| Россия, Волгоградская область |
Инспектор
Вы можете этот курс.
Опубликован: 10.10.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Московский государственный университет путей сообщения
Лекция 9:
Эволюционные стратегии
9.3. Основные параметры и самоадаптация
В ЭС параметры ассоциируются с каждой особью популяции. Обычно для этих параметров производится самоадаптация для определения лучшего направления поиска и максимально возможного шага. По сути, параметры определяют вероятностное распределение, используемое в мутации, из которого определяется размер шага. Основная идея самоадаптации заключается в том, как улучшить распределение мутации, чтобы максимально поддержать сходимость поиска решения.
В первых реализациях ЭС применялся только один вид параметра – отклонение в распределении Гаусса, которое используется в операторе мутации. В этом случае, как показано в разделе 9.1,  –я особь определяется как
–я особь определяется как  , где
, где 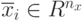 представляет генотип и
представляет генотип и 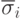 - вектор-параметр отклонений (обычно
- вектор-параметр отклонений (обычно 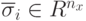 и все компоненты отклонения одинаковы
и все компоненты отклонения одинаковы  для
для 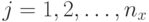 ). Применение большего числа параметров дает больше степеней свободы особям и лучшие возможности для регулирования распределения мутации.
). Применение большего числа параметров дает больше степеней свободы особям и лучшие возможности для регулирования распределения мутации.
Если в качестве параметров используются только отклонения, то лучшие направления поиска определяются вдоль осей системы координат пространства поиска. Но не всегда лучшее направление поиска совпадает с осями. В таких случаях необходима дополнительная информация для ускорения процесса сходимости. Такую информацию можно получить из матрицы 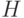 – гессиана фитнесс-функции. Если гессиан используется в качестве параметра, то мутация определяется следующим образом:
– гессиана фитнесс-функции. Если гессиан используется в качестве параметра, то мутация определяется следующим образом:
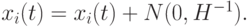
К сожалению, не всегда можно использовать гессиан, поскольку фитнесс-функции не гарантируют существование производных второго порядка. Но даже если эти производные существуют, то построение гессиана имеет значительную вычислительную сложность. Потому разработаны и другие методы.
В [4] предложено использовать матрицу ковариации 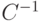 , которая определяется отклонениями параметров особи и может использоваться в качестве дополнительной информации, позволяющей определить оптимальный размер шага и направление поиска. В этом случае
, которая определяется отклонениями параметров особи и может использоваться в качестве дополнительной информации, позволяющей определить оптимальный размер шага и направление поиска. В этом случае 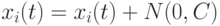 , где
, где 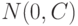 обозначает нормальное распределение вектора
обозначает нормальное распределение вектора 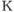 с нулевым математическим ожиданием и плотностью вероятностей
с нулевым математическим ожиданием и плотностью вероятностей  .
.
Здесь диагональные элементы - вариации 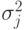 , а не- диагональные элементы – ковариации величин шагов мутации. При этом ковариации определяются углами вращения, которые необходимо произвести, чтобы преобразовать некоррелированный вектор мутации в коррелированный вектор. Если
, а не- диагональные элементы – ковариации величин шагов мутации. При этом ковариации определяются углами вращения, которые необходимо произвести, чтобы преобразовать некоррелированный вектор мутации в коррелированный вектор. Если 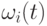 означает угол вращения вектора для -ой особи, то особь представляется триплетом
означает угол вращения вектора для -ой особи, то особь представляется триплетом 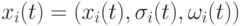 , где
, где
![x_i(t)\in R^{n_x},\sigma_i(t)\in R_+^{n_x},\omega_i(t)\in R^{n_x(n_x-1)/2},\mbox{и}\\\omega_{ik}(t)\in(0,2\pi],k=1,\dots,n_x(n_x-1/2)](/sites/default/files/tex_cache/2de71ec572c57e27c51ccfc552cddeb0.png) |
( 9.9) |
Углы вращения используются при представлении ковариаций для  генетических переменных генетического вектора
генетических переменных генетического вектора 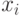 . Поскольку ковариационная матрица симметрична, можно использовать вектор для представления углов вместо матрицы. Углы вращения можно использовать для вычисления ортогональной матрицы вращения
. Поскольку ковариационная матрица симметрична, можно использовать вектор для представления углов вместо матрицы. Углы вращения можно использовать для вычисления ортогональной матрицы вращения 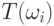 следующим образом:
следующим образом:
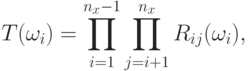 |
( 9.10) |
которая является произведением 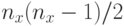 матриц вращения. Каждая матрица вращения
матриц вращения. Каждая матрица вращения 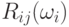 является единичной матрицей с
является единичной матрицей с  и
и  , с
, с  .
