Инспектор

Вы можете этот курс.
Опубликован: 22.08.2012 | Уровень: для всех | Доступ: платный | ВУЗ: Московский государственный открытый университет им. В.С. Черномырдина
Лекция 11:
Интеллектуальные задачи в экономике
Многослойный персептрон (MLP)
Эта архитектура сети используется сейчас наиболее часто. Она была предложена в работе Rumelhart, McClelland (1986) и подробно обсуждается почти во всех учебниках по нейронным сетям (см., например, Bishop, 1995). Вкратце этот тип сети был описан выше. Каждый элемент сети строит взвешенную сумму своих входов с поправкой в виде слагаемого и затем пропускает эту величину активации через передаточную функцию, и таким образом получается выходное значение этого элемента. Элементы организованы в послойную топологию с прямой передачей сигнала. Такую сеть легко можно интерпретировать как модель вход-выход, в которой веса и пороговые значения (смещения) являются свободными параметрами модели. Такая сеть может моделировать функцию практически любой степени сложности, причем число слоев и число элементов в каждом слое определяют сложность функции. Определение числа промежуточных слоев и числа элементов в них является важным вопросом при конструировании MLP (Haykin, 1994; Bishop, 1995).
Количество входных и выходных элементов определяется условиями задачи. Сомнения могут возникнуть в отношении того, какие входные значения использовать, а какие нет. Сейчас будем предполагать, что входные переменные выбраны интуитивно и что все они являются значимыми. Вопрос же о том, сколько использовать промежуточных слоёв и элементов в них, пока совершенно неясен. В качестве начального приближения можно взять один промежуточный слой, а число элементов в нём положить равным полусумме числа входных и выходных элементов.
Обучение многослойного персептрона
После того, как определено число слоёв и число элементов в каждом из них, нужно найти значения для весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. С использованием собранных исторических данных веса и пороговые значения автоматически корректируются с целью минимизировать эту ошибку. По сути, этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибка для конкретной конфигурации сети определяется путём прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Все такие разности суммируются в так называемую функцию ошибок, значение которой и есть ошибка сети. В качестве функции ошибок чаще всего берётся сумма квадратов ошибок, т.е. когда все ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются. При работе с пакетом ST Neural Networks пользователю выдается так называемая среднеквадратичная ошибка (RMS) - описанная выше величина нормируется на число наблюдений и переменных, после чего из неё извлекается квадратный корень - это очень хорошая мера ошибки, усреднённая по всему обучающему множеству и по всем выходным элементам.
В традиционном моделировании (например, линейном моделировании) можно алгоритмически определить конфигурацию модели, дающую абсолютный минимум для указанной ошибки. Цена, которую приходится платить за более широкие (нелинейные) возможности моделирования с помощью нейронных сетей, состоит в том, что, корректируя сеть с целью минимизировать ошибку, мы никогда не можем быть уверены, что нельзя добиться еще меньшей ошибки.
В этих рассмотрениях оказывается очень полезным понятие поверхности ошибок. Каждому из весов и порогов сети (т.е. свободных параметров модели; их общее число обозначим через N) соответствует одно измерение в многомерном пространстве. N+1-е измерение соответствует ошибке сети. Для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N+1-мерном пространстве, и все такие точки образуют там некоторую поверхность - поверхность ошибок. Цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку.
В случае линейной модели с суммой квадратов в качестве функции ошибок эта поверхность ошибок будет представлять собой параболоид (квадрику) - гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом. В такой ситуации локализовать этот минимум достаточно просто.
В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и обладает рядом неприятных свойств, в частности, может иметь локальные минимумы (точки, самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), плоские участки, седловые точки и длинные узкие овраги.
Аналитическими средствами невозможно определить положение глобального минимума на поверхности ошибок, поэтому обучение нейронной сети по сути дела заключается в исследовании поверхности ошибок. Отталкиваясь от случайной начальной конфигурации весов и порогов (т.е. случайно взятой точки на поверхности ошибок), алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) поверхности ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в нижней точке, которая может оказаться всего лишь локальным минимумом (а если повезет - глобальным минимумом).
