Инспектор
Вы можете этот курс.
Опубликован: 06.08.2007 | Уровень: профессионал | Доступ: платный
Лекция 5:
Синтаксический анализ
Разбор сверху-вниз (предсказывающий разбор)
Алгоритм разбора сверху-вниз
Пусть дана КС-грамматика G = (N; T; P; S). Рассмотрим разбор сверху-вниз (предсказывающий разбор) для грамматики G.
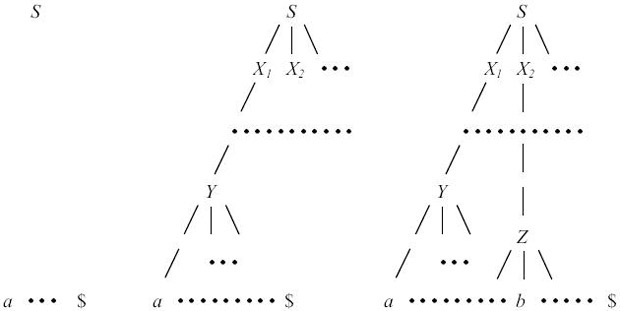
Главная задача предсказывающего разбора - определение правила вывода, которое нужно применить к нетерминалу. Процесс предсказывающего разбора с точки зрения построения дерева разбора проиллюстрирован на рис. 4.1
Фрагменты недостроенного дерева соответствуют сентенциальным формам. Вначале дерево состоит только из одной вершины, соответствующей аксиоме S. В этот момент по первому символу входной цепочки предсказывающий анализатор должен определить правило S -> X1X2 ... ; которое должно быть применено к S. Затем необходимо определить правило, которое должно быть применено к X1, и т.д., до тех пор, пока в процессе такого построения сентенциальной формы, соответствующей левому выводу, не будет применено правило Y -> a ...: Этот процесс затем применяется для следующего самого левого нетерминального символа сентенциальной формы.
На рис. 4.2 условно показана структура предсказывающего анализатора, который определяет
очередное правило с помощью таблицы. Такую таблицу можно построить и непосредственно по грамматике. Таблично-управляемый предсказывающий анализатор имеет входную ленту, управляющее устройство (программу), таблицу анализа, магазин (стек) и выходную ленту. Входная лента содержит анализируемую строку, заканчивающуюся символом $ - маркером конца строки. Выходная лента содержит последовательность примененных правил вывода.

Таблица анализа - это двумерный массив M[A; a], где A - нетерминал, и a - терминал или символ $. Значением M[A; a] может быть некоторое правило грамматики или элемент "ошибка".
Магазин может содержать последовательность символов грамматики с $ на дне. В начальный момент магазин содержит только начальный символ грамматики на верхушке и $ на дне.
Анализатор работает следующим образом. Вначале анализатор находится в конфигурации, в которой магазин содержит S$, на входной ленте w$ ( w - анализируемая цепочка), выходная лента пуста. На каждом такте анализатор рассматривает X - символ на верхушке магазина и a - текущий входной символ. Эти два символа определяют действия анализатора. Имеются следующие возможности.
- Если X=a=$, анализатор останавливается, сообщает об успешном окончании разбора и выдает содержимое выходной ленты.
- Если
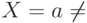 , анализатор удаляет X из магазина и
продвигает указатель входа на следующий входной символ.
, анализатор удаляет X из магазина и
продвигает указатель входа на следующий входной символ. - Если X - терминал, и
 , то анализатор
останавливается и сообщает о том, что входная цепочка не
принадлежит языку.
, то анализатор
останавливается и сообщает о том, что входная цепочка не
принадлежит языку. - Если X - нетерминал, анализатор заглядывает в
таблицу M[X; a]. Возможны два случая:
- Значением M[X; a] является правило для X. В этом случае анализатор заменяет X на верхушке магазина на правую часть данного правила, а само правило помещает на выходную ленту. Указатель входа не передвигается.