.
Построенная матрица вращения используется в операторе мутации.
Итак, в ЭС используются два вида параметров: 1) стандартные отклонения величины шага мутации; 2) углы вращения, которые представляются ковариациями размера шага мутации. Пусть  обозначает число используемых параметров отклонений и
обозначает число используемых параметров отклонений и  - число углов вращения. На практике имеют место, в основном, следующие типовые ситуации:
- число углов вращения. На практике имеют место, в основном, следующие типовые ситуации:
-
 , т.е. используется только один параметр отклонения
, т.е. используется только один параметр отклонения 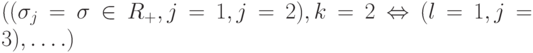 , одинаковый для всех компонент генотипа нулевые углы вращения. При этом распределение вероятностей имеет круглую форму, что показано на рис.9.1а. Середина окружности определяет позицию родительской особи , в то время как
, одинаковый для всех компонент генотипа нулевые углы вращения. При этом распределение вероятностей имеет круглую форму, что показано на рис.9.1а. Середина окружности определяет позицию родительской особи , в то время как 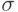 указывает на отклонение величины шага.
указывает на отклонение величины шага.Отметим, что это распределение фактически показывает вероятность позиции потомка
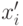 , имеющей наиболее высокую вероятность в центре. Тогда параметр регулируется следующим образом -
, имеющей наиболее высокую вероятность в центре. Тогда параметр регулируется следующим образом - 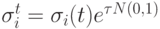 , где
, где 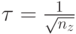 . При этом регулирование одного параметра выполняется быстро, но подход является не гибким в том случае, когда координаты имеют различные градиенты.
. При этом регулирование одного параметра выполняется быстро, но подход является не гибким в том случае, когда координаты имеют различные градиенты. -
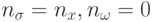 , где каждая компонента имеет свой собственный параметр отклонения. В этом случае распределение мутации имеет эллиптическую форму, как показано на рис.9.1b, где
, где каждая компонента имеет свой собственный параметр отклонения. В этом случае распределение мутации имеет эллиптическую форму, как показано на рис.9.1b, где 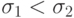 . Тогда увеличение числа параметров вызывает линейное увеличение вычислительной сложности, но дополнительные степени свободы обеспечивают большую гибкость. При этом могут учитываться различные значения градиентов по разным осям. Значения параметров корректируются в соответствии со следующими формулами:
. Тогда увеличение числа параметров вызывает линейное увеличение вычислительной сложности, но дополнительные степени свободы обеспечивают большую гибкость. При этом могут учитываться различные значения градиентов по разным осям. Значения параметров корректируются в соответствии со следующими формулами: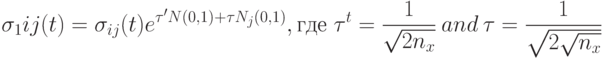
( 9.11) -
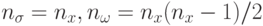 , где в качестве параметров кроме отклонений (девиаций) используются также углы вращения. В этом случае эллиптическое распределение мутации вращается относительно осей координат как показано на рис.9.1с. Эти вращения позволяют найти лучшую аппроксимацию контуров в пространстве поиска. Тогда параметры отклонений корректируются в соответствии с предыдущей формулой (9.11), а значения углов по нижеприведенной формуле
, где в качестве параметров кроме отклонений (девиаций) используются также углы вращения. В этом случае эллиптическое распределение мутации вращается относительно осей координат как показано на рис.9.1с. Эти вращения позволяют найти лучшую аппроксимацию контуров в пространстве поиска. Тогда параметры отклонений корректируются в соответствии с предыдущей формулой (9.11), а значения углов по нижеприведенной формуле 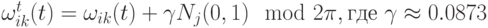 . Расширение параметров путем ввода углов вращения повышает гибкость, но вычислительная сложность при этом растет квадратично.