Алгоритм обратного распространения
Самый известный вариант алгоритма обучения нейронной сети - так называемый алгоритм обратного распространения (back propagation; см. Patterson, 1996; Haykin, 1994; Fausett, 1994). Существуют современные алгоритмы второго порядка, такие как метод сопряженных градиентов и метод Левенберга-Маркара (Bishop, 1995; Shepherd, 1997) (оба они реализованы в пакете ST Neural Networks), которые на многих задачах работают существенно быстрее (иногда на порядок). Алгоритм обратного распространения наиболее прост для понимания, а в некоторых случаях он имеет определенные преимущества. Сейчас мы опишем его, а более продвинутые алгоритмы рассмотрим позже. Разработаны также эвристические модификации этого алгоритма, хорошо работающие для определенных классов задач, - быстрое распространение (Fahlman, 1988) и Дельта-дельта с чертой (Jacobs, 1988) - оба они также реализованы в пакете ST Neural Networks.
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Этот вектор указывает направление кратчайшего спуска по поверхности из данной точки, поэтому если мы "немного" продвинемся по нему, ошибка уменьшится. Последовательность таких шагов (замедляющаяся по мере приближения к дну) в конце концов приведет к минимуму того или иного типа. Определенную трудность здесь представляет вопрос о том, какую нужно брать длину шагов.
При большой длине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или (если поверхность ошибок имеет особо вычурную форму) уйти в неправильном направлении. Классическим примером такого явления при обучении нейронной сети является ситуация, когда алгоритм очень медленно продвигается по узкому оврагу с крутыми склонами, прыгая с одной его стороны на другую. Напротив, при маленьком шаге, вероятно, будет схвачено верное направление, однако при этом потребуется очень много итераций. На практике величина шага берется пропорциональной крутизне склона (так что алгоритм замедляет ход вблизи минимума) с некоторой константой, которая называется скоростью обучения. Правильный выбор скорости обучения зависит от конкретной задачи и обычно осуществляется опытным путем; эта константа может также зависеть от времени, уменьшаясь по мере продвижения алгоритма.
Обычно этот алгоритм видоизменяется таким образом, чтобы включать слагаемое импульса (или инерции). Этот член способствует продвижению в фиксированном направлении, поэтому если было сделано несколько шагов в одном и том же направлении, то алгоритм "увеличивает скорость", что (иногда) позволяет избежать локального минимума, а также быстрее проходить плоские участки.
Таким образом, алгоритм действует итеративно, и его шаги принято называть эпохами. На каждой эпохе на вход сети поочередно подаются все обучающие наблюдения, выходные значения сети сравниваются с целевыми значениями и вычисляется ошибка. Значение ошибки, а также градиента поверхности ошибок используется для корректировки весов, после чего все действия повторяются. Начальная конфигурация сети выбирается случайным образом, и процесс обучения прекращается либо когда пройдено определенное количество эпох, либо когда ошибка достигнет некоторого определенного уровня малости, либо когда ошибка перестанет уменьшаться (пользователь может сам выбрать нужное условие остановки).
Переобучение и обобщение
Одна из наиболее серьёзных трудностей изложенного подхода заключается в том, что таким образом мы минимизируем не ту ошибку, которую на самом деле нужно минимизировать, - ошибку, которую можно ожидать от сети, когда ей будут подаваться совершенно новые наблюдения. Иначе говоря, мы хотели бы, чтобы нейронная сеть обладала способностью обобщать результат на новые наблюдения. В действительности сеть обучается минимизировать ошибку на обучающем множестве, и в отсутствие идеального и бесконечно большого обучающего множества это совсем не то же самое, что минимизировать "настоящую" ошибку на поверхности ошибок в заранее неизвестной модели явления (Bishop, 1995).
Сильнее всего это различие проявляется в проблеме переобучения, или слишком близкой подгонки. Это явление проще будет продемонстрировать не для нейронной сети, а на примере аппроксимации посредством полиномов, - при этом суть явления абсолютно та же.
