| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 08.11.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Лекция 13:
Поиск
Аннотация: Введение. Поиск и другие операции над таблицами. Последовательный
поиск. Логарифмический поиск в статических таблицах. Бинарный поиск.
Оптимальные деревья бинарного поиска. Логарифмический поиск в
динамических таблицах. Сбалансированные сильно ветвящиеся деревья.
Ключевые слова: множества, имена, пространством имен, пространство имен, естественным порядком, лексикографический порядок, индуцированный, Исход, функция, поиск, таблицей, табличным порядком, индекс, табличный порядок, мощность, представление, место, исключение, таблица, класс, записи, запись, полей, ключом, файл, ключ, справочнике, указателе, указатель, операции, определение, значение, динамической, статической, сортировка, последовательный поиск, подтаблица, присваивание, алгоритм, цикла, улучшение, прямой, доступ, Размещение, память, последовательным доступом, анализ, бинарный поиск, интервал, корректность, Дерево бинарного поиска, дерево, Симметричный порядок, Left, right, поддерево, список, подмножество, листья, лист
Введение
Задача поиска является фундаментальной в комбинаторных алгоритмах, так как
она формулируется в такой общности, что включает в себя множество задач,
представляющих практический интерес. При самой общей постановке
"Исследовать множество 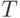 с тем чтобы найти элемент, удовлетворяющий некоторому
условию
с тем чтобы найти элемент, удовлетворяющий некоторому
условию 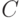 ", о задаче поиска едва ли можно сказать что-либо
стоящее. Удивительно, однако, что
достаточно незначительных ограничений на структуру множества ,
чтобы задача стала интересной: возникает множество разнообразных стратегий
поиска различной степени эффективности. Мы сделаем некоторые предположения о
структуре множества , позволяющие исследовать
", о задаче поиска едва ли можно сказать что-либо
стоящее. Удивительно, однако, что
достаточно незначительных ограничений на структуру множества ,
чтобы задача стала интересной: возникает множество разнообразных стратегий
поиска различной степени эффективности. Мы сделаем некоторые предположения о
структуре множества , позволяющие исследовать  или
или 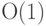 . Большинство
алгоритмов поиска попадает в одну из трех категорий, характеризуемых
временем поиска
. Большинство
алгоритмов поиска попадает в одну из трех категорий, характеризуемых
временем поиска 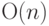 .
.
Поиск и другие операции над таблицами
Любой способ поиска оперирует с элементами, которые будем называть именами, взятыми из множества имен 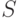 - оно называется пространством
имен. Это пространство имен может быть
конечным или бесконечным. Самыми распространенными пространствами имен
являются множества целых чисел с их числовым порядком (нумерацией), и множества
последовательностей символов над некоторым конечным алфавитом с их
лексикографическим (то есть словарным) порядком. Каждый из алгоритмов поиска,
обсуждаемых в этой лекции, основан на одном из трех следующих предположений о
пространстве .
- оно называется пространством
имен. Это пространство имен может быть
конечным или бесконечным. Самыми распространенными пространствами имен
являются множества целых чисел с их числовым порядком (нумерацией), и множества
последовательностей символов над некоторым конечным алфавитом с их
лексикографическим (то есть словарным) порядком. Каждый из алгоритмов поиска,
обсуждаемых в этой лекции, основан на одном из трех следующих предположений о
пространстве .
Предположение 1. На определен линейный порядок, называемый естественным порядком и
обозначаемый знаком <. Такой порядок имеет следующие свойства.
- Любые два элемента
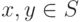 сравнимы, то есть должно
выполняться в точности одно из трех условий:
сравнимы, то есть должно
выполняться в точности одно из трех условий: 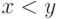 ,
, 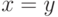 ,
, 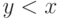 .
. - Порядок обладает транзитивностью, то есть если и
 ,
то
,
то  для любых элементов
для любых элементов 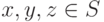 . Мы
используем обозначения
. Мы
используем обозначения 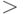 ,
,  ,
, 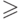 в очевидном смысле. При
анализе эффективности алгоритма поиска полагаем, что исход (
в очевидном смысле. При
анализе эффективности алгоритма поиска полагаем, что исход (  ,
,  или ) зависит от
сравнения.
или ) зависит от
сравнения.
Предположение 2. Каждое
имя в есть последовательность символов или цифр над конечным
линейно упорядоченным алфавитом 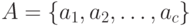 . Естественным порядком на является лексикографический порядок, индуцированный линейным
порядком на
. Естественным порядком на является лексикографический порядок, индуцированный линейным
порядком на 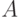 . Мы полагаем, что исход ( , или ) сравнения
двух символов (не имен) получается
за время, не зависящее от
. Мы полагаем, что исход ( , или ) сравнения
двух символов (не имен) получается
за время, не зависящее от 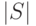 или
или  .
.
