


| Гамбия |
Инспектор
Вы можете этот курс.
Опубликован: 06.03.2012 | Уровень: специалист | Доступ: платный | ВУЗ: Санкт-Петербургский государственный политехнический университет
Самостоятельная работа 9:
Построение модели кластеризации, трассировка и перекрестная проверка
< Самостоятельная работа 8 || Самостоятельная работа 9 || Лекция 8 >
Аннотация: В лабораторной работе рассматривается построение модели интеллектуального анализа данных, использующей алгоритм кластеризации, проводится анализ модели с использованием перекрестной проверки и рассматриваются предоставляемые DataMiningClient возможности по выполнению трассировки запросов к серверу.
Ключевые слова: Интернет, список, excel, файл, лист, ПО, источник данных, таблица, определение, доступ, процент, диаграмма, анализ, значение, стандартное отклонение, параметр, меню, кластер, множества, атрибут, вероятность, сервер, XML, DMX, запрос, enterprise, developer, разделы, кластеризация, стабильность
Рассмотрим еще ряд возможностей, предоставляемых надстройками интеллектуального анализа данных.
Пусть необходимо провести сегментацию клиентов Интернет магазина, список которых находится в файле Excel. Если использовать TableAnalysisTools, для решения этой задачи надо применить инструмент DetectCategories (см. "Использование инструментов "AnalyzeKeyInfluencers" и "DetectCategories"" ). Также можно воспользоваться средствами DataMiningClientforExcel, где выбрать инструмент Cluster ( рис. 16.1).
Итак, откроем файл с образцами данных, идущий с надстройками интеллектуального анализа, перейдем на лист TableAnalysisToolsSample (или можно с первого листа с оглавлением перейти по ссылке "Образцы данных для средств анализа таблиц") и запустим инструмент Cluster.
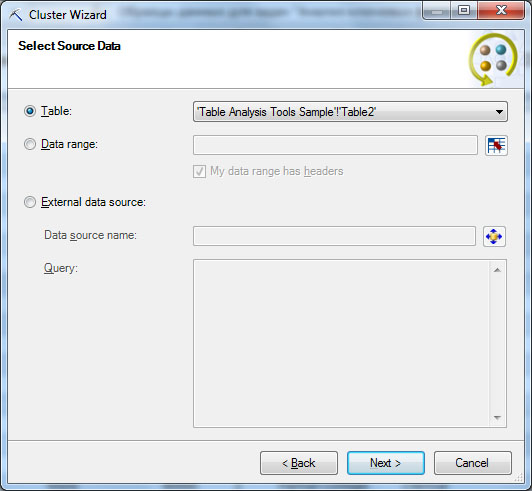
Первое окно кратко описывает суть задачи кластеризации и указывает на то, что для работы мастера необходимо подключение к MS SQLServer(которое у нас было настроено ранее). Следующее окно ( рис. 16.2-1) позволяет указать источник данных - в нашем случае это электронная таблица Excel, после чего можно выбрать число кластеров ( рис. 16.2-2) или указать автоматическое определение, а также используемые столбцы входных данных. Здесь сбросим флажки рядом со столбцами ID и PurchasedBike.
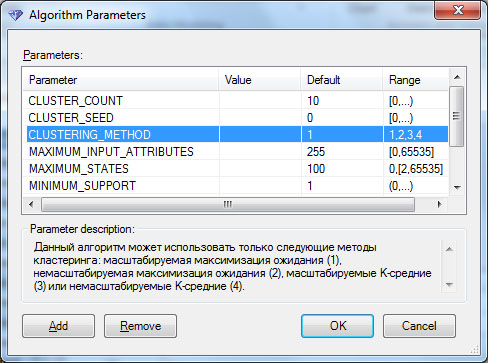
Описанный выше выбор входных параметров обусловлен тем, что столбец с уникальным идентификатором покупателя может только помешать алгоритму кластеризации, а купил ли клиент велосипед или нет, нас сейчас не интересует. Кроме того, нажав в этом окне кнопку Parameters… можно получить доступ к настройке параметров алгоритма кластеризации ( рис. 16.3) и, например, поменять используемый по умолчанию метод кластеризации.