Полином (или многочлен) - это выражение, содержащее только константы и целые степени независимой переменной. Вот примеры:
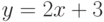
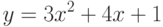
Графики полиномов могут иметь различную форму, причём чем выше степень многочлена (и, тем самым, чем больше членов в него входит), тем более сложной может быть эта форма. Если у нас есть некоторые данные, мы можем поставить цель подогнать к ним полиномиальную кривую (модель) и получить таким образом объяснение для имеющейся зависимости. Наши данные могут быть зашумлены, поэтому нельзя считать, что самая лучшая модель задается кривой, которая в точности проходит через все имеющиеся точки. Полином низкого порядка может быть недостаточно гибким средством для аппроксимации данных, в то время как полином высокого порядка может оказаться чересчур гибким, и будет точно следовать данным, принимая при этом замысловатую форму, не имеющую никакого отношения к форме настоящей зависимости (рис.11.10).
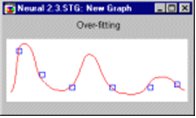
Нейронная сеть сталкивается с точно такой же трудностью. Сети с большим числом весов моделируют более сложные функции и, следовательно, склонны к переобучению. Сеть же с небольшим числом весов может оказаться недостаточно гибкой, чтобы смоделировать имеющуюся зависимость. Например, сеть без промежуточных слоёв на самом деле моделирует обычную линейную функцию.
Как же выбрать "правильную" степень сложности для сети? Почти всегда более сложная сеть дает меньшую ошибку, но это может свидетельствовать не о хорошем качестве модели, а о переобучении.
Ответ состоит в том, чтобы использовать механизм контрольной кросс-проверки. Мы резервируем часть обучающих наблюдений и не используем их в обучении по алгоритму обратного распространения. Вместо этого, по мере работы алгоритма, они используются для независимого контроля результата. В самом начале работы ошибка сети на обучающем и контрольном множестве будет одинаковой (если они существенно отличаются, то, вероятно, разбиение всех наблюдений на два множества было неоднородно). По мере того, как сеть обучается, ошибка обучения, естественно, убывает, и, пока обучение уменьшает действительную функцию ошибок, ошибка на контрольном множестве также будет убывать. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные и обучение следует остановить (в пакете ST Neural Networks можно задать автоматическую остановку обучения при появлении эффекта переобучения). Это явление чересчур точной аппроксимации в процессе обучения и называется переобучением. Если такое случилось, то обычно советуют уменьшить число скрытых элементов и/или слоев, ибо сеть является слишком мощной для данной задачи. Если же сеть, наоборот, была взята недостаточно богатой для того, чтобы моделировать имеющуюся зависимость, то переобучения, скорее всего, не произойдет, и обе ошибки - обучения и проверки - не достигнут достаточного уровня малости.
Описанные проблемы с локальными минимумами и выбором размера сети приводят к тому, что при практической работе с нейронными сетями, как правило, приходится экспериментировать с большим числом различных сетей, порой обучая каждую из них по нескольку раз (чтобы не быть введённым в заблуждение локальными минимумами) и сравнивая полученные результаты. Главным показателем качества результата является здесь контрольная ошибка. При этом, в соответствии с общенаучным принципом, согласно которому при прочих равных следует предпочесть более простую модель, из двух сетей с приблизительно равными ошибками контроля имеет смысл выбрать ту, которая меньше.
Необходимость многократных экспериментов ведёт к тому, что контрольное множество начинает играть ключевую роль в выборе модели, то есть становится частью процесса обучения. Тем самым ослабляется его роль как независимого критерия качества модели - при большом числе экспериментов есть риск выбрать "удачную" сеть, дающую хороший результат на контрольном множестве. Для того, чтобы придать окончательной модели должную надежность, часто (по крайней мере, когда объём обучающих данных это позволяет) поступают так: резервируют ещё одно - тестовое множество наблюдений. Итоговая модель тестируется на данных из этого множества, чтобы убедиться, что результаты, достигнутые на обучающем и контрольном множествах реальны, а не являются артефактами процесса обучения. Разумеется, для того чтобы хорошо играть свою роль, тестовое множество должно быть использовано только один раз: если его использовать повторно для корректировки процесса обучения, то оно фактически превратится в контрольное множество.
