|
Нахожу в тесте вопросы, которые в принципе не освещаются в лекции. Нужно гуглить на других ресурсах, чтобы решить тест, или же он всё же должен испытывать знания, полученные в ходе лекции? |
Опубликован: 02.09.2013 | Доступ: свободный | Студентов: 429 / 54 | Длительность: 19:27:00
Тема: Программирование
Специальности: Программист, Системный архитектор
Лекция 2:
Введение в машинное обучение
1.1.2. Метод k ближайших соседей
Метод 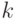 ближайших соседей (k nearest-neighbor, k-NN) относится к наиболее простым и в то же
время универсальным методам, используемым как для решения задач классификации, так и
восстановления регрессии. В случае классификации новый объект классифицируется путем
отнесения его к классу, являющемуся преобладающим среди ближайших (в пространстве
признаков) объектов из обучающей выборки. Если
ближайших соседей (k nearest-neighbor, k-NN) относится к наиболее простым и в то же
время универсальным методам, используемым как для решения задач классификации, так и
восстановления регрессии. В случае классификации новый объект классифицируется путем
отнесения его к классу, являющемуся преобладающим среди ближайших (в пространстве
признаков) объектов из обучающей выборки. Если  , то новый объект относится к тому же
классу, что и ближайший объект из обучающей выборки.
, то новый объект относится к тому же
классу, что и ближайший объект из обучающей выборки.
Аналогичный способ используется и в задаче восстановления регрессии, с той лишь разницей, что в качестве ответа для объекта выступает среднее ответов k ближайших к нему объектов из обучающей выборки.
Опишем метод более формально. Пусть 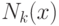 – множество ближайших к
– множество ближайших к  объектов из
обучающей выборки. Тогда для задачи классификации положим
объектов из
обучающей выборки. Тогда для задачи классификации положим
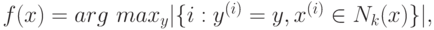
а для задачи восстановления регрессии –

В некоторых случаях данные ответы учитываются с весами, обратно пропорциональными расстоянию до объекта. Это особенно полезно для решения задачи классификации с несбалансированными данными, т. е. когда число объектов, относящихся к разным классам, сильно различно.
Для определения ближайших соседей обычно используется евклидово расстояние

однако оно применимо только для признаков, описываемых количественными переменными. Если все переменные качественные, то можно использовать расстояние Хэмминга
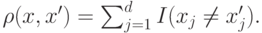
В общем случае используют функцию
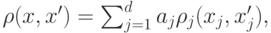
где 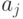 – неотрицательные параметры,
– неотрицательные параметры, 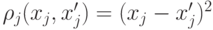 для качественных переменных,
для качественных переменных, 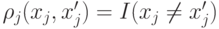 для качественных переменных. Заметим, что функция расстояния не
обязательно должна быть метрикой и неравенство треугольника может быть не выполнено.
для качественных переменных. Заметим, что функция расстояния не
обязательно должна быть метрикой и неравенство треугольника может быть не выполнено.
Для повышения точности модели также могут использоваться специальные алгоритмы обучения метрики расстояния (например, Large Margin Nearest Neighbour [8]).
Одним из основных параметров, влияющих на обобщающую способность алгоритма, является
число "ближайших соседей" . В целом, выбор определенного значения обусловлен характером
данных задачи. Большие значения могут привести как к более точному описанию границы,
разделяющей классы, так и переобучению. Обычно для выбора применяют различные
эвристики, в частности, метод перекрестного контроля.
1.1.3. Машина опорных векторов
Один из самых популярных методов машинного обучения – машина опорных векторов (SVM – Support Vector Machine) – является развитием идей, предложенных в 1960–1970 гг. В. Н. Вапником и А. Я. Червоненкисом. Окончательное очертание метод принял в 1995 г., когда было показано, как в этом методе можно эффективно использовать ядра [4].
Рассмотрим вначале случай двух линейно разделимых классов. Для удобства будем их кодировать
числами 1,-1 т. е. 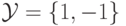 .
.
Оптимальной разделяющей гиперплоскостью называется гиперплоскость, такая, что расстояние от нее до ближайшей точки из обучающей выборки (не важно из какого класса) максимально. Таким образом, оптимальная разделяющая гиперплоскость максимизирует зазор (отступ) – расстояние от нее до точек из обучающей выборки. Часто это приводит к хорошим результатам и на объектах тестовой выборки.
Математическая постановка задачи выглядит следующим образом:
Требуется найти
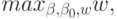
при ограничениях
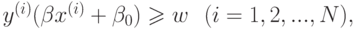
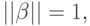
где 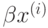 означает скалярное произведение
означает скалярное произведение

