
|
Reference = add reference, в висуал студия 2010 не могу найти в вкладке Solution Explorer, Microsoft.Xna.Framework. Его нету. |
Инспектор
Вы можете этот курс.
Опубликован: 28.04.2009 | Уровень: для всех | Доступ: платный
Лекция 5:
Вершинные шейдеры
Преобразование кода эффекта тоже весьма тривиально (листинг 5.19).
public partial class MainForm : Form
{
// Файл эффекта для визуализации вращающегося диска
const string diskEffectFileName = "Data\\Disk.fx";
// Файл эффекта для визуализации разлетающихся искр
const string fireworkEffectFileName = "Data\\Firework.fx";
// Эффект визуализации диска
Effect diskEffect = null;
// Объект, инкапсулирующий параметр angle эффекта диска
EffectParameter angleParam = null;
// Эффект визуализации искр
Effect fireworkEffect = null;
// Объекты, инкапсулирующие параметры эффекта искр:
diskSpeed, time, timeLoopParam
EffectParameter diskSpeedParam = null;
EffectParameter timeParam = null;
EffectParameter timeLoopParam = null;
private void MainFormLoad(object sender, EventArgs e)
{
// Так как вершины визуализируются без промежуточного
"эмулятора ", используется "родная
" // декларация формата вершин
fireworkDeclaration = new VertexDeclaration(device,
VertexPositionColorTexture.VertexElements);
try
{
// Загружаем эффекты
diskEffect = Helper.LoadAndCompileEffect(device,
diskEffectFileName);
fireworkEffect = Helper.LoadAndCompileEffect(device,
fireworkEffectFileName);
}
catch (Helper.LoadAndCompileEffectException ex)
{
// Обрабатываем исключительные ситуации загрузки и компиляции эффекта
closing = true;
MessageBox.Show(ex.Message, "Критическая ошибка", MessageBoxButtons.OK,
MessageBoxIcon.Error);
Application.Idle += new EventHandler(ApplicationIdle);
return; }
// Получаем объект, инкапсулирующий параметр angle
эффекта диска angleParam = diskEffect.Parameters["angle"];
Debug.Assert(angleParam != null, diskEffectFileName + " :
не найден параметр angle");
// Получаем объект, инкапсулирующий параметр diskSpeed эффекта искр
diskSpeedParam = fireworkEffect.Parameters["diskSpeed"];
Debug.Assert(diskSpeedParam != null, fireworkEffectFileName + " :
не найден параметр diskSpeed");
// Получаем объект, инкапсулирующий параметр time эффекта искр
timeParam = fireworkEffect.Parameters["time"] ;
Debug.Assert(timeParam != null, fireworkEffectFileName + " :
не найден параметр time") ;
// Получаем объект, инкапсулирующий параметр timeLoop эффекта искр
timeLoopParam = fireworkEffect.Parameters["timeLoop"];
Debug.Assert(timeLoopParam != null, fireworkEffectFileName + " :
не найден параметр timeLoop");
}
private void MainFormPaint(object sender, PaintEventArgs e)
{
float time = (float)stopwatch.ElapsedTicks / (float)Stopwatch.Frequency;
// Задаем значения параметров
timeParam. SetValue(time);
timeLoopParam.SetValue(timeLoop);
diskSpeedParam.SetValue(diskSpeed);
// Указывает декларацию формата вершин. Внимание!
Если вы при переходе к другому формату
// вершин и забудете подправить декларацию формата
вершины, то часть входных параметров
// вершины вроде текстурных координат будет содержать
"мусор ". Соответственно, эффект будет
// работать весьма странно, а самом худшем случае это
может привести к краху приложения и
// даже операционной системы.
device.VertexDeclaration = fireworkDeclaration;
// Визуализируем искры как обычно
fireworkEffect.Begin();
for (int i = 0; i < fireworkEffect.
CurrentTechnique.Passes.Count; i++)
{
EffectPass currentPass = fireworkEffect.
CurrentTechnique.Passes[i] ; currentPass.Begin();
for (int j = 0; j < fireworkVertices.Length; j++)
{
device.DrawUserPrimitives(PrimitiveType.PointList,
fireworkVertices[j], 4> 0, fireworkVertices [j] .Length) ;
}
currentPass.End();
}
fireworkEffect.End();
// Выполняем приготовления к визуализации диска
device.RenderState.AlphaBlendEnable = false;
angleParam.SetValue(diskSpeed * time);
// Не забываем изменить декларацию формата вершины
device.VertexDeclaration = diskDeclaration;
// Визуализируем диск
...