Итак, построение сети (после выбора входных переменных) состоит из следующих шагов:
- Выбрать начальную конфигурацию сети (например, один промежуточный слой с числом элементов в нём, равным полусумме числа входов и числа выходов - Наставник (Network Advisor) пакета ST Neural Networks предлагает такую конфигурацию по умолчанию).
- Провести ряд экспериментов с различными конфигурациями, запоминая при этом лучшую сеть (в смысле контрольной ошибки). В пакете ST Neural Networks предусмотрено автоматическое запоминание лучшей сети во время эксперимента. Для каждой конфигурации следует провести несколько экспериментов, чтобы не получить ошибочный результат из-за того, что процесс обучения попал в локальный минимум.
- Если в очередном эксперименте наблюдается недообучение (сеть не выдаёт результат приемлемого качества), попробовать добавить дополнительные нейроны в промежуточный слой (слои). Если это не помогает, попробовать добавить новый промежуточный слой.
- Если имеет место переобучение (контрольная ошибка стала расти), попробовать удалить несколько скрытых элементов (а возможно и слоёв).
Многократное повторение эвристических экспериментов в лучшем случае довольно утомительно, и поэтому в пакет ST Neural Networks включён специальный алгоритм автоматического поиска, который сам проделает эти действия. Автоматический конструктор сети - Automatic Network Designer проведет эксперименты с различным числом скрытых элементов, для каждой пробной архитектуры сети выполнит несколько прогонов обучения, отбирая при этом наилучшую сеть по показателю контрольной ошибки с поправкой на размер сети. В Автоматическом конструкторе сети реализованы сложные алгоритмы поиска, в том числе метод "искусственного отжига" (simulated annealing, Kirkpatrick et al., 1983), с помощью которых можно перепробовать сотни различных сетей, выделяя из них особо перспективные, либо быстро находить "грубое и простое" решение.
Отбор данных
На всех предыдущих этапах существенно использовалось одно предположение. А именно, обучающее, контрольное и тестовое множества должны быть репрезентативными (представительными) с точки зрения существа задачи (более того, эти множества должны быть репрезентативными каждое в отдельности). Известное изречение программистов "garbage in, garbage out" ("мусор на входе - мусор на выходе") нигде не справедливо в такой степени, как при нейросетевом моделировании. Если обучающие данные не репрезентативны, то модель, как минимум, будет не очень хорошей, а в худшем случае - бесполезной. Имеет смысл перечислить ряд причин, которые ухудшают качество обучающего множества:
Будущее непохоже на прошлое. Обычно в качестве обучающих берутся исторические данные. Если обстоятельства изменились, то закономерности, имевшие место в прошлом, могут больше не действовать.
Следует учесть все возможности. Нейронная сеть может обучаться только на тех данных, которыми она располагает. Предположим, что лица с годовым доходом более $100,000 имеют высокий кредитный риск, а обучающее множество не содержало лиц с доходом более $40,000 в год. Тогда едва ли можно ожидать от сети правильного решения в совершенно новой для нее ситуации.
Сеть обучается тому, чему проще всего обучиться. Классическим (возможно, вымышленным) примером является система машинного зрения, предназначенная для автоматического распознавания танков. Сеть обучалась на ста картинках, содержащих изображения танков, и на ста других картинках, где танков не было. Был достигнут стопроцентно "правильный" результат. Но когда на вход сети были поданы новые данные, она безнадежно провалилась. В чем же была причина? Выяснилось, что фотографии с танками были сделаны в пасмурный, дождливый день, а фотографии без танков - в солнечный день. Сеть научилась улавливать (очевидную) разницу в общей освещенности. Чтобы сеть могла результативно работать, ее следовало обучать на данных, где бы присутствовали все погодные условия и типы освещения, при которых сеть предполагается использовать - и это еще не говоря о рельефе местности, угле и дистанции съемки и т.д.
