
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 16.11.2010 | Уровень: специалист | Доступ: платный
Лекция 6:
Обработка результатов имитационного эксперимента
5.10. Обработка результатов эксперимента на основе регрессии
Часто целью исследования является определение функциональной связи между факторами и откликом (реакцией модели) по данным, полученным при экспериментах с моделью объекта или непосредственно с объектом. Такая цель достигается регрессионным анализом значений факторов  и отклика
и отклика  .
.
Под регрессией в теории вероятностей и математической статистике понимают зависимость среднего значения какой-либо величины от некоторой другой (других) величины. Регрессионный анализ - это совокупность методов построения и исследования регрессионной зависимости между величинами (в нашем случае между факторами и откликом) по статистическим данным. Статистические данные накапливаются при проведении эксперимента.
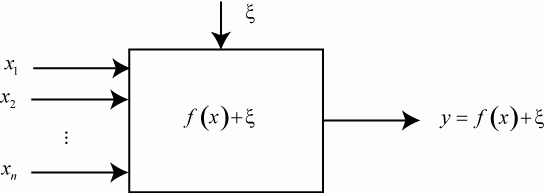
Формальная схема эксперимента выглядит так (рис. 5.6).
Прямоугольник представляет исследуемый объект или его математическую модель. Обозначения на рис. 5.6:
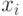 - значения факторов,
- значения факторов, 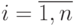 ;
;
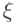 - случайный фактор, помеха. Будем считать, что эта случайная величина имеет нормальное распределение с матожиданием
- случайный фактор, помеха. Будем считать, что эта случайная величина имеет нормальное распределение с матожиданием ![M[\xi] = 0](/sites/default/files/tex_cache/5d1fc52bcae7bb52f18025de58fa689c.png) . Влияние помехи на отклик аддитивное, то есть ее случайные значения прибавляются к значениям отклика;
. Влияние помехи на отклик аддитивное, то есть ее случайные значения прибавляются к значениям отклика;
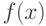 - искомая функциональная зависимость между факторами и откликом.
- искомая функциональная зависимость между факторами и откликом.
Отклик 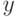 - величина случайная.
- величина случайная. 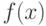 представляет собой среднее значение отклика (так как ):
представляет собой среднее значение отклика (так как ): 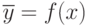 .
.
Исследуемый объект представляется как "черный ящик", никаких предположений о виде функции нет. Поэтому представим ее в виде аппроксимирующего полинома:
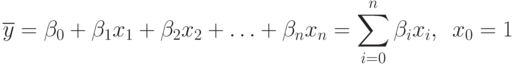
Этот полином получил название уравнения регрессии, а коэффициенты 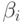 - коэффициенты регрессии. От точности подбора коэффициентов регрессии зависит точность представления .
- коэффициенты регрессии. От точности подбора коэффициентов регрессии зависит точность представления .
Коэффициенты определяются путем обработки полученных в ходе эксперимента варьируемых значений факторов и откликов.
Однако из-за ограниченного числа наблюдений точные значения 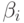 получить нельзя, будут найдены их оценки
получить нельзя, будут найдены их оценки  :
:

Поэтому уравнение регрессии принимает вид:
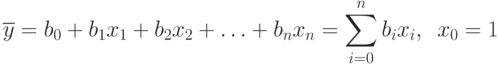
Вообще-то метку над  теперь надо бы изменить, так как вместо в уравнении теперь стоят , но мы этого делать не будем, чтобы не загромождать изложение новыми значками.
теперь надо бы изменить, так как вместо в уравнении теперь стоят , но мы этого делать не будем, чтобы не загромождать изложение новыми значками.
