|
Где проводится профессиональная переподготовка "Системное администрирование Windows"? Что-то я не совсем понял как проводится обучение. |
Европейский Университет в Санкт-Петербурге
Опубликован: 04.07.2008 | Доступ: свободный | Студентов: 1329 / 267 | Оценка: 4.34 / 3.65 | Длительность: 21:13:00
Тема: Операционные системы
Специальности: Архитектор программного обеспечения
Лекция 8:
Концепция, устройство и администрирование файловой системы ZFS
Uber-блок крупным планом
Uber-блок записывается с родным для данного компьютера порядком байт5Здесь и далее мы переводим термин big endian (в младших адресах памяти располагаются более значимые байты) как "тупоконечный" и little endian (в младших адресах памяти располагаются менее значимые байты) – как "остроконечный" порядки байт. Тупоконечный порядок характерен для процессоров SPARC, а остроконечный – для Intel и AMD. Термины я впервые услашал от Игоря Николаева из СПбГУ при обсуждении того, что переводы "обратный" и "прямой" порядок неявно подразумевали некую "правильность" того или иного варианта, в то время как на самом деле и тот, и другой порядки имеют равное право на существование. и содержит:
ub_magic
Специфическое поле, 64-битное целое, идентифицирующее данное устройство как содержащее данные ZFS. Значение поля – 0x00bab10c (oo-ba-block, произносится схоже с uberblock). Таблица 8.1 показывает значения поля в зависимости от порядка байт так, как они записываются на диски:
ub_version
Поле используется для указания формата, в котором на диске хранятся данные. В настоящее время определено только значение 0x1. Это поле должно содержать то же значение. что и поле "version", описанное в разделе 1.3.3.
ub_txg
Все операции записи в ZFS выполняются группами транзакций. Каждая группа ассоциируется с определенным номером транзакции. Значение ub_txg показывает, в пределах какой группы транзакций был записан этот uber-блок. Чтобы это значение считалось корректным, оно должно быть больше или равно значения поля txg, хранящегося в nvlist для этой метки виртуального устройства.
ub_guid_sum
Это поле служит для проверки доступности устройств внутри пула.
Пока пул используется, драйвер ZFS пробегает все физические устройства пула и суммирует значения GUID с каждого устройства в пуле (значение хранится в паре имя/значение с именем guid в списке пар имя/ значение, как описано в разделе 1.3.3). Подсчитанная сумма сравнивается с ub_guid_sum, чтобы подтвердить доступность все устройств в пуле.
ub_timestamp
Время, когда был записан этот uber-блок – в секундах, отсчитанное с 1 января 1970 г. (часовой пояс UTC).
ub_rootbp
ub_rootbp – это структура blkptr, содержащая расположение MOS. И MOS, и blkptr описаны в главах 4 и 2 этого документа соответственно.
Указатели блоков и блоки косвенной адресации
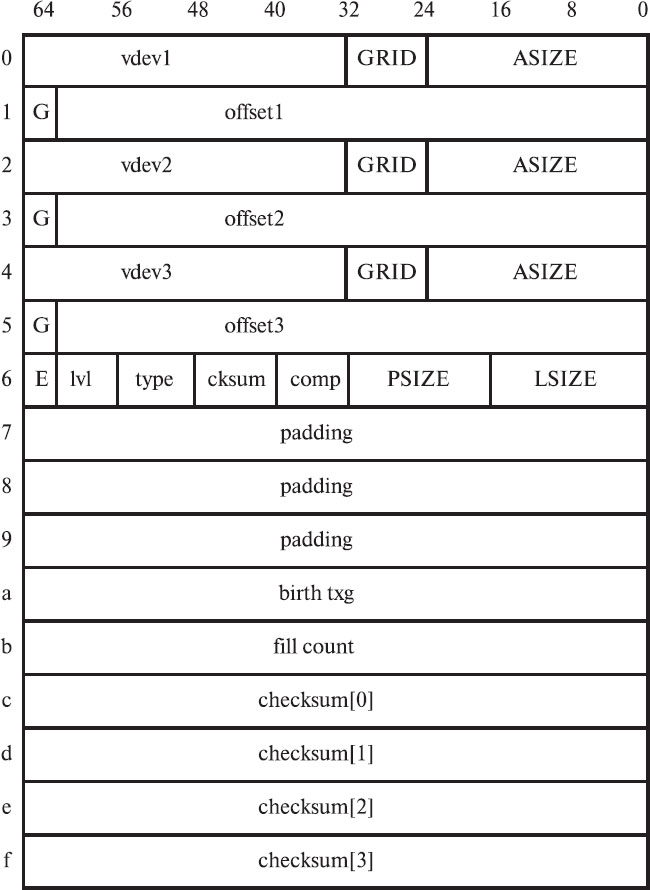
Данные пересылаются между памятью и диском блоками. Указатель блока blckptr_t – это 128-байтная структура ZFS, которая нужна для того, чтобы описать физическое расположение блока на диске, описать сам блок и иметь возможность проверить его целостность. Структура указателя блока показана на рис. 8.6.