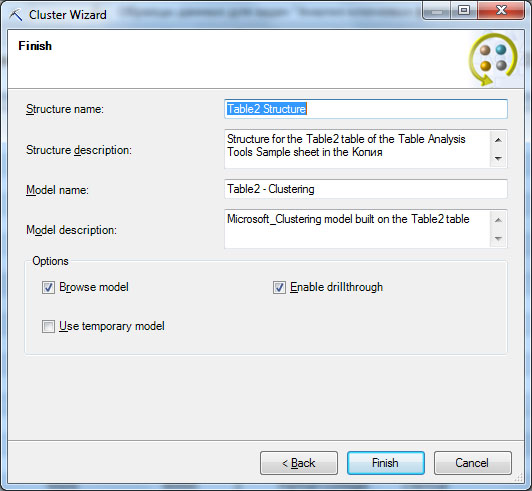
Более подробно настройки алгоритма кластеризации обсуждаются в теоретической части курса. Следующее окно мастера позволяет указать процент данных, резервируемых для задач тестирования. И наконец, в последнем окне мастера ( рис. 16.4) можно задать имя структуры и модели, указать, открывать ли просмотр модели, разрешить ли детализацию, использовать ли временные модели (по умолчанию - нет).
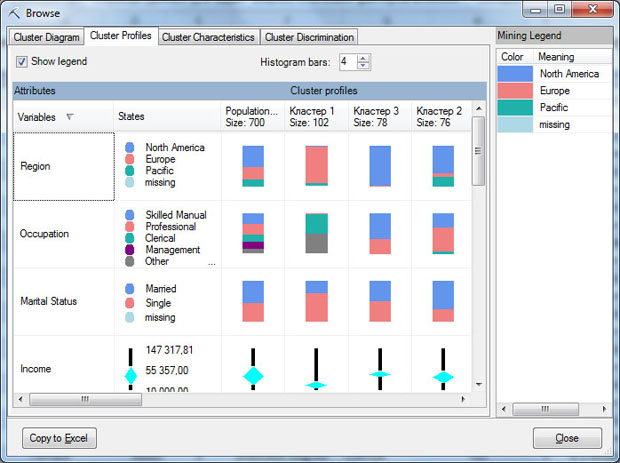
После нажатия кнопки Finish будет создана структура и модель, после чего модель будет обработана и открыта для просмотра в окне Browser ( рис. 16.5-1 - рис. 16.5-4). Диаграмма кластеров ( рис. 16.5-1) отображает все кластеры в модели, в нашем примере их 11. Заливка линии, соединяющей кластеры, показывает степень их сходства. Светлая или отсутствующая заливка означает, что кластеры не очень схожи. Можно выбрать анализ по отдельному атрибуту или по всей совокупности (Population).
Нажав кнопку CopytoExcel можно получить изображение на отдельный лист таблицы Excel.
Окно ClusterProfile позволяет просмотреть распределение значений атрибутов в каждом кластере. Например, на рис. 16.5-1 видно, что большая часть клиентов, отнесенных к кластеру 1, проживают в регионе Europe, а большинство из кластера 3 относится к региону NorthAmerica. Дискретные атрибуты представлены в виде цветных линий, непрерывные атрибуты в виде диаграммы ромбов, представляющей среднее значение и стандартное отклонение в каждом кластере. Параметр Histogram bars ("Столбцы гистограммы") управляет количеством столбцов, видимых на гистограмме. Если доступно больше столбцов, чем выбрано для отображения, то наиболее важные столбцы сохраняются, а оставшиеся группируются в сегмент серого цвета.