- Значением M[X; a] является "ошибка". В этом случае анализатор останавливается и сообщает о том, что входная цепочка не принадлежит языку. Работа анализатора может быть задана следующей программой:
Поместить '$', затем S в магазин;
do
{X=верхний символ магазина;
if (X - терминал)
if (X==InSym)
{удалить X из магазина;
InSym=очередной символ;
}
else {error(); break;}
else if (X - нетерминал)
if (M[X,InSym]=="X->Y1Y2...Yk")
{удалить X из магазина;
поместить Yk,Yk-1,...Y1 в магазин
(Y1 на верхушку);
вывести правило X->Y1Y2...Yk;
}
else {error(); break;} /*вход таблицы M пуст*/
}
while (X!='$'); /*магазин пуст*/
if (InSym != '$') error(); /*Не вся строка прочитана*/Пример 4.3. Рассмотрим грамматику арифметических выражений G=({E; E', T, T', F}, {id, +, *, (, )}, P, E) с правилами:
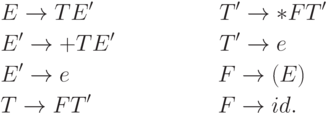
В таблица 4.3 приведена предсказывающего анализатора для этой грамматики. Пустые клетки таблицы соответствуют элементу "ошибка".
| Нетерминал | Входной символ | |||||
| id | + | * | ( | ) | $ | |
| E | E->TE' | E->TE' | ||||
| E' | E'->+TE' | E'->e | E'->e | |||
| T | T->FT' | T->FT' | ||||
| T' | T'->e | T'->*FT' | T'->e | T'->e | ||
| F | F->id | F->(E) | ||||
При разборе входной цепочки id + id * id$ анализатор совершает последовательность шагов, изображенную в таблица 4.4. Заметим, что анализатор осуществляет в точности левый вывод. Если за уже просмотренными входными символами поместить символы грамматики в магазине, то можно получить в точности левые сентенциальные формы вывода. Дерево разбора для этой цепочки приведено на рис. рис. 4.3.
| Магазин | Вход | Выход |
| E$ | id + id * id$ | |
| TE'$ | id + id * id$ | E -> TE' |
| FT'E'$ | id + id * id$ | T -> FT' |
| id T'E'$ | id + id * id$ | F -> id |
| T'E'$ | +id * id$ | |
| E'$ | +id * id$ | T' -> e |
| +TE'$ | +id * id$ | E' -> +TE |
| TE'$ | id * id$ | |
| FT'E'$ | id * id$ | T -> FT' |
| id T'E'$ | id * id$ | F -> id |
| T'E'$ | *id$ | |
| *F'T'E'$ | *id$ | T' -> *FT' |
| FT'E'$ | id$ | |
| id T'E'$ | id$ | F -> id |
| T'E'$ | $ | |
| E'$ | $ | T' -> e |
| $ | $ | E' -> e |
Функции FIRST и FOLLOW
При построении таблицы предсказывающего анализатора нам потребуются две функции - FIRST и FOLLOW.
Пусть G = (N, T, P, S) - КС-грамматика. Для  -
произвольной цепочки, состоящей из символов грамматики,
определим
-
произвольной цепочки, состоящей из символов грамматики,
определим 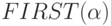 как множество терминалов, с которых
как множество терминалов, с которых

начинаются строки, выводимые из 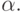 Если
Если 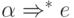 , то e также принадлежит .
, то e также принадлежит .
Определим FOLLOW(A) для нетерминала A как
множество терминалов a, которые могут появиться
непосредственно справа от A в некоторой сентенциальной
форме грамматики, то есть множество терминалов a таких,
что существует вывод вида 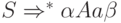 для некоторых
для некоторых 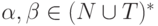 . Заметим, что между A и a в процессе вывода могут находиться нетерминальные символы, из которых
выводится e. Если A может быть самым правым символом
некоторой сентенциальной формы, то $ также принадлежит FOLLOW(A).
. Заметим, что между A и a в процессе вывода могут находиться нетерминальные символы, из которых
выводится e. Если A может быть самым правым символом
некоторой сентенциальной формы, то $ также принадлежит FOLLOW(A).
Рассмотрим алгоритмы вычисления функции FIRST.
Алгоритм 4.3. Вычисление FIRST для символов КС- грамматики.
Вход. КС-грамматика G = (N, T, P, S).
Выход. Множество FIRST(X) для каждого символа 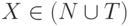 .
.
Метод. Выполнить шаги 1-3:
(1) Если X - терминал, то положить FIRST(X) = {X}; если X - нетерминал, положить 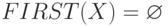 .
.
(2) Если в P имеется правило X -> e, то добавить e к FIRST(X).
(3) Пока ни к какому множеству FIRST(X) нельзя уже будет добавить новые элементы, выполнять:
do { continue = false;
Для каждого нетерминала X
Для каждого правила X -> Y1Y2...Yk
{i=1; nonstop = true;
while (i <= k && nonstop)
{добавить FIRST(Yi) n {e} к FIRST(X);
if (Были добавлены новые элементы)
continue = true;
if (e != FIRST (Yi)) nonstop = false;
else i+ = 1;
}
if (nonstop) {добавить e к FIRST(X);
continue = true;
} } }
while (continue);