// Вычисляем FPS
...
}
}
Листинг
5.19.
Анализ исходного кода эффекта
Сейчас вы уже вполне неплохо освоились с языком Vertex Shader 1.1 , поэтому выполнять построчный анализ ассемблерного кода вряд ли имеет смысл. Вместо этого я сразу приведу отчет NVIDIA FX Composer 2.0 с ассемблерным листингом, разделенным комментариями на блоки, соответствующие тем или иным инструкциям.
// Generated by Microsoft (R) D3DX9 Shader Compiler 9.12.589.0000
//
// Parameters:
//
// float diskSpeed;
// float time;
// float timeLoop;
//
//
// Registers:
//
// Name Reg Size
// ----
// diskSpeed c0 1
// time c1 1
// timeLoop c2 1
//
//
// Default values:
//
// diskSpeed
// c0 = { 0, 0, 0, 0 };
//
// time
// c1 = { 0, 0, 0, 0 };
//
// timeLoop
// c2 = { 0, 0, 0, 0 };
//
vs_1_1
def c3, 0.0416666418, -0.5, 1, 0 def c4, 4, 9.52380943,
0.104999997, 0.25 def c5, 0.5, 0.159154937, 0.25, -
0.00138883968
def c6, 6.28318548, -3.14159274, -2.52398507e-007,
2.47609005e-005 dcl_position v0 dcl_color
v1 dcl_texcoord v2 // float currentTime = time - input.pos.x;
1. add r2.w, -v0.x, c1.x
// Начало вычисления float localTime = currentTime % timeLoop
mul r0.w, r2.w, c2.x
add r1.w, c2.x, c2.x
sge r0.w, r0.w, -r0.w
mad r0.w, r0.w, r1.w, -c2.x
rcp r1.w, r0.w
mul r3.w, r2.w, r1.w
expp r4.y, r3.w
mov r1.w, r4.y
// Вычисление подвыражения input.texcoord / slowing из
// float2 t = min(localTime.xx, input.texcoord / slowing).
Деление на константу заменено
// умножением
10. mul r0.xy, v2, c4.yxzw
// Окончание вычисления float localTime = currentTime % timeLoop
11. mul r3.w, r0.w, r1.w
// Окончание вычисления float2 t = min(localTime.xx,
input.texcoord / slowing)
12. min r0.xy, r0, r3.w
// float2 sCoord = input.pos.yz + t * (input.texcoord -
t * slowing / 2.0f)
mul r1.xy, r0, c4.zwzw
mad r1.xy, r1, -c5.x, v2
mad r0.xy, r0, r1, v0.yzzw
// sCoord.y += diskSpeed * (time - localTime)
mad r3.w, r0.w, -r1.w, c1.x
mad r3.w, c0.x, r3.w, r0.y
// Начало вычисления output.pos.xy = sCoord.x * float2(sin(sCoord.y),
cos(sCoord.y))
mad r2.xy, r3.w, c5.y, c5.zxzw
frc r1.xy, r2
mad r1.xy, r1, c6.x, c6.y
mul r1.xy, r1, r1
mad r2.xy, r1, c6.z, c6.w
mad r2.xy, r1, r2, c5.w
// Вычисление подвыражения (currentTime >= 0) оператора if
24. sge r2.w, r2.w, c3.w
// Продолжение вычисления output.pos.xy = sCoord.x *
float2(sin(sCoord.y), cos(sCoord.y))
25. mad r2.xy, r1, r2, c3.x
// float remainTime = liveTime - localTime
26. mad r1.w, r0.w, -r1.w, c4.x
// Продолжение вычисления output.pos.xy = sCoord.x *
float2(sin(sCoord.y), cos(sCoord.y))
mad r2.xy, r1, r2, c3.y
mad r1.xy, r1, r2, c3.z
// Продолжение оператора if: вычисление подвыражения
(remainTime > 0)
29. slt r0.w, c3.w, r1.w
// output.color.a = remainTime / liveTime
30. mul r1.w, r1.w, c4.w
// Продолжение оператора if: окончание вычисления значения условия
// ((remainTime > 0) && (currentTime >= 0))
31. mul r0.w, r2.w, r0.w
// Окончание вычисления выражения
// output.pos.xy = sCoord.x * float2(sin(sCoord.y), cos(sCoord.y))
// (умножение на sCoord.x)
32. mul oPos.xy, r0.x, r1
// Окончание блока if. Если условное выражение блока
if равно true, альфа компонент цвета
// остается без изменений, иначе обнуляется.
