Инспектор

Вы можете этот курс.
Опубликован: 12.11.2012 | Уровень: для всех | Доступ: платный
Лекция 12:
Домен "Эксплуатация и сопровождение": управление службой технической поддержки и инцидентами
Аннотация:
В лекции описаны основные аспекты построения сервис-деска для разрешения инцидентов.
Ключевые слова: сервис-деск, service, ИТ-инцидент, incident, эксплуатация, SLA, информация, ITIL, мониторинг, запись, срочность, категорирование, работ, очередь, эскалация, escalation, деятельность, диагностика, группа, пользователь, запрос, печать, Дополнение, мера
DS 8. Управление службой технической поддержки и инцидентами
Своевременное и эффективное реагирование на запросы и проблемы пользователей, требует хорошо организованной и отлаженной службы поддержки и управления инцидентами. Данный процесс включает в себя создание службы поддержки с функциями регистрации инцидентов, анализа инцидентов и тенденций, а также разрешения возникших проблем. Служба поддержки в ИТ часто называется сервис-деск. Сервис-деск (Service desk) – точка контакта пользователей ИТ-услуг со службой ИТ. ИТ-инцидент (IT Incident) – любое событие, не являющееся штатным элементом ИТ-сервиса, которое причиняет или может причинить сбой или снижение качества[1].
Данный процесс предназначен для максимально быстрого восстановления нормальной эксплуатации услуги и минимизации неблагоприятного влияния на бизнес в случае возникновения инцидента. Под "нормальной эксплуатацией услуги" здесь понимается эксплуатация в соответствии с SLA. Процесс рассматривает все события, которые нарушают или могут нарушить нормальную эксплуатацию услуги. Информация о таких событиях поступает из двух основных источников – обращения в службу технической поддержки (сервис-деск) и система мониторинга.
Управление службой технической поддержки и инцидентами помогает бизнесу тем, что:
- быстро находит и разрешает инциденты, в результате чего снижается время простоя услуг, что в целом увеличивает показатели доступности услуг;
- выравнивает деятельности ИТ в соответствии с приоритетами бизнеса;
- увеличивает способность выявления возможностей для улучшения услуг в результате расследования инцидентов;
- сервис-деск, разрешая инциденты, определяет дополнительные требования ИТ и бизнеса к услугам и обучению.
Время разрешения инцидента обычно формализовано в рамках SLA, OLA и других базовых соглашений. Команды поддержки должны быть готовы к соблюдению временных ограничений.
Модель инцидентов описывает последовательность действий при возникновении определенного типа инцидентов. Использование моделей инцидентов позволяет стандартизовать процесс и ускорить его. Этот подход применим в отношении часто возникающих "стандартных" инцидентов. "Нестандартные" случаи обрабатываются отдельно, например, инциденты, связанные с информационной безопасностью. В отдельную категорию выделяются "значительные инциденты", которые должны разрешаться максимально быстро. Значительный инцидент (Major Incident) наивысшая категория влияния для инцидента. Значительный инцидент означает значительные потери для бизнеса. То, какие инциденты будут считаться значительными, каждая организация решает индивидуально.
На рис.12.1 схематически отображены основные деятельности в рамках Управления инцидентами. Порядок взят из публикаций ITIL.
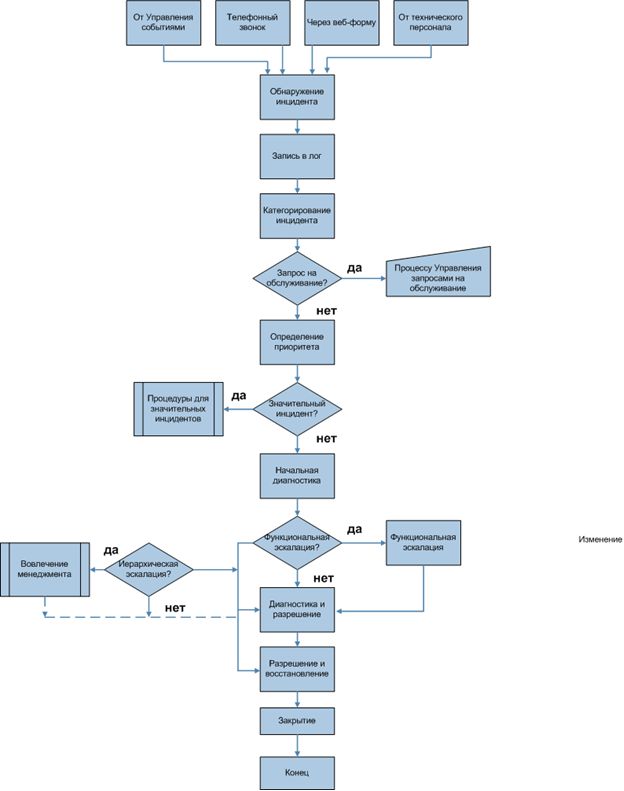
Рассмотрим основные этапы, изображенные на рис.12.1. Так как последовательность действий взята из ITIL, учтите, что в COBIT нет отдельного процесса для Управления запросами на обслуживание. Таким образом запросы на обслуживания решаются службой технической поддержки.
