Алгоритмы сжатия изображений без потерь
13.1. Необходимость сжатия изображений
Типичное изображение, полученное цифровой фотокамерой, имеет разрешение порядка 3000x2000, т.е. около 6 мегапикселей; для передачи цвета обычно используется 24 бита на пиксель. Таким образом, объем исходных данных составляет порядка 17 мегабайт. Для профессиональных устройств ввода изображений размер получаемого растра может быть значительно больше, а глубина цвета - достигать 48 бит на пиксель ( "Современные аппаратные средства растровой графики" ). Соответственно, размер одного изображения может быть больше 200 мегабайт. Поэтому весьма актуальными являются алгоритмы сжатия изображений, или, иными словами, алгоритмы, которые позволяют уменьшить объем данных, представляющих изображение.
Существуют два основных класса алгоритмов:
- A называется алгоритмом сжатия без потерь (англ. lossless compression), если существует алгоритм A-1 (обратный к A ) такой, что для любого изображения I A(I) = I1 и A-1(I1) = I. Изображение I задано как множество значений атрибутов пикселей; после применения к I алгоритма A получаем набор данных I1. Сжатие без потерь применяется в таких графических форматах представления изображений, как: GIF, PCX, PNG, TGA, TIFF1Вообще говоря, данный формат также поддерживает сжатие с потерями., множество собственных форматов от производителей цифровых фотокамер, и т.д.);
- A называется алгоритмом сжатия c потерями (англ. lossy compression), если он не обеспечивает возможность точного восстановления исходного изображения. Парный к A алгоритм, обеспечивающий примерное восстановление, будем обозначать как A*: для изображения I A(I) = I1, A*(I1) = I2 и при этом полученное восстановленное изображение I2 не обязательно точно совпадает с I. Пара A, A* подбирается так, чтобы обеспечить большие коэффициенты сжатия и тем не менее сохранить визуальное качество, т.е. добиться минимальной разницы в восприятии между I и I2. Сжатие с потерями применяется в следующих графических форматах: JPEG, JPEG2000 и т.д.
Эта лекция посвящена сжатию без потерь, что требуется в случаях, когда информация была получена большой ценой (например, медицинские изображения или снимки со спутников), либо в других случаях, когда даже малейшие искажения нежелательны [2].
13.2. Несуществование идеального алгоритма
Как уже было упомянуто в предыдущем пункте, изображение I рассматривается как множество (последовательность) значений атрибутов пикселей. В дальнейшем в этой лекции все алгоритмы и утверждения относятся как к изображениям, так и к произвольным последовательностям, элементы которых могут принимать конечное количество значений.
Утверждение 13.2.1. Не существует алгоритма, сжимающего без потерь любой набор данных.
Существует 2N последовательностей размера N битов  (будем рассматривать бит как минимальный носитель информации). Пусть найдется алгоритм A такой, что
(будем рассматривать бит как минимальный носитель информации). Пусть найдется алгоритм A такой, что  , где |I| - объем данных (длина последовательности). Пусть M = max Mk, тогда M < N. Существует 21 + 22 + ... + 2M последовательностей длины, меньшей или равной M. Но 21+22+...+2M = 2M+1-2 < 2N. Противоречие.
, где |I| - объем данных (длина последовательности). Пусть M = max Mk, тогда M < N. Существует 21 + 22 + ... + 2M последовательностей длины, меньшей или равной M. Но 21+22+...+2M = 2M+1-2 < 2N. Противоречие.
Из утверждения следует, что имеет смысл разрабатывать алгоритмы, которые бы эффективно сжимали определенный класс изображений; в то же время для этих алгоритмов всегда будут существовать изображения, для которых они не обеспечат сжатия.
13.3. Алгоритмы кодирования длины повторения (RLE)
Этот тип алгоритмов (алгоритмы кодирования длины повторения2В литературе часто встречается и другое название - групповое кодирование. ( RLE3англ. Run Length Encoding )) базируется на простейшем принципе: будем заменять повторяющиеся группы элементов исходной последовательности на пару (количество, элемент), либо только на количество.
RLE - битовый уровень
Будем рассматривать исходные данные на уровне последовательности битов; например, представляющих черно-белое изображение. Подряд обычно идет несколько 0 или 1, и можно помнить лишь количество идущих подряд одинаковых цифр. Т.е. последовательности 0000 11111 000 11111111111 соответствует набор чисел количеств повторений 4 5 3 11. Возникает следующий нюанс: числа, обозначающие количество повторений, также надо кодировать битами. Можно считать, что каждое число повторений изменяется от 0 до 7 (т.е. можно закодировать ровно тремя битами), тогда последовательности 11111111111 можно сопоставить числа 7 0 4, т.е. 7 единиц, 0 нулей, 4 единицы. Для примера, последовательность, состоящая из 21 единицы, 21 нуля, 3 единиц и 7 нулей закодируется так: 111 000 111 000 111 111 000 111 000 111 011 111, т.е. из исходной последовательности, которая имеет длину 51 бит, получили последовательность длиной 36 бит.
Идея этого метода используется при передаче факсов.
RLE - байтовый уровень
Предположим, что на вход подается полутоновое изображение, где на значение интенсивности пикселя отводится 1 байт. Ясно, что по сравнению с черно-белым растром ожидание длинной цепочки одинаковых битов существенно снижается.
Будем разбивать входной поток на байты (буквы) и кодировать повторяющиеся буквы парой (количество, буква).
Т.е. AABBBCDAA кодируем (2A) (3B) (1C) (1D) (2A). Однако могут встречаться длинные отрезки данных, где ничего не повторяется, а мы кодируем каждую букву парой (цифра, буква).
Пусть у нас есть фиксированное число (буква) M (от 0 до 255 ). Тогда одиночную букву  можно закодировать ею самою, - выход = S, а если букв несколько или
можно закодировать ею самою, - выход = S, а если букв несколько или 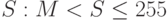 , то выход = CS, где C > M, а C - M - количество идущих подряд букв S. Для примера приведем только алгоритм декодирования.
, то выход = CS, где C > M, а C - M - количество идущих подряд букв S. Для примера приведем только алгоритм декодирования.
// M - фиксированная граница
// считываем символы последовательно из входного потока
// in - вход - сжатая последовательность
// out - выход - разжатая последовательность
while( in.Read( c ) )
{
if( c > M )
{ // случай счетчика
n = c - M;
in.Read( c );
for (i = 0; i < n; i++)
out.Write( c );
}
else // случай просто символа
out.Write( c );
}
Листинг
13.1.
Алгоритм декодирования RLE - байтовый уровень
Число M обычно равно 127. Чаще используется модификация этого алгоритма, где признаком счетчика служит наличие единиц в 2 старших битах считываемого символа. Остальные 6 битов суть значение счетчика.
Такая модификация данного алгоритма используется в формате PCX. Однако модификации данного алгоритма редко используются сами по себе, т.к. подкласс последовательностей, на которых данный алгоритм эффективен, относительно узок. Модификации алгоритма используются как одна из стадий конвейера сжатия (например в формате JPEG, "Сжатие изображений с потерями" ).