33. mul oD0.w, r1.w, r0.w
// output.pos.zw = float2(0.0, 1.0);
34. mov oPos.zw, c3.xywz
// output.color.rgb = input.color.rgb
35. mov oD0.xyz, v1
// approximately 37 instruction slots usedПробежимся по наиболее интересным местам HLSL кода. Первым сюрпризом является трансляция вычисления выражения currentTime % timeLoop аж в целых 8 инструкций (с 2-й по 9-ю). Это обусловлено тем, что язык Vertex Shader 1.1 не содержит инструкции вычисления остатка отделения, соответственно компилятору приходится эмулировать ее посредством скудного набора инструкций. Ниже приведена реконструкция алгоритма нахождения остатка от деления на языке C#:
// Функция на языке C#, вычисляющая a%b. Написана
приближенно к алгоритму, используемому в
// HLSL
static float mod(float a, float b)
{
// Если частное (a/b) является отрицательным числом,
то изменяем знак у делителя (nb=-b)
float cmp;
if (a*b > -a*b) cmp
= 1;
else
cmp = 0;
float nb = cmp * (b + b) - b;
// Вычисляем частное
float div = a * (1.0f / nb);
// Находим дробную часть частного
float frac = div - (float)Math.Floor(div);
// Вычисляем остаток
float result = frac * nb;
return result;
}Отдельно стоит отметить нахождение дробной части числа, до сих выполнявшаяся посредством макроса frc . Но при анализе кода нахождения остатка дизассемблер не смог распознать эту операцию, что дало нам возможность воочию увидеть, что в действительности скрывается за макросом frc. Думаю, вы ожидали увидеть здесь все что угодно, только не команду expp, вычисляющую приближенное значение 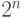 . Правда компилятора интересует не само значение , а побочный результат команды, заносящей в компонент y вектора-результата дробную часть числа ( a – floor(a) ). В целом же из всего вышесказанного следует вывод, что, несмотря на обманчиво простой вид, оператор % языка HLSL является очень "дорогой " операцией, соизмеримой по времени выполнения с вычислением тригонометрических функций.
. Правда компилятора интересует не само значение , а побочный результат команды, заносящей в компонент y вектора-результата дробную часть числа ( a – floor(a) ). В целом же из всего вышесказанного следует вывод, что, несмотря на обманчиво простой вид, оператор % языка HLSL является очень "дорогой " операцией, соизмеримой по времени выполнения с вычислением тригонометрических функций.
Чтобы максимально задействовать суперскалярную архитектуру современных вершинных процессоров, компилятор HLSL изменил их порядок следования, чтобы избавиться от зависимости соседних инструкций. Обратной стороной медали является сложность анализа кода: инструкции многих операторов HLSL перемешались между собой, а код строки float remainTime = liveTime – localTime, расположенной в начале эффекта, был перенесен компилятором ближе к концу шейдера.
Еще одной любопытной особенностью является код оператора if, составное условное выражение которого содержит логическую операцию "и " – так как язык Vertex Shader 1.1 не поддерживает булевские типы и логические операции над ними, оператор && эмулируется перемножением чисел с плавающей точкой.
Оптимизация вершинного шейдера
И, наконец, анализируя код строки float2 sCoord = input.pos.yz + t * (input.texcoord - t * slowing / 2.0f) мы обнаружим, что компилятор не смог догадаться предварительно вычислить значение константы slowing / 2.0f, что вылилось в один лишний оператор mul. Это дает нам основание предположить, что добавив в файл HLSL явное вычисление константы, мы сможем немного ускорить работу приложения. Но наверняка быть уверенным нельзя, ведь Vertex Shader 1.1 является всего лишь промежуточным кодом, впоследствии еще раз оптимизируемым компилятором драйвера.
Ну что ж, рискнем. Основные фрагменты эффекта с модифицированным вершинным шейдером приведены в листинге 5.20. Полный текст эффекта находится в ![]() example.zip в каталоге Examples\Ch05\Ex12.
example.zip в каталоге Examples\Ch05\Ex12.
static float2 slowing = {0.105, 0.25};
// Явно рассчитываем значение вспомогательной константы
static float2 slowing2 = slowing / 2.0f;
...
VertexOutput MainVS(VertexInput input)
{
...
float2 sCoord = input.pos.yz + t * (input.texcoord -t * slowing2);
...
