| Гамбия |
Инспектор
Вы можете этот курс.
Опубликован: 06.03.2012 | Уровень: специалист | Доступ: платный | ВУЗ: Санкт-Петербургский государственный политехнический университет
Лекция 8:
Концепции языка DMX
< Самостоятельная работа 9 || Лекция 8 || Лекция 9 >
Аннотация: В лекции рассматриваются базовые понятия языка DMX – атрибут, вариант, структура. Приводится обзор используемых типов данных и содержимого.
Ключевые слова: DMX, атрибут, алгоритм, дискретизация, синоним, анализ, множества, детализация, объект, Профессия, место, таблица, расстояние, ключ, выходные данные, входные данные, источник данных, представление, кэш, cube, SQL, server, тип данных, логический, тип содержимого, discretization, classify, значение, точность, параметр, сегменты, список
В предыдущих разделах курса мы познакомились с некоторыми важными понятиями интеллектуального анализа данных. Теперь пришло время собрать их воедино и рассмотреть, каких описание может быть произведено на используемом для запросов к службе AnalysisServices языке интеллектуального анализа данных - DMX.
Наименьшей логической единицей работы с данными при интеллектуальном анализе является атрибут, который содержит некоторую "элементарную" информацию об анализируемом примере. Например, возраст клиента. Для алгоритмов DM существует два основных типа атрибутов [1]:
- категориальные (дискретные), принимающие значения из некоторого фиксированного конечного набора значений;
- непрерывные числовые атрибуты.
Дополнительные типы атрибутов основаны на базовых. К ним, в частности, относятся упорядоченный (или циклический) тип. Такой атрибут является категориальным, но для него задан определенный порядок значений (например, размеры одежды). Дискретизированные атрибуты это специальный вариант категориального типа, полученный из непрерывного путем разбиения на диапазоны.Например, упрощенный алгоритм Байеса не может обрабатывать непрерывные атрибуты, поэтому потребуется дискретизация. В ряде случаев говорят о типе содержимого, что можно рассматривать как синоним термина "тип атрибута".
С каждым категориальным атрибутом связан набор его значений (или состояний). Например, атрибут "Город проживания" может принимать значения: "Санкт-Петербург", "Москва" и т.д. На этапах подготовки и изучения данных важно провести анализ множества состояний атрибутов и, при необходимости, внести коррективы. Например, если в одних случаях город записан как "Санкт-Петербург", а в других "С-Петербург", нужно привести все к единому формату(иначе алгоритм интеллектуального анализа будет рассматривать это как разные состояния). Кроме того, возможно для анализа не нужна столь подобная детализация по городам, а интерес представляет, является ли человек жителем крупного города или нет.
В случае аналитических служб Microsoft SQLServer, атрибуты также могут иметь состояния "Missing" и "Existing". Первый указывает на то, что в строке данных атрибут отсутствует (или состояние не определено), второй - что атрибут присутствует.
Вариант определяется как отдельный пример, предоставляемый алгоритму интеллектуального анализа данных [1]. Он состоит из набора атрибутов с соответствующими значениями и во многих случаях описывает объект или событие. Нередко вариант можно представить строкой в таблице, столбцы которой - атрибуты. Пусть, например, решается задача классификации потенциального банковского заемщика при принятии решения о выдаче кредита. В этот случае вариант содержит известные данные об этом клиенте (размер заработка, профессия, место работы …) и вполне представим в виде строки таблицы.
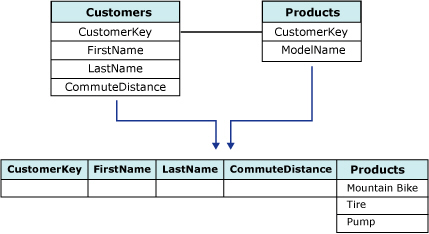
В то же время, MS SQLServer и DMX позволяют использовать вложенные таблицы, что позволяет описывать более сложные по структуре варианты. Это можно проиллюстрировать на следующем примере [8]. Пусть требуется провести анализ товаров, купленных каждым из клиентов. При этом имеется возможность связать данные о покупках с информацией о покупателе. Исходные данные берутся из двух реляционных таблиц, связанных внешним ключом ( рис. 17.1): таблица Customers(Заказчики) с полями CustomerKey(КлючЗаказчика), FirstName(Имя), LastName(Фамилия), CommuteDistance(Расстояние до работы) и таблица Products (Товары) с полями CustomerKey(внешний ключ, ссылающийся на Customers) и ModelName (Название Модели). Как видно на рисунке, сформированный вариант может содержать много товаров купленных одним клиентом и отличается по виду строки реляционной таблицы.
Ключ варианта используется для идентификации варианта. Зачастую в этом качестве может использоваться исходный ключ таблицы, из которой берутся данные для анализа. На рис. 17.1 ключом может выступать столбец CustomerKey.