В уравнении регрессии могут участвовать и так называемые "совместные эффекты" ( 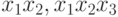 и т. п.) или степени значений факторов (
и т. п.) или степени значений факторов (  и т. п.). Совместные эффекты и степени факторов можно обозначать обобщенным фактором. Например, уравнение регрессии
и т. п.). Совместные эффекты и степени факторов можно обозначать обобщенным фактором. Например, уравнение регрессии
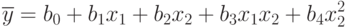
можно представить так:
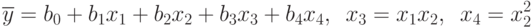
Итак, для определения выражения 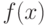 надо:
надо:
- выбрать степень аппроксимирующего полинома - уравнения регрессии;
- определить коэффициенты регрессии.
Выбор уравнения регрессии обычно начинают с линейной модели. Например, для двухфакторного эксперимента ее вид:
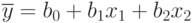
Если окажется, что такая аппроксимация дает неприемлемые отклонения при сравнении с экспериментальными точками отклика y , то модель усложняется, например, так:
 или
или
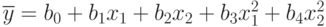 и т.д.
и т.д.
Коэффициенты регрессии 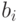 для выбранного уравнения определяются из условия минимума суммы квадратов ошибок, вычисленных по все экспериментальным точкам. Это делается так. Введем обозначения:
для выбранного уравнения определяются из условия минимума суммы квадратов ошибок, вычисленных по все экспериментальным точкам. Это делается так. Введем обозначения:
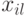 - значение
- значение  -го фактора в наблюдении номер
-го фактора в наблюдении номер 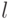 ;
;
 - значение отклика в -м наблюдении;
- значение отклика в -м наблюдении;
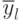 - значение отклика, вычисленное по принятому уравнению регрессии и данным .
- значение отклика, вычисленное по принятому уравнению регрессии и данным .
Очевидно, сумма квадратов ошибок между экспериментальными значениями и вычисленными по уравнению регрессии  для всех
для всех 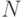 наблюдений равна:
наблюдений равна:
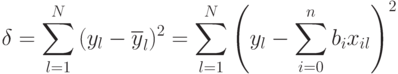
Для определения минимума ошибки ?возьмем частные производные от 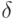 по всем неизвестным коэффициентам регрессии
по всем неизвестным коэффициентам регрессии 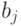 ,
, 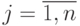 и приравняем их нулю:
и приравняем их нулю:

Нетрудно убедиться, что это условие минимума, а не максимума. Очевидно:
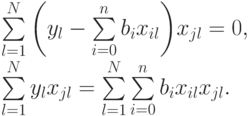
Для лучшей наглядности выделим неизвестные коэффициенты регрессии и получим:
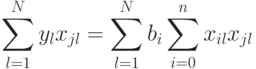
Выражение (5.3) представляет собой систему из  уравнений для нахождения
уравнений для нахождения  неизвестных коэффициентов регрессии , которые окончательно определят выбранное уравнение регрессии.
неизвестных коэффициентов регрессии , которые окончательно определят выбранное уравнение регрессии.
Нахождение коэффициентов регрессии справедливо при следующих допущениях:
- Случайный фактор
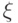 имеет нормальное распределение с матожиданием
имеет нормальное распределение с матожиданием ![М[ \xi ] = 0](/sites/default/files/tex_cache/f6d2c81eb0d983589b540ef808558203.png) .
. - Результаты наблюдений - независимые нормально распределенные случайные величины. Если это не соблюдается, то следует измерять другой отклик, удовлетворяющий этому условию, но функционально связанный с исследуемым откликом
- Точность наблюдений (количество реализаций модели) не меняется от наблюдения к наблюдению.
- Точность наблюдения
 должна быть выше точности
должна быть выше точности  .
.
Пример 5.8. На модели объекта проведен однофакторный эксперимент из пяти наблюдений, результаты которого сведены в таблицу (табл. 5.10).