Виртуальный адрес данных (DVA – Data Virtual Address)
Виртуальный адрес данных – это комбинация полей vdev и offset указателя блока; например, комбинация значений поля vdev1 и поля offset1 дает виртуальный адрес dva1. ZFS позволяет иметь до трех копий данных, на которые указывает данный указатель блока. Каждая копия имеет свой виртуальный адрес – dva1, dva2 и dva3 соответственно. По каждому из этих адресов хранятся совершенно одинаковые данные. Количество используемых виртуальных адресов в указателе блока основано на политике6По состоянию на август 2007 года политика такая: самые важные метеданные пишутся с тройным резервированием (3DVA), менее важные метаданные – с двойным (2 DVA), а просто данные – без резервирования вовсе (1 DVA). файловой системы и называется "шириной" указателя блока: обычный указатель (1 DVA), указатель двойной ширины (2 DVA) и тройной ширины (3 DVA).
Поле vdev (32-разрядное целое) каждого DVA в указателе блока однозначно идентифицирует виртуальное устройство, на котором хранится блок. Поле offset (63-разрядное целое) – это адрес блока на устройстве, отсчет начинается сразу после меток виртуального устройства L0 и L1 и загрузочного блока в пределах того устройства, на котором хранятся данные. Vdev и offset вместе определяют уникальное адрес блока данных. В поле offset указывается адрес в секторах (т.е. в кусках пространства по 512 байт).
Для того, чтобы найти смещение физического блока в байтах от начала раздела (slice), значение поля offset следует сдвинуть влево на 9 разрядов (29 = 512) и затем сложить с 0x400000 (размер двух меток устройства vdev_label и загрузочного блока):
physical block address = (offset << 9) + 0x400000 (4MB)
GRID
Поле зарезервировано для последующего использования в отказоустойчивах конфигурациях Raid-Z.
GANG
Группирующий (gang) блок – это блок, содержащий указатели на блоки. Группирующие блоки используются, если запрошенное дисковое пространство невозможно выделить одним непрерывным блоком. В этом случае выделяются несколько блоков меньшего размера так, чтобы их суммарный размер был равен запрошенному, и создается группирующий блок, в котором будут храниться указатели для выделенных блоков. Приложению, которое запросило дисковое пространство, возвращается указатель на группирующий блок, и это создает у него "ощущение", что ему выделен единственный блок.
Группирующий блок идентифицируется установленным битом "G":
Группирующий блок имеет размер 512 байт и сам содержит свою контрольную сумму. Он может содержать до 3 указателей на блоки, за которыми следует 32-разрядная контрольная сумма. Формат группирующего блока описывает следующая структура:
typedef struct zio_gbh {
blkptr_t zg_blkptr[SPA_GBH_NBLKPTRS];
uint64_t zg_filler[SPA_GBH_FILLER];
zio_block_tail_t zg_tail.;
} zio_gbh_phys_t;zg_blkptr: массив указателей на блоки. Каждый 512-байтный группирующий блок может содержать до 3 указателей на блоки.
zg_filler: поле заполнителя (filler) требуется для того, чтобы дополнить группирующий блок до 512 байт.
typedef struct zio_block_tail {
uint64_t zbt_magic;
zio_cksum_t zbt_cksum;
}zbt_magic: специфическое значение, завершающее блок ZIO. Равно 0x210da7ab10c7a11 (zio-data-bloc-tail).
typedef zio_cksum {
uint64_t zc_word[4];
}zio_cksum_t;zc_word: четыре 8-байтных слова, содержащих контрольную сумму группирующего блока.
cksum (Контрольная сумма)
По умолчанию в ZFS контрольная сумма вычисляется для всех данных и метаданных. Поддерживается несколько алгоритмов контрольного суммирования, в том числе fletcher2, fletcher4 и SHA-256 (256-bit Secure Hash Algorithm из FIPS 180-2, подробнее на странице http://csrc.nist.gov/cryptval). Какой алгоритм использовать для вычисления контрольной суммы этого блока, определяется значением 8-разрядного целого в поле cksum указателя блока. В таблице 8.3 приводится соответствие значений алгоритмам.
comp (Сжатие)
ZFS поддерживает несколько алгоритмов сжатия. Какой тип сжатия использовать для данного блока, определяется полем comp указателя блока:
| Описание | Значение | Алгоритм |
|---|---|---|
| on | 1 | lzjb |
| off | 2 | нет сжатия |
| lzjb | 3 | lzjb |
Размер блока
Размер блока определяется тремя разными полями в указателе блока: psize, lsize, and asize.
- lsize: логический размер. Показывает размер данных без учета сжатия, программного RAID (RAID-Z) или накладных расходов, связанных с группирующими блоками (gang):
- psize: физический размер блока на диске после сжатия;
- asize: фактически занятое данными пространство, общий размер всех блоков, занятых для хранения этих данных, включая заголовки группирующих блоков или блоки четности RAID-Z.
Если сжатие данных не включено и ZFS организовано без RAID-Z, то значения lsize, asize, и psize одинаковы. Все эти значения записываются как количество 512-байтных секторов минус один, которые занимает блок.
Порядок байт в слове
ZFS легко адаптируется к переносу между компьютерами разной архитектуры, даже если в них используется различный порядок байт в слове – тупоконечный (big endian, в младших адресах памяти располагаются более значимые байты, SPARC) или остроконечный (little endian, в младших адресах памяти располагаются менее значимые байты, x86). Поле E указателя блока (от Endianness) содержит 1 для блока, записанного в остроконечном порядке байт (x86), и 0 – для блока, записанного в тупоконечном порядке (SPARC). Данные всегда пишутся на диск в формате того компьютера, на котором это происходит. Если пул перемещается из компьютера с одним порядком байт на компьютер с другим порядком байт, содержимое блока конвертируется в новый порядок при чтении, а на диске старое содержимое остается в прежнем формате.
Александр Тагильцев