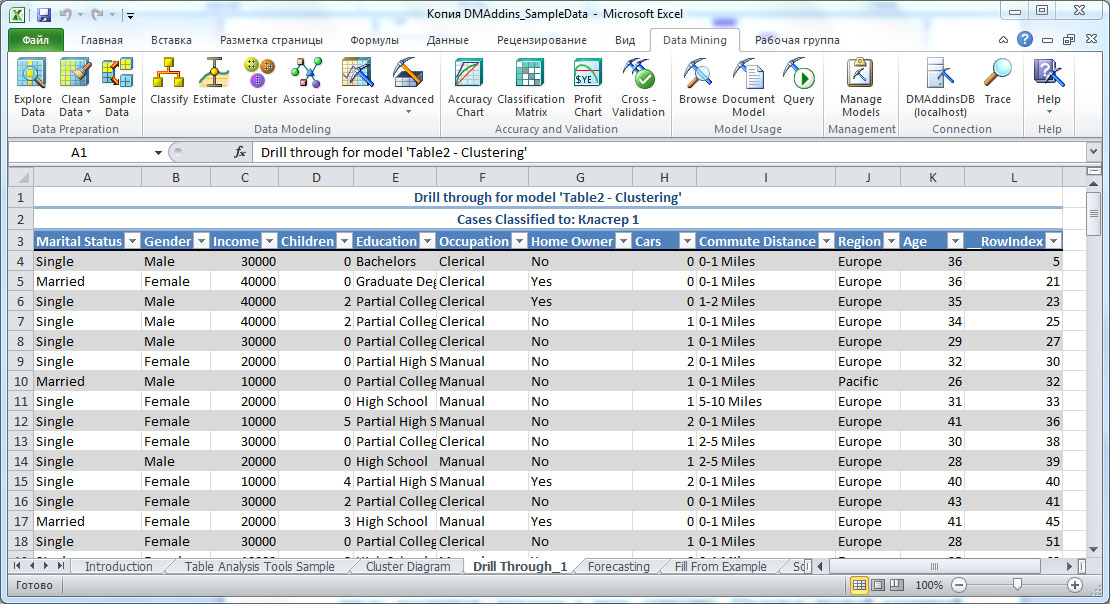
В заголовке под названием каждого кластера указывает число вариантов, которые к нему отнесены. Щелкнув правой клавишей мыши на заголовке столбца, можно вызвать контекстное меню, позволяющее в частности переименовать соответствующий кластер. Кроме того, из контекстного меню, выбрав опцию DrillThroughModelColumn, можно получить детализацию модели (результаты выводятся на отдельный лист Excel). Например, на рис. 16.6 показаны все варианты, отнесенные к кластеру 1.
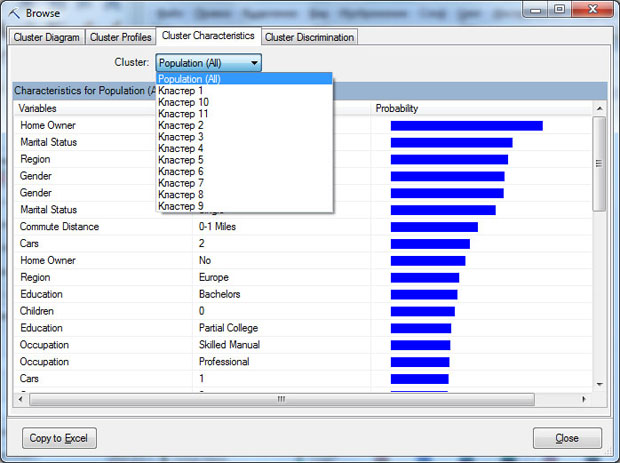
Но вернемся к окнам Modelbrowser. Окно ClusterCharacteristics позволяет просмотреть наиболее вероятные значения атрибутов для всего множества вариантов (Population) и для каждого кластера (если выбрать кластер в выпадающем списке). В последнем случае, столбцы сортируются по степени важности данного атрибута для кластера. Например, в рассмотренном выше кластере 1 на первом месте будет находиться атрибут Region со значением Europe. При этом, вероятность того что клиент, отнесенный алгоритмом к этой категории, проживает именно в Европе оценивается как очень высокая.
Окно ClusterDiscrimination позволяет провести попарное сравнение двух кластеров ( рис. 16.5-4) или выбранного кластера и всех остальных вариантов.