Предположение 3. Имеется
функция 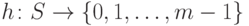 ,
которая равномерно отображает пространство имен в
множество
,
которая равномерно отображает пространство имен в
множество 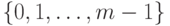 , то есть все целые
, то есть все целые  , приблизительно с одинаковой частотой являются образами имен из
при отображении
, приблизительно с одинаковой частотой являются образами имен из
при отображении 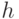 . Мы полагаем, что функция не
зависела от , это с теоретической точки зрения выглядит шатко, но с
практической - довольно реально.
. Мы полагаем, что функция не
зависела от , это с теоретической точки зрения выглядит шатко, но с
практической - довольно реально.
Как уже было отмечено, поиск производится не в самом пространстве имен, а в конечном подмножестве 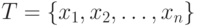 множества , называемом таблицей. На большинстве таблиц, которые мы
рассматриваем,
определен линейный порядок, называемый табличным порядком: ему
соответствует нижний индекс имени (то есть
множества , называемом таблицей. На большинстве таблиц, которые мы
рассматриваем,
определен линейный порядок, называемый табличным порядком: ему
соответствует нижний индекс имени (то есть 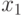 есть первое имя в
таблице,
есть первое имя в
таблице, 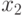 - второе и тому подобное). Табличный порядок
часто совпадает с естественным порядком, определенным на пространстве имен, однако такое совпадение не
обязательно.
- второе и тому подобное). Табличный порядок
часто совпадает с естественным порядком, определенным на пространстве имен, однако такое совпадение не
обязательно.
Мощность таблицы обычно намного меньше, чем мощность
пространства имен , даже если конечно.
Представление о таблице как об упорядоченном множестве имен существенно для многих целей. Но иногда бывает необходимо рассматривать таблицу как множество ячеек, каждая из которых может содержать одно имя. Например, если процесс включения нового имени рассматривать более подробно, то обнаружится, что сначала нужно расширить таблицу добавлением ячейки, для того чтобы заготовить место для новой записи: только потом туда заносится новое имя.
Мы будем предполагать, что имена появляются в таблице не больше одного
раза (исключение составляет переходный период, в течение которого заносится
новое имя; в таблице допускается два вхождения одного имени). В большинстве случаев
вследствие такого предположения таблица с именами имеет ровно ячеек. Однако важный класс алгоритмов, основанных на вычислении
адреса, опирается на предположение о том, что таблица содержит больше ячеек, чем имен. Эти
алгоритмы должны четко принимать во внимание наличие пустых ячеек.
Существует ряд синонимов для объектов, именуемых здесь таблицей и именем. В обработке данных существуют файлы, элементами которых являются записи ; каждая запись есть последовательность полей, одно из которых (участвующее в поиске) называется ключом. Если сам файл проходится во время поиска, "файл" и "ключ" представляют собой то, что мы называем "таблицей" и "именем" соответственно. (Эта терминология несколько двусмысленна, поскольку понятие "ключ" можно отнести либо к самой ячейке, либо к содержимому ячейки.) Однако при поиске в большом файле часто не подразумевается просмотр самого файла; вместо этого поиск осуществляется на справочнике или указателе файла. При успешном поиске найденная в указателе отдельная запись указывает на соответствующую запись в файле. В таком типе организации файлов нашему понятию таблицы соответствует указатель или справочник.
Мы рассматриваем только четыре табличные операции: поиск, включение,
исключение и распечатка. Подробное определение того, что должны делать эти
операции над таблицей 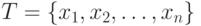 , зависит от
структуры данных, использованной для реализации таблицы.
, зависит от
структуры данных, использованной для реализации таблицы.
поиск 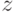 : если
: если 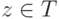 , то отметить его
указателем, то есть переменной
, то отметить его
указателем, то есть переменной  присвоить такое значение, что
присвоить такое значение, что 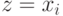 ; в противном случае указать, что
; в противном случае указать, что 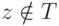 ;
;
включение : если , то поместить его
на соответствующее место.
Включение в общем случае предполагает прежде всего поиск соответствующего
места, поэтому иногда удобно разделить операцию на две фазы. Сначала используем
процедуру поиска для отыскания места, куда должно быть помещено , и затем помещаем z на это место.
включить на -е место: включить сразу после имени 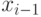 . До включения
. До включения 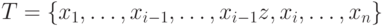 .
.
исключить : если , то исключить его.
Как и включение, исключение иногда реализуется процедурой поиска для
получения
места и последующей процедурой:
исключить с -го места: исключить 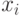 из .До исключения
из .До исключения 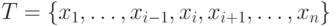 \\ & После исключения
\\ & После исключения 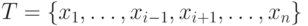
Таблица, в которой осуществляются включения или исключения, называется динамической ; в противном случае она носит название статической.
Последней операцией, которую мы будем рассматривать для каждой табличной структуры, является
распечатка: & напечатать все имена из в их естественном
порядке
Среди всех операций, которые можно производить над таблицами, четыре, рассматриваемые в этой лекции (поиск, включение, исключение и распечатка), и сортировка ( "Сортировка (часть 1)" "Сортировка (часть 2)" ) - наиболее важные.