}
Листинг
5.20.
Просмотр ассемблерного кода приложения даст вполне предсказуемые результаты: число команд ассемблерного листинга уменьшилось на одну (с 37 до 36), а вот время выполнения эффекта сократилось на целых 5 тактов (с 42 до 37) – вероятно удаление одной лишней команды позволило драйверу более эффективно распараллелить выполнение команд вершинного шейдера. В результате пиковая производительность эффекта на NVIDIA GeForce 7800 GTX увеличилась с 76.000.000 до 86.000.000 вершин в секунду, т.е. на 13%.
Таким образом, даже незначительные изменения в коде эффекта могут спровоцировать лавину изменений в финальном микрокоде шейдера для физического вершинного процессора, которые могут как усилить эффект от оптимизации HLSL -кода шейдера, так и свести ее на нет и даже снизить производительность.
5.5.4. Анализ производительности приложения
Настало время оценить эффект от переноса вычислений на видеокарту. На рисунке 5.23 приведена диаграмма, построенная в Excel по результатам измерения производительности примеров Ch05\Ex10 и Ch05\Ex12 на разных GPU.
Как видно, на GeForce 7600GT и Radeon X700 Pr o перенос вычислений с CPU на GPU увеличил частоту кадров почти в 10 раз. На компьютере с интегрированным GPU i946GZ (GMA 3000) частота кадров тоже заметно увеличилась (в 3.5 раза), что на первый взгляд выглядит весьма странно: i946GZ не содержит аппаратного вершинного процессора, поэтому все вычисления по-прежнему выполняются силами центрального процессора.
Данный парадокс обусловлен рядом факторов. Как известно, .NET приложения содержат множество вспомогательного кода для обнаружения различных внештатных ситуаций вроде переполнения или обращения к несуществующему элементу коллекции. Разумеется, этот код оказывает отрицательное влияние на производительность, усугубляемое многократным его выполнением в цикле. Кроме того, все современные процессоры еще со времен Pentium-III содержат специализированный векторные регистры SSE и набор векторных инструкций, отдаленно напоминающие ассемблерные команды языков Vertex Shader. Но язык C# и промежуточный язык IL не содержат векторных команд, что затрудняет распознавание векторных операций при компиляции JIT -компилятором IL -кода exe-файла в машинный код. В результате, итоговый машинный код практически не содержит SSE -инструкций и векторные блоки центрального процессора фактически простаивают.
При использовании вершинных шейдеров все обстоит несколько иначе. На i946GZ и аналогичных GPU без аппаратных вершинных процессоров вершинные шейдеры эмулируются DirectX посредством специальной подсистемы Processor Specific Geometry Pipeline (PSGP). PSGP автоматически выполняет компиляцию вершинного шейдера в набор инструкций текущего CPU, задействовав весь потенциал данного процессора на 100%. Полученный код активно использует блоки SSE, параллельную обработку нескольких вершин всеми ядрами CPU и не содержит каких-либо ненужных промежуточных проверок "на всякий случай ". В результате он работает заметно быстрее по сравнению с аналогом на C#, что мы и наблюдаем.
Итак, вершинные шейдеры позволяют значительно поднять производительность приложения. Но не стоит забывать, что это упреждение верно лишь при сравнении производительности C# и HLSL -кода, использующего одинаковый алгоритм. Центральный процессор предоставляет разработчику использовать значительно более гибкие алгоритмы, так что на практике все обстоит несколько сложнее. Но в любом случае, вершинные шейдеры позволяют разгрузить центральный процессор, освободив его ресурсы для других задач.
Заключение
В этой лекции мы познакомились с новыми возможностями языка HLSL применительно к программированию вершинных шейдеров: работе с отдельными компонентами вектора, математическими операторами, встроенными функциями, параметрами эффекта и особенностями оператора if. Так же была рассмотрена IDE для разработки шейдеров NVIDIA FX Composer 2.0, которая, учитывая рост сложности наших эффектов, пришлась как нельзя кстати. Учитывая, что вершинный шейдер выполняется для каждой вершины, число которых может измеряться сотнями тысяч, очень важно уделять внимание качеству кода и оптимизации вершинного шейдера. А для этого очень полезно иметь хотя бы поверхностное представление о том, что твориться под капотом HLSL, в частности о языках Vertex Shader. Поэтому мы изучили основы архитектуры виртуального процессора Vertex Shader 1.1 и его систему команд.
Андрей Леонов