. Расширение параметров путем ввода углов вращения повышает гибкость, но вычислительная сложность при этом растет квадратично. -
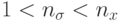 , где допускается еще больше степеней свободы. Для всех
, где допускается еще больше степеней свободы. Для всех 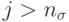 используется отклонение
используется отклонение 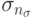 .
.
Стратегии самоадаптации. Чаще всего при самоадаптации параметров ЭС применяется механизм, основанный на логарифмически нормальном распределении, который описан в следующем разделе 9.4. Кроме этого могут быть применены аддитивные методы, также представленные в разделе 9.4.
В работе [5] предложен метод адаптации параметров на основе "обучения с подкреплением", в котором параметры корректируются следующим образом:
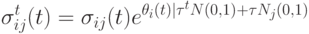 |
( 9.12) |
где 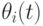 - сумма временных поощрений за последние
- сумма временных поощрений за последние  поколений для -ой особи, то есть
поколений для -ой особи, то есть
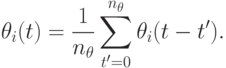 |
( 9.13) |
Для вычисления поощрений можно использовать различные методы для каждой особи на каждом временном шаге. Например, в работе [5] предложено это делать следующим образом
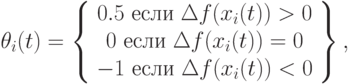 |
( 9.14) |
где ухудшение значений фитнесс-функции сурово штрафуется. Здесь 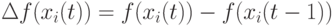 .
.
В работе [6] использовались поощрения +1, 0 или -1 в зависимости от полученных характеристик. Кроме этого, в этой же работе предложено применять:
-
Этот подход определения поощрения основан на учете изменений на уровне фенотипа, поскольку определяется фитнесс-функцией. При этом чем больше особь улучшает значение фитнесс-функции, тем она получает большее поощрение. С другой стороны, худшее значение фитнесс-функции особи ведет к увеличению штрафа для этой особи
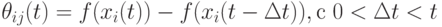
( 9.15) -
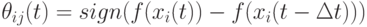 . Эта схема дает значения поощрений +1, 0 или -1.
. Эта схема дает значения поощрений +1, 0 или -1. -
 .
.
Здесь поощрение пропорционально размеру шага в пространстве решений.
В [7] рассматривается схема самоадаптации, где 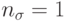 и применяется ковариационная матрица. В этой схеме отклонение потомка определяется как функция отклонений производящих его родителей. Здесь для каждого потомка
и применяется ковариационная матрица. В этой схеме отклонение потомка определяется как функция отклонений производящих его родителей. Здесь для каждого потомка 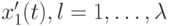
![\sigma'_l(t)=\sqrt[p]{\prod_{i\in\Omega_i(t)}\sigma_i(t)e^{\xi}},](/sites/default/files/tex_cache/333f42371831bcdb54b1204a922e3ed8.png) |
( 9.16) |
где 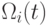 - индекс множества
- индекс множества 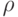 родителей потомка
родителей потомка 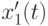 и распределение
и распределение 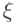 такое, что
такое, что  . В разделе 9.4 (оператор мутации) показано, как эта схема самоадаптации может быть использована в операторе мутации.
. В разделе 9.4 (оператор мутации) показано, как эта схема самоадаптации может быть использована в операторе мутации.
В работе [8] применяется схема самоадаптации, где и каждая особь использует различное количество параметров отклонений  . На каждой итерации
. На каждой итерации  число параметров отклонений может быть увеличено или уменьшено с вероятностью 0.05. Если число параметров отклонений увеличивается, то новый параметр отклонения инициализируется следующим образом:
число параметров отклонений может быть увеличено или уменьшено с вероятностью 0.05. Если число параметров отклонений увеличивается, то новый параметр отклонения инициализируется следующим образом:
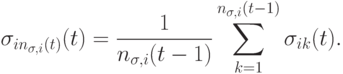 |
( 9.17) |