а 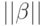 – евклидову норму
– евклидову норму
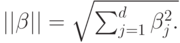
Эквивалентная формулировка:
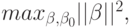
при ограничениях
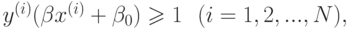
Можно показать, что решение этой задачи имеет вид
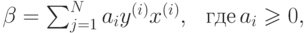
уравнение разделяющей гиперплоскости есть 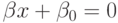 и классификатор определяется
правилом
и классификатор определяется
правилом
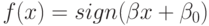
Если 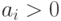 то
то 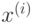 называется опорной точкой или опорным вектором. Легко видеть, что
опорные точки лежат на границе разделяющей полосы
называется опорной точкой или опорным вектором. Легко видеть, что
опорные точки лежат на границе разделяющей полосы
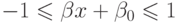
следовательно, 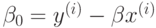 , где
– произвольный опорный вектор.
, где
– произвольный опорный вектор.
В случае линейно не разделимых классов разрешим некоторым объектам из обучающей выборки "слегка" заходить за разделяющую гиперплоскость:
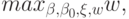
при ограничениях
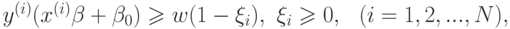
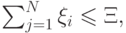
где  – некоторая константа (параметр метода). При
– некоторая константа (параметр метода). При 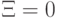 получаем предыдущий случай (линейно
разделимых классов). Значение
получаем предыдущий случай (линейно
разделимых классов). Значение 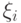 пропорционально величине, на которую
заходит за границу
разделяющей полосы. В частности, -й объект будет классифицирован неправильно тогда и только
тогда, когда
пропорционально величине, на которую
заходит за границу
разделяющей полосы. В частности, -й объект будет классифицирован неправильно тогда и только
тогда, когда 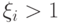 . Чем меньше , тем меньше объектов классифицируется неправильно. С другой
стороны, должно быть достаточно велико, чтобы задача была совместной.
. Чем меньше , тем меньше объектов классифицируется неправильно. С другой
стороны, должно быть достаточно велико, чтобы задача была совместной.
Эквивалентная формулировка:
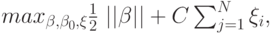
при ограничениях
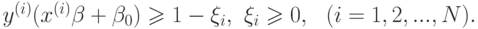
Здесь параметр  регулирует величину штрафа за то, что некоторые точки выходят за границу
разделяющей полосы. Построенная задача является задачей квадратического программирования.
Для ее решения можно использовать общие методы для решения таких задач, однако существуют
весьма эффективные специальные методы.
регулирует величину штрафа за то, что некоторые точки выходят за границу
разделяющей полосы. Построенная задача является задачей квадратического программирования.
Для ее решения можно использовать общие методы для решения таких задач, однако существуют
весьма эффективные специальные методы.
Можно показать, что решение задачи единственно, если в обучающей выборке есть по крайней мере один представитель каждого из классов.
Дальнейшее усовершенствование метода – использование спрямляющих пространств. Пусть
удается перейти от исходного пространства признаков 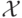 к новому пространству
к новому пространству 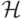 (которое
называется спрямляющим) с помощью некоторого отображения
(которое
называется спрямляющим) с помощью некоторого отображения 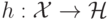 :
:
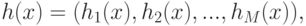
где  – базисные функции
– базисные функции  . Новый классификатор определяется теперь
функцией
. Новый классификатор определяется теперь
функцией

Здесь 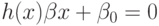 – разделяющая поверхность. Если отображение подобрано удачно, в новом
пространстве классы могут быть линейно разделимы или близки к таковым.
– разделяющая поверхность. Если отображение подобрано удачно, в новом
пространстве классы могут быть линейно разделимы или близки к таковым.
Оказывается, все вычисления при обучении и при расчете функции 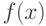 можно организовать так,
что
можно организовать так,
что 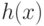 встречается только в выражениях вида
встречается только в выражениях вида
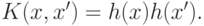
В частности уравнение разделяющей поверхности имеет вид
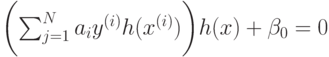
что эквивалентно

или
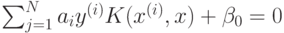
Функция 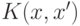 называется ядром. На практике, таким образом, вместо того, чтобы испытывать
различные функции
называется ядром. На практике, таким образом, вместо того, чтобы испытывать
различные функции 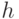 можно (так и поступают) подбирать наиболее подходящее ядро .
можно (так и поступают) подбирать наиболее подходящее ядро .
Заметим, что не любая функция 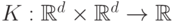 представима в виде
представима в виде 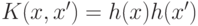 , т. е.
может быть использована в качестве ядра. Приведем перечень некоторых популярных функций-
ядер:
, т. е.
может быть использована в качестве ядра. Приведем перечень некоторых популярных функций-
ядер:
- линейное ядро:
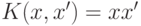
- многочлен степени:
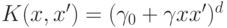
- радиальная функция:

- сигмоидальная ("нейронная") функция:
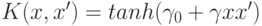
Для того чтобы использовать метод опорных векторов для задачи классификации с числом классом K>2 , возможно использовать две стратегии:
- "Каждый против каждого": построить K(K-1)/2 классификаторов на всех возможных подзадачах бинарной классификации. Новый объект классифицируется всеми построенными решающими правилами, затем выбирается преобладающий класс.
- "Один против всех": обучить K моделей на задачах бинарной классификации вида "один класс против всех остальных". Класс нового объекта выбирается по максимальному значению отступа.
Андрей Терёхин
Демянчик Иван
|
В главе 14 мы видим понятие фильтра, но не могу разобраться, чем он является в теории и практике. " Искомый объект можно описать с помощью фильтра |
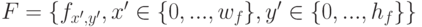 "
"