Вложенный ключ позволяет идентифицировать объект, описываемый во вложенной таблице. В нашем примере это будет название товара (если бы там были еще какие-то атрибуты - цена, цвет и т.д. - они относились бы именно к этому товару).
Атрибут может рассматриваться алгоритмом интеллектуального анализа в качестве входа, выхода или входа и выхода одновременно. Язык DMX позволяет это указать в процессе описания модели. На стадии обучения алгоритму предоставляются как входные, так и выходные данные. На стадии прогнозирования - алгоритм получает входные данные и возвращает выходные.
Теперь рассмотрим вопрос получения исходных данных для интеллектуального анализа. Анализировать можно данные из реляционных таблиц и других источников, если они специальным образом описаны в качестве представления источника данных в службах AnalysisServices. Сначала определяется источник данных (DataSource), а потом его представление (DataSourceView). Представление источника данных позволяет сочетать различные источники данных и работать с вложенными таблицами.Один из способов определить источник данных - использование соответствующего мастера в среде BI DevStudio, как это делается в "Начало работы в BIDevStudio" .
Службы AnalysisServices считывают данные из источника в специальный кэш. Помещенные в кэш данные можно сохранить и использовать при создании других моделей интеллектуального анализа или удалить, чтобы освободить место в хранилище.
Данные могут браться не только из реляционных баз данных, но и из аналитических кубов (cube).
Следующий шаг - создание структуры. Это понятие уже встречалось ранее, но рассмотрим его еще раз более подробно с примерами описания на языке DMX.
Структура интеллектуального анализа данных может быть представлена как совокупность исходных данных и описания способов их обработки. Структура содержит модели, которые используются для анализа ее данных.
При создании модели или структуры интеллектуального анализа данных в Microsoft SQL Server AnalysisServices, необходимо определить типы данных для каждого столбца в структуре[9]. Тип данных сообщает модулю интеллектуального анализа, являются ли данные в источнике числовыми или текстовыми, и как их обрабатывать. Например, если в столбце содержатся числовые данные, то можно указать, что числа следует считать целыми, либо использовать десятичные разряды. Типы данных перечислены в таблице 17.1: текстовый (Text), вещественный числовой (Long), "длинный" вещественный числовой (Double), логический (Boolean) и дата (Date). Они стандартны и в особых комментариях не нуждаются. Единственное, хотелось бы обратить внимание на то, что типов данных здесь меньше, чем в SQL, и в процессе подготовки данных из реляционных таблиц к анализу, часто производится преобразование к наиболее подходящему типу.
Каждый тип данных поддерживает один или несколько типов содержимого. Задавая тип содержимого, можно настраивать метод, которым данные в столбце обрабатываются или вычисляются в модели интеллектуального анализа данных. В таблице 17.1 указано, какие типы содержимого могут соответствовать различным типам данных.
Ниже приведены характеристики типов содержимого и указаны основные особенности их использования [1,9,10].
Тип содержимого Discrete указывает на то, что атрибут категориальный (дискретный). Одна из особенностей данного типа - принимается, что к этим значениям не применимо упорядочение. Кроме того, даже если значения, используемые для заполнения дискретного столбца, являются числовыми, не предусмотрена возможность вычисления дробных значений.
Тип Continuous - непрерывные числовые значения. Иначе говоря, в столбце содержатся значения, которые представляют числовые данные в масштабе, допускающем применение промежуточных значений. В качестве непрерывного значения может рассматриваться, например, объем продаж за указанный период или значение среднесуточной температуры воздуха. Если известно распределение значений непрерывного показателя, то потенциально можно увеличить точность анализа, указав его при определении структуры интеллектуального анализа данных. Данный параметр будет применим ко всем моделям, основанным на структуре.
Алгоритмы интеллектуального анализа данных Microsoft могут работать со следующими типами распределений:
- normal - нормальное на основе значений столбца, содержащего непрерывные данные, может быть построена гистограмма с нормальным Гауссовским распределением;
- lognormal - логнормальное - на основе значений столбца, содержащего непрерывные данные, может быть построена гистограмма с нормально распределенной функцией логарифма значений;
- uniform - равномерное распределение значений столбца (все значения являются равновероятными).
Тип Discretized - указывает на то, что это дискретизированное значение. Дискретизация - это процесс распределения значений непрерывного набора данных по сегментам так, чтобы получилось ограниченное число допустимых значений. Дискретизировать можно только числовые данные.Следовательно, дискретизированный тип содержимого показывает, что столбец содержит значения, представляющие группы или сегменты значений, полученных из непрерывного столбца. Сегменты воспринимаются как упорядоченные дискретные значения.
Дискретизацию данных можно провести вручную, чтобы получить необходимые сегменты, либо можно использовать методы дискретизации, предоставляемые службами SQL Server AnalysisServices. В некоторых алгоритмах дискретизация выполняется автоматически.