Для того чтобы разрешить инцидент, его необходимо сначала обнаружить, то есть идентифицировать. С точки зрения непрерывности бизнеса неприемлемо ждать обращений пользователей или технического персонала в сервис-деск. Все ключевые компоненты должны контролироваться, чтобы своевременно обнаруживать сбои или возможности их возникновения - мониторинг.
После того, как инцидент обнаружен, информацию о нем необходимо занести в лог. В логе должно быть отображено время обнаружения инцидента, вне зависимости от того, как он был обнаружен – по звонку в сервис-деск или в результате работы автоматических агентов. В логе также необходимо записать всю связанную с инцидентом информацию. Запись об инциденте должна послужить базой для его разрешения соответствующей командой поддержки.
Запись об инциденте должна включать:
- уникальный идентификатор инцидента;
- категорию инцидента;
- срочность инцидента. Срочность (Urgency) – мера того, насколько быстро с момента своего появления инцидент, проблема или изменение приобретет существенное влияние на бизнес. Например, инцидент с высоким уровнем влияния может иметь низкую срочность до тех пор, пока это влияние не затрагивает бизнес в период закрытия финансового года. Влияние и срочность используются для назначения приоритета.
- влияние инцидента;
- приоритет инцидента;
- дата и время записи;
- Имя/ID человека или группы, сделавшей запись об инциденте;
- метод уведомления;
- имя/отдел/номер/расположение пользователя;
- метод обратной связи;
- описание симптомов;
- статус инцидента;
- связанные конфигурационные единицы;
- группа поддержки/сотрудник, к кому переадресован инцидент;
- связанная с инцидентом проблема/известная ошибка;
- деятельности, осуществленные для разрешения инцидента;
- время и дата разрешения инцидента;
- категория закрытия;
- время и дата закрытия[5].
Следующий этап разрешения инцидента – категорирование. Оно необходимо для дальнейших работ, в частности, поиска известных ошибок и проблем, которые могли послужить причиной для возникновения инцидента. Обычно используется три-четыре уровня категорирования (рис.12.2).
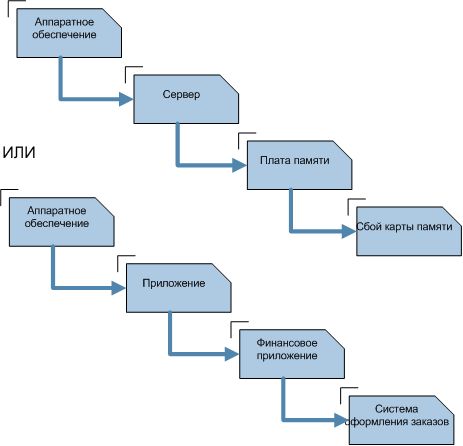
Нет стандартных методов для категорирования инцидентов, каждая организация сама определяет, какие категории будет использовать.
Приоритет инцидента определяется исходя из двух понятий – срочности и влияния. Влияние в отношении инцидентов чаще всего определяется на основе количества пользователей, которые он затронул. Тем не менее, этот показатель не всегда является объективным. В некоторых случаях влияние инцидента даже на одного единственного пользователя может оказать значительное негативное влияние на бизнес в целом.
Другие факторы, которые можно использовать для оценки влияния:
- риск для жизни или сегмента;
- количество услуг, которые затрагивает инцидент;
- уровень финансовых потерь;
- влияние на бизнес-репутацию;
- возникновение нарушений законодательства и требований регуляторов.
Александр Медов
|
Здравствуйте, прошел курс МБА Управление ИТ-проектами и направил документы на получение диплома почтой. Подскажите, сроки получения оного в бумажной форме? : |