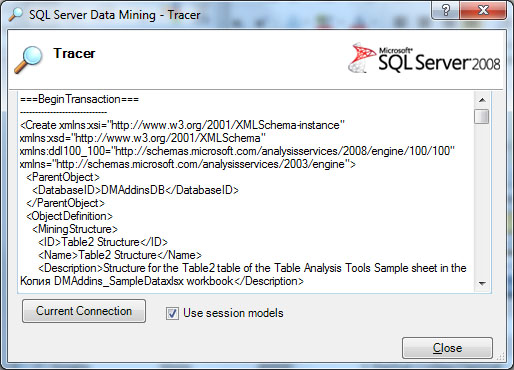
Теперь перейдем к анализу того, что же происходит на сервере. В этом поможет инструмент Trace, расположенный в ленте DataMining в разделе Connection. Если нажать данную кнопку, откроется окно, в котором отображается содержимое отправляемых на сервер запросов ( рис. 16.7).
Если проанализировать текст запросов, видно, что первая часть транзакции - это описание на XML создаваемой структуры и модели, вторая часть, которая приводится ниже - это DMX запрос на заполнение структуры (и, соответственно, обработку модели).
INSERT INTO MINING STRUCTURE [Table2 Structure] (__RowIndex,
[Marital Status],
[Gender],
[Income],
[Children],
[Education],
[Occupation],
[Home Owner],
[Cars],
[Commute Distance],
[Region],
[Age]) @ParamTable
ParamTable = Microsoft.SqlServer.DataMining.Office.Excel.ExcelDataReader
Листинг
16.1.
DMX-запрос на обработку структуры
Использование трассировки позволяет глубже разобраться в особенностях работы надстроек интеллектуального анализа и при возникновении ошибок выявить их причины.
Задание 1. По аналогии с рассмотренным примером создайте модель кластеризации. Изучите и проанализируйте полученные результаты. Отройте окно трассировки, проанализируйте отправляемые на сервер запросы.
Теперь рассмотрим инструмент перекрестной проверки Cross-Validation(надо отметить, что перекрестная проверка доступна при использовании SQLServer версии Enterprise или Developer). Суть ее заключается в том, что множество вариантов, которые использует модель, разбивается на непересекающиеся подмножества (разделы), для каждого из которых производится обработка модели и полученные результаты сравниваются с теми, что были на исходном множестве вариантов. Если результаты близки, можно говорить об удачной модели интеллектуального анализа (исходных данных хватило, результат анализа/прогноза достаточно стабилен).
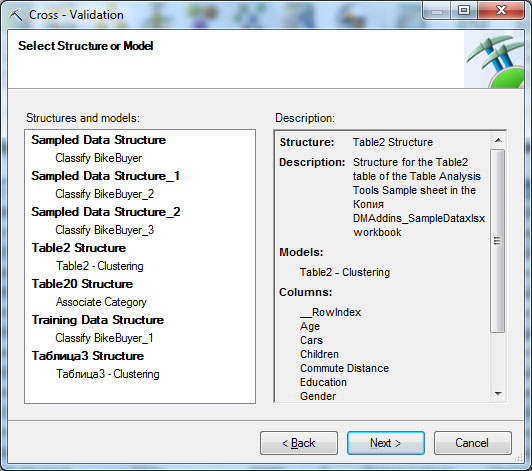
В разделе Accuracy and Validation выберем инструмент Cross-Validation. Первое окно мастера сообщает о сути выполняемой проверки. Во втором окне ( рис. 16.8) производится выбор модели для перекрестной проверки. Укажем нашу модель кластеризации - Table2-Clustering.
