональный вокодер
Ортогональные вокодеры отличаются от полосовых тем, что функции фильтров выполняются с помощью цифровых методов. Это либо быстрое преобразование Фурье, либо ортогональные функции Уолша (периодические дискретные функции, принимающие значения 0 или 1) [10.5].
Формантный вокодер
Как видно из рис. 10.7, энергия речи может концентрироваться в трех-четырех пиках, называемых формантами. Формантный вокодер определяет и передает положение пика энергии в частотном диапазоне, амплитуду спектральных пиков. Вследствие этого снижается объем передаваемой информации. Качество восстановленной речи зависит от точности определения этих параметров. Принцип устройства формантного вокодера основан, так же как и в предыдущем случае, на разделении спектра на полосы и в определении в полосах необходимых характеристик. Но для передачи отбираются только данные о возбужденных спектрах. Это снижает требования к объему передаваемой информации. Декодер восстанавливает сигнал также с помощью генерации основного тона и различных типов сигналов (шумовых и импульсных). Такой тип вокодера обеспечивает передачу речи со скоростью до 1 Кбит/с, но применяется сравнительно редко из-за больших трудностей, связанных с точным вычислением формант.
Вокодеры с линейным предсказанием (липредеры)
Этот тип вокодера (рис. 10.8, рис. 10.9), в отличие от предыдущих типов, для передачи речи применяет не фильтры, а систему линейного предсказания. Как уже упоминалось (рис. 10.1), в линию передается разностный сигнал между истинным и предсказанным значениями. Коэффициенты предсказания [10.8] используются для предсказания управлением, восстанавливающим генератором на приеме и добавления генератором шума для передачи глухих и "свистящих" согласных.
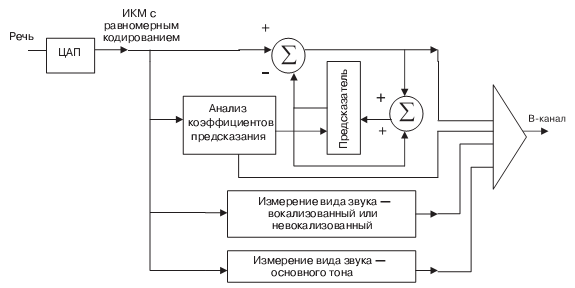
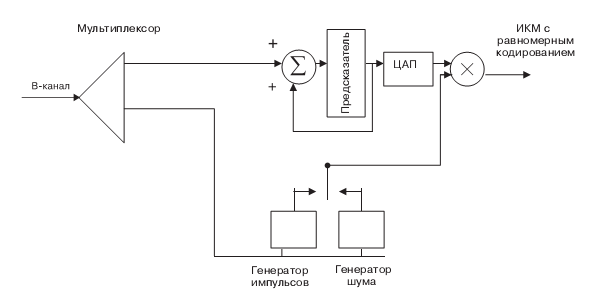
Прямое использование предсказания позволяет воспроизводить звук, но с плохим качеством. ( Качество оценивается в соответствии с методиками, рассмотренными в главе 1.) Поэтому этот метод имеет много различных разновидностей, улучшающих это качество. Эти методы касаются улучшения параметров возбуждения генераторов на приемном конце. Поэтому из трех составляющих системы с предсказанием — аппроксимации, предсказания и методов восстановления (возбуждения генераторов) речи — все усовершенствования метода линейного предсказания касаются последней составляющей. Поэтому они иногда называются гибридными кодерами, ибо представляют собой гибриды вокодеров и кодеров сигнала. Рассмотрим коротко каждый из них.
Многоимпульсное кодирование (MPLPC — Multi-Pulse LPC) [10.2, 10.9] . Оно отличается от LPC тем, что предсказание касается не основного тона, а параметров передаваемых и принимаемых импульсов, что более похоже на методы адаптивного кодирования. В отличие от последних прогнозируется последовательность импульсов. При этом способе не надо находить тип фрагмента речи (вокализированная речь или нет) и находить параметры основного тона. Такой тип кодирования применяется в широко применяемой системе передачи речи по Internet — система Skype. Он позволяет передавать речь со скоростью 9,6 кбит/с.
Линейное предсказание с возбуждением усеченного остаточного сигнала (RELP LTP — Residual Excited Linear Predication Long Term Prediction). Отличается от предыдущего тем, что в результате обработки кодируется и предсказывается нижняя часть речевого спектра, и это уменьшает число обрабатываемых и предсказываемых отсчетов. Применение RELP в некоторых Европейских мобильных системах позволяет снизить скорость передачи в канале с 16 до 9,6 Кбит/с без существенного снижения качества речи.
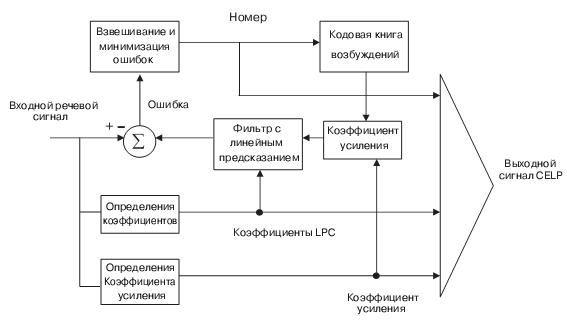
Линейное предсказание с кодовым возбуждением (CELP — Code Excited Linear Prediction).
Данный класс речевых кодеров занимает промежуточное место между кодерами формы сигнала и параметрическими вокодерами. Анализ параметров речи осуществляется на интервалах 10-30 мс, что позволяет эффективно применять CELP при скоростях передачи от 4 до 16 Кбит/c. Как видно из структурной схемы кодера CELP (рис. 10.10), вместо кодирования сигналов отсчет за отсчетом кодером разностного сигнала (см. рис. 10.2 и 10.3) применяется "кодовая книга возбуждения". В этом случае каждому разностному сигналу сопоставляется строка (шаблон) сигналов. Эта строка содержит набор отсчетов, соответствующих передаваемой остаточной последовательности на основе полученного значения ошибки. На приемном конце вместо декодера разностного сигнала также применяется "кодовая книга возбуждения".
Существует большое число разновидностей кодовых книг, которые классифицируются:
- по принципу поиска кодов векторов (с полным перебором, двоичный или последовательный поиск и т.п.);
- по способам обучения (Фиксированная или адаптируемая книга);
- по виду хранимой информации (выборки речи или реализация шума).
Алгоритм CELP позволяет воспроизводить речь с высоким качеством. Средняя экспертная оценка: 3,5—3,5. Однако он требует больших вычислительных ресурсов, поэтому на его основе построено много разновидностей кодеров.
Многие из технологий, использующих методы предсказания и вокодерные принципы преобразования, стандартизированы ITU-T [10.12-10.20].
Ниже приводится табл. 10.1, которая позволяет сравнить качество методов при различных типах кодеров.
При том заметим, что:
- метод экспертных оценок с помощью показателя усредненного мнения (MOS — Mean Opinion Score) мы рассматривали в главе 1;
- метод артикуляционных испытаний основан на использовании списков фраз, каждый из которых содержит по 96 пар рифмованных близких по звучанию слов (радостьгадость, кошкакрошка….);
- оценка разборчивости речи характеризуется числом правильно принятых слов
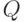 ; выраженным в процентах, т.е.
; выраженным в процентах, т.е. 
где
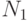 — число правильных ответов;
— число правильных ответов;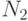 — число неверных ответов.
— число неверных ответов.
Оценка качества проводится по следующей таблице (табл. 10.1).
В таблице 10.2 приводятся результаты оценки различных кодеров по различным методам оценок.