Для типа содержимого Discretized можно явно указать параметры дискретизации - способ разбиения на сегменты и их число. Способы разбиения могут быть следующими:
- AUTOMATIC (по умолчанию) - службы AnalysisServices определяют, какой метод дискретизации использовать;
- EQUAL_AREAS - алгоритм делит данные на группы, содержащие равное число значений;
- CLUSTERS - алгоритм разделяет данные на группы путем создания выборки обучающих данных, инициализации по ряду случайных точек и дальнейшего запуска несколько итераций алгоритма кластеризации (Microsoft).
Что касается числа сегментов, то по умолчанию система пытается создать 5 сегментов, а если данных на 5 сегментов не хватает, делается попытка создать меньшее число. При явном задании параметров описание дискретизированного столбца при создании структуры может быть примерно следующим:
[SalaryDisc] LONGDISCRETIZED (EQUAL_AREAS,4)
Тип содержимого Key (ключ) означает, что столбец уникально определяет строку (вариант). Ключ варианта не используется для анализа, а нужен для отслеживания записей.
Вложенные таблицы также имеют ключи, но ключ вложенной таблицы предназначен для других целей. Если столбец вложенной таблицы представляет собой атрибут, который должен быть проанализирован, то для него следует определить тип содержимого Key. Значения в ключе вложенной таблицы должны быть уникальными для каждого варианта, но во всем множестве вариантов могут быть повторяющиеся значения. Например, если анализируются продукты, приобретенные клиентами, то для столбца CustomerID в таблице вариантов нужно задать тип содержимого key и задать тип содержимого key для столбца PurchasedProducts во вложенной таблице.
Тип содержимого keysequence может применяться только в моделях кластеризации последовательностей. Если задан тип содержимого keysequence, значит, столбец содержит значения, представляющие последовательность событий. Значения упорядочены, но не должны обязательно находиться на одинаковом расстоянии друг от друга.
Тип содержимого keytime может применяться только в моделях временных рядов. Если он задан, то это означает, что значения упорядочены и представляют временную шкалу.
Тип содержимого Table указывает, что столбец содержит другую таблицу данных (вложенную таблицу). Применительно к любой конкретной строке в таблице вариантов этот столбец может содержать несколько значений (т.е. несколько строк вложенной таблицы), причем все они связаны с записью родительского варианта.
Вариант может включать несколько вложенных таблиц. Например, основная таблица вариантов содержит список клиентов. Один ее столбец содержит вложенную таблицу с перечислением сделанных клиентом покупок, а другой - перечень увлечений клиента.Примеры определения подобных структур будут приведены в следующей лекции.
Тип содержимого Cyclical означает, что в столбце содержатся значения, представляющие циклический упорядоченный набор. Например, циклическим упорядоченным набором являются пронумерованные дни недели, поскольку день с номером 1 следует за днем с номером 7.Циклические столбцы атрибутов считаются упорядоченными и дискретными в терминах типов содержимого. Однако большинство алгоритмов обрабатывает циклические значения как дискретные и не выполняет особой обработки.
Тип содержимого Ordered также означает, что столбец содержит значения, определяющие последовательность или порядок. Однако в данном типе содержимого значения, используемые для упорядочивания, не подразумевают наличия никаких связей (по дистанции или по силе) между значениями в наборе. Например, если упорядоченный столбец атрибутов содержит сведения об уровне квалификации по шкале от 1 до 5, он не несет сведений о разнице между уровнями квалификации; уровень 5 не обязательно в пять раз лучше уровня 1. Упорядоченные столбцы атрибутов считаются дискретными и большинство алгоритмов так их и обрабатывает.
Классифицированные столбцы (тип Classified) позволяют работать с данными, описывающими другой столбец в модели. Например, можно задать классифицированный столбец, в котором будут содержаться среднеквадратичные отклонения другого столбца модели, например столбца с данными обо всех покупках, совершенных клиентом за календарный год.Тип данных, используемый в классифицированном столбце, должен быть либо Long, либо Double. Ниже описаны допустимые типы содержимого:
- PROBABILITY - значение в столбце является вероятностью связанного значения и представлено числом от 0 до 1;
- VARIANCE - значение в столбце является отклонением связанного значения;
- STDEV - значение в столбце является среднеквадратичным отклонением связанного значения;
- PROBABILITY_VARIANCE - значение в столбце является отклонением вероятности для связанного значения;
- PROBABILITY_STDEV - значение в столбце является среднеквадратичным отклонением вероятности для связанного значения;
- SUPPORT - значение в столбце является весом, коэффициентом репликации объекта, связанного значения.
ВMS SQLServer 2008 R2 алгоритмы, предоставленные службами Службы AnalysisServices, не поддерживают использование классифицированных столбцов.
Типы содержимого Time и Sequence поддерживаются только алгоритмами сторонних производителей (не Microsoft).
< Самостоятельная работа 9 || Лекция 8 || Лекция 9 >