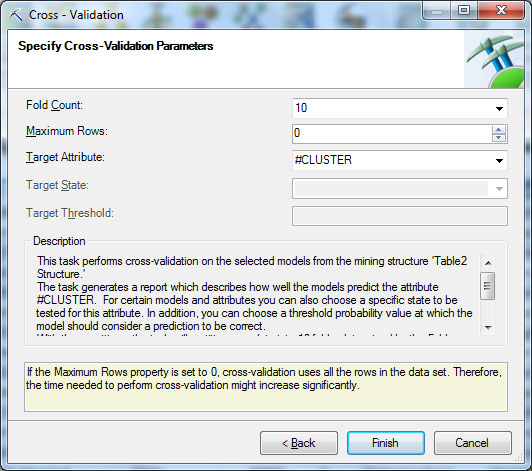
После выбора модели нужно указать параметры проводимой перекрестной проверки. В частности, указывается число разделов с данными для перекрестной проверки (FoldCount, по умолчанию 10), максимальное число вариантов, используемых при проверке (значение MaximumRows=0 указывает на то, что будут использоваться все; если исходных данных много, при использовании всех данных перекрестная проверка может занять продолжительное время), целевой атрибут (TargetAttribute). На рисунке стоит TargetAttribute#Cluster, т.е. номер кластера, к которому принадлежит вариант. Суть проверки будет заключаться в том, что выполняется кластеризация в рамках отдельного раздела и полученный номер кластера, к которому отнесен вариант, будет сравниваться с номером кластера, полученным при обработке модели с использованием всего множества вариантов. Совпадение говорит о том, что модель хорошая (правильно определены имеющиеся шаблоны).
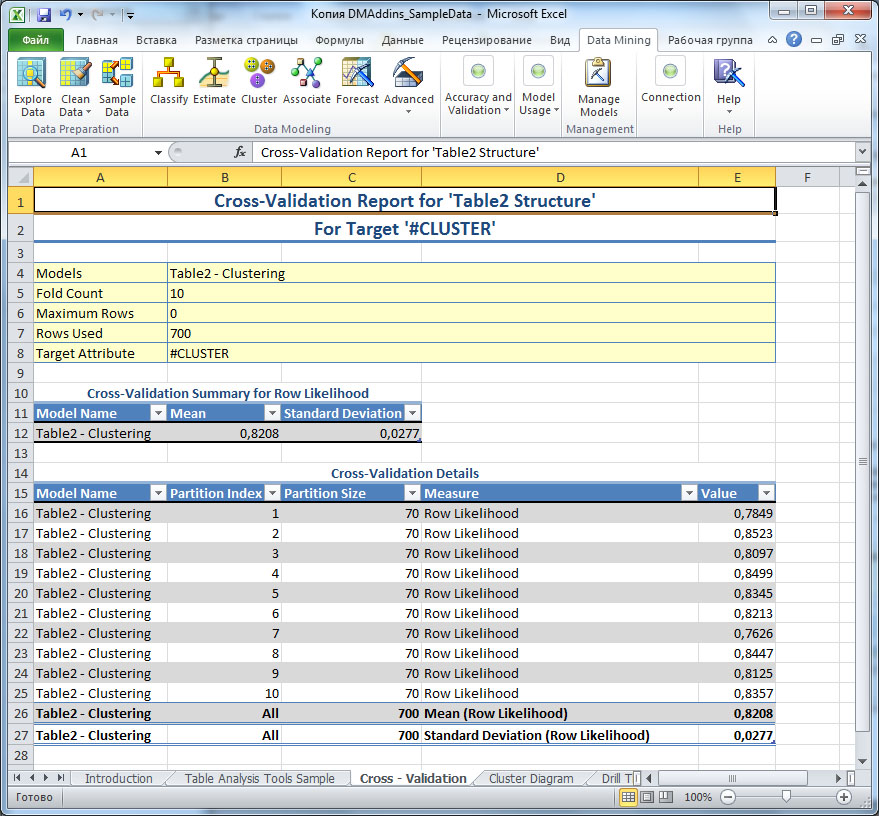
По результатам выполнения перекрестной проверки формируется отчет ( рис. 16.10). В нем показывается, сколько вариантов использовалось для проверки (на рисунке - 700), какие разделы были сформированы (в нашем примере 10 разделов по 70 строк данных), результаты проведенного анализа. Отчет ( рис. 16.10) показал, что в среднем, результаты, полученные при анализе по разделам, более чем в 82% случаев совпадают с результатами исходной модели. Небольшой разброс значений для разных разделов, указывает на стабильность получаемого результата, т.е. построенная модель интеллектуального анализа может быть признана удачной.
Задание 2. Выполните перекрестную проверку для созданной модели интеллектуального анализа. Опишите и проанализируйте полученные результаты.
< Самостоятельная работа 8 || Самостоятельная работа 9 || Лекция 8 >