Несбалансированный набор данных. Коль скоро сеть минимизирует общую погрешность, важное значение приобретает пропорции, в которых представлены данные различных типов. Сеть, обученная на 900 хороших и 100 плохих примерах будет искажать результат в пользу хороших наблюдений, поскольку это позволит алгоритму уменьшить общую погрешность (которая определяется в основном хорошими случаями). Если в реальной популяции хорошие и плохие объекты представлены в другой пропорции, то результаты, выдаваемые сетью, могут оказаться неверными. Хорошим примером служит задача выявления заболеваний. Пусть, например, при обычных обследованиях в среднем 90% людей оказываются здоровыми. Сеть обучается на имеющихся данных, в которых пропорция здоровые/больные равна 90/10. Затем она применяется для диагностики пациентов с определённым жалобами, среди которых это соотношение уже 50/50. В этом случае сеть будет ставить диагноз чересчур осторожно и не распознает заболевание у некоторых больных. Если же, наоборот, сеть обучить на данных "с жалобами", а затем протестировать на "обычных" данных, то она будет выдавать повышенное число неправильных диагнозов о наличии заболевания. В таких ситуациях обучающие данные нужно скорректировать так, чтобы были учтены различия в распределении данных (например, можно повторять редкие наблюдения или удалить часто встречающиеся), или же видоизменить решения, выдаваемые сетью, посредством матрицы потерь (Bishop, 1995). Как правило, лучше всего постараться сделать так, чтобы наблюдения различных типов были представлены равномерно, и соответственно этому интерпретировать результаты, которые выдаёт сеть.
Как обучается многослойный персептрон
Мы сможем лучше понять, как устроен и как обучается многослойный персептрон (MLP), если выясним, какие функции он способен моделировать. Вспомним, что уровнем активации элемента называется взвешенная сумма его входов с добавленным к ней пороговым значением. Таким образом, уровень активации представляет собой простую линейную функцию входов. Эта активация затем преобразуется с помощью сигмоидной ( имеющей S-образную форму) кривой.
Комбинация линейной функции нескольких переменных и скалярной сигмоидной функции приводит к характерному профилю "сигмоидного склона", который выдает элемент первого промежуточного слоя MLP. На приведенном рисунке (рис.11.11) соответствующая поверхность изображена в виде функции двух входных переменных.
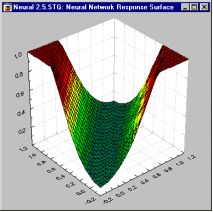
Элемент с большим числом входов выдаёт многомерный аналог такой поверхности. При изменении весов и порогов меняется и поверхность отклика. При этом может меняться как ориентация всей поверхности, так и крутизна склона. Большим значениям весов соответствует более крутой склон. Так, например, если увеличить все веса в два раза, то ориентация не изменится, а наклон будет более крутым.
В многослойной сети подобные функции отклика комбинируются друг с другом с помощью последовательного взятия их линейных комбинаций и применения нелинейных функций активации. На этом рисунке изображена типичная поверхность отклика для сети с одним промежуточным слоем, состоящим из двух элементов, и одним выходным элементом, для классической задачи "исключающего или" (Xor). Две разных сигмоидных поверхности объединены в одну поверхность, имеющую форму буквы "U".
Перед началом обучения сети весам и порогам случайным образом присваиваются небольшие по величине начальные значения. Тем самым отклики отдельных элементов сети имеют малый наклон и ориентированы хаотично - фактически они не связаны друг с другом. По мере того, как происходит обучение, поверхности отклика элементов сети вращаются и сдвигаются в нужное положение, а значения весов увеличиваются, поскольку они должны моделировать отдельные участки целевой поверхности отклика.
В задачах классификации выходной элемент должен выдавать сильный сигнал в случае, если данное наблюдение принадлежит к интересующему нас классу, и слабый - в противоположном случае. Иначе говоря, этот элемент должен стремиться смоделировать функцию, равную единице в той области пространства объектов, где располагаются объекты из нужного класса, и равную нулю вне этой области. Такая конструкция известна как дискриминантная функция в задачах распознавания. "Идеальная" дискриминантная функция должна иметь плоскую структуру, так чтобы точки соответствующей поверхности располагались либо на нулевом уровне, либо на высоте единица.