Найти функциональную связь фактора с откликом 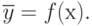
| Фактор и отклики | Наблюдение | 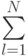 |
||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
 |
0 | 0,5 | 1,0 | 1,5 | 2,0 | 5 |
|
7,0 | 4,8 | 2,8 | 1,4 | 0 | 16 |
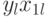 |
0 | 2,4 | 2,8 | 2,1 | 0 | 7,3 |
Решение
Примем, что кроме управляемого фактора 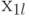 при проведении эксперимента на объект воздействует случайный фактор, распределенный по нормальному закону с математическим ожиданием
при проведении эксперимента на объект воздействует случайный фактор, распределенный по нормальному закону с математическим ожиданием ![М[\xi] = 0](/sites/default/files/tex_cache/a57dc659b9b031486d176c5e68b6fa2c.png) . Также предположим, что эта связь - линейная, следовательно, уравнение регрессии нужно определять в виде:
. Также предположим, что эта связь - линейная, следовательно, уравнение регрессии нужно определять в виде:
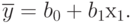
Неизвестных коэффициентов два: 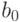 и
и 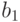 . Запишем (5.3) в виде двух уравнений для
. Запишем (5.3) в виде двух уравнений для  и в каждом из них разложим суммы по индексу :
и в каждом из них разложим суммы по индексу :
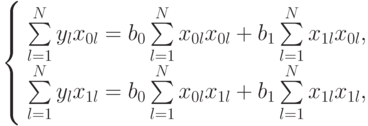
Так как  , получим:
, получим:
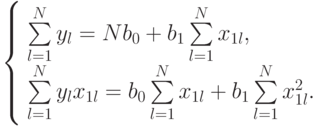
Подставим данные эксперимента из табл. 5.10 в систему (5.4):
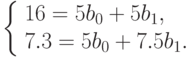
Решим систему из двух уравнений и получим: 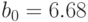 ,
,  .
.
Следовательно, искомое уравнение регрессии:
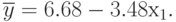
Доверительные границы для истинных значений 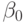 и
и 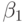 примера 5.8 определяются как обычно:
примера 5.8 определяются как обычно:

где 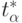 - аргумент распределения Стьюдента;
- аргумент распределения Стьюдента;  - среднеквадратические отклонения величин
- среднеквадратические отклонения величин 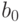 и соответственно.
и соответственно.
Значения определяются из таблицы распределения Стьюдента для 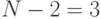 степеней свободы и задаваемом уровне достоверности
степеней свободы и задаваемом уровне достоверности  . Пусть
. Пусть 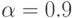 , тогда
, тогда  .
.
Значения 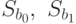 находятся по формулам:
находятся по формулам:
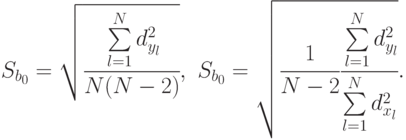
Данные для вычисления 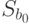 ,
, 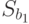 представлены в табл. 5.11.
представлены в табл. 5.11.
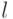
|

|
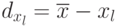
|
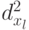
|
|
|
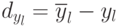
|
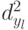
|
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1,0 | 1,0 | 7,0 | 6,68 | -0,32 | 0,1024 |
| 2 | 0,5 | 0,5 | 0,25 | 4,8 | 4,94 | 0,14 | 0,0196 |
| 3 | 1,0 | 0 | 0 | 2,8 | 3,2 | 0,40 | 0,16 |
| 4 | 1,5 | -0,5 | 0,25 | 1,4 | 1,46 | 0,06 | 0,0036 |
| 5 | 2,0 | -1,0 | 1,0 | 0 | 0,28 | 0,28 | 0,0784 |
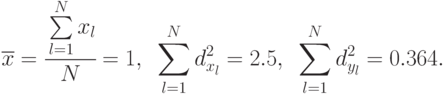
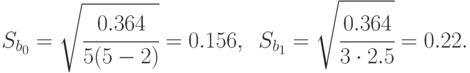
С уровнем достоверности 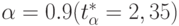
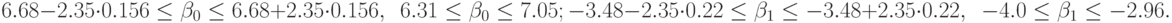
Большой размах доверительных границ объясняется малым числом наблюдений в данном эксперименте.
Доверительные границы для y принимают разные значения в зависимости от значений факторов [33].
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|