Если сеть не содержит скрытых элементов, то на выходе она может моделировать только одинарный "сигмоидный склон": точки, находящиеся по одну его сторону, располагаются низко, по другую - высоко. При этом всегда будет существовать область между ними (на склоне), где высота принимает промежуточные значения, но по мере увеличения весов эта область будет сужаться.
Такой сигмоидный склон фактически работает как линейная дискриминантная функция. Точки, лежащие по одну сторону склона, классифицируются как принадлежащие нужному классу, а лежащие по другую сторону - как не принадлежащие. Следовательно, сеть без скрытых слоёв может служить классификатором только в линейно-отделимых задачах (когда можно провести линию - или, в случае более высоких размерностей, - гиперплоскость, разделяющую точки в пространстве признаков).
Сеть, содержащая один промежуточный слой, строит несколько сигмоидных склонов - по одному для каждого скрытого элемента, - и затем выходной элемент комбинирует из них "возвышенность". Эта возвышенность получается выпуклой, т.е. не содержащей впадин. При этом в некоторых направлениях она может уходить на бесконечность (как длинный полуостров). Такая сеть может моделировать большинство реальных задач классификации (рис.11.12).
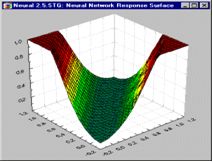
На этом рисунке показана поверхность отклика, полученная многослойным персептроном для решения задачи исключающего или: хорошо видно, что она выделяет область пространства, расположенную вдоль диагонали.
Сеть с двумя промежуточными слоями строит комбинацию из нескольких таких возвышенностей. Их будет столько же, сколько элементов во втором слое, и у каждой из них будет столько сторон, сколько элементов было в первом скрытом слое. После небольшого размышления можно прийти к выводу, что, используя достаточное число таких возвышенностей, можно воспроизвести поверхность любой формы - в том числе с впадинами и вогнутостями.
Как следствие наших рассмотрений мы получаем, что, теоретически, для моделирования любой задачи достаточно многослойного персептрона с двумя промежуточными слоями (в точной формулировке этот результат известен как теорема Колмогорова). При этом может оказаться и так, что для решения некоторой конкретной задачи более простой и удобной будет сеть с еще большим числом слоев. Однако, для решения большинства практических задач достаточно всего одного промежуточного слоя, два слоя применяются как резерв в особых случаях, а сети с тремя слоями практически не применяются.
В задачах классификации очень важно понять, как следует интерпретировать те точки, которые попали на склон или лежат близко от него. Стандартный выход здесь состоит в том, чтобы для пороговых значений установить некоторые доверительные пределы (принятия или отвержения), которые должны быть достигнуты, чтобы данных элемент считался "принявшим решение". Например, если установлены пороги принятия/отвержения 0.95/0.05, то при уровне выходного сигнала, превосходящем 0.95 элемент считается активным, при уровне ниже 0.05 - неактивным, а в промежутке – "неопределённым".
Имеется и более тонкий (и, вероятно, более полезный) способ интерпретировать уровни выходного сигнала: считать их вероятностями. В этом случае сеть выдает несколько большую информацию, чем просто "да/нет": она сообщает нам, насколько (в некотором формальном смысле) мы можем доверять её решению. Разработаны (и реализованы в пакете ST Neural Networks) модификации метода MLP, позволяющие интерпретировать выходной сигнал нейронной сети как вероятность, в результате чего сеть по существу учится моделировать плотность вероятности распределения данного класса. При этом, однако, вероятностная интерпретация обоснована только в том случае, если выполнены определенные предположения относительно распределения исходных данных (конкретно, что они являются выборкой из некоторого распределения, принадлежащего к семейству экспоненциальных распределений; Bishop, 1995). Здесь, как и ранее, может быть принято решение по классификации, но, кроме того, вероятностная интерпретация позволяет ввести концепцию "решения с минимальными затратами".
Виталий Елин
|
Здравствуйте! Здесь вначале говориться что выдается диплом, а внизу страницы сказано что нет |
{kind=link}
{kind=link}