Опубликован: 16.04.2007 | Доступ: свободный | Студентов: 5404 / 926 | Оценка: 4.18 / 4.08 | Длительность: 16:03:00
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 12:
Концепции распределенных баз данных
Репликация в MySQL
Программа MySQL реализует функции автоматической репликации данных между главным и подчиненными серверами. Главный сервер ведет журнал изменений, который делается доступным для одного или нескольких подчиненных серверов. Простейшая схема репликации с участием одного главного и двух подчиненных серверов изображена на рис 12.3.
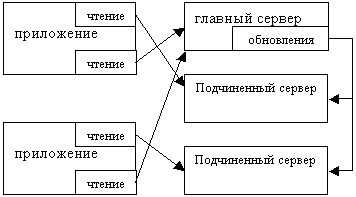
Все серверы работают под управлением MySQL на разных компьютерах подключенных к сети. В целях синхронизации подчиненные серверы регулярно связываются с главным сервером. Последний фиксирует каждое изменение в двоичном журнале (см. лекцию "Физическое хранение данных"). Если не считать короткие промежутки времени, в течение которых происходит синхронизация, подчиненные серверы содержат зеркальные копии базы данных.
Клиенты могут посылать запросы на выборку как главному, так и любому подчиненному серверу. Запись данных должна происходить только на главном сервере, иначе изменения останутся локальными. В схеме на рис 12.3 запросы на выборку направляются только подчиненным серверам, что позволяет главному серверу сосредоточиться на обновлениях.
На подчиненном сервере запускается отдельный поток, который периодически опрашивает главный сервер на предмет наличия изменений. Однако бывает так, что сервер одновременно является и главным, и подчиненным. Тогда становится возможной схема репликации, изображенная на рис 12.4. Здесь есть четыре сервера, каждый из которых играет двойную роль. Приложение направляет "своему" серверу запросы как на выборку, так и на обновление данных. Обновление, произошедшее на одном сервере, передается по цепочке остальным серверам.
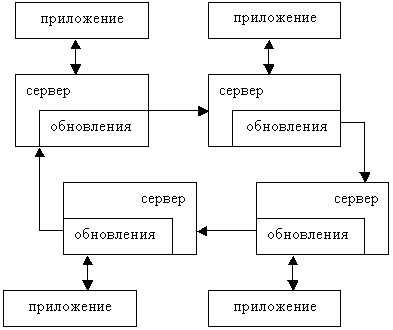
Приложение должно предотвращать несогласованные обновления. Рассмотрим такой случай. Серверы А и Б являются друг для друга главным и подчиненным сервером. Оба используют таблицу сообщений с первичным ключом-счетчиком. В определенный момент два пользователя одновременно создают новые сообщения, по одному на каждом сервере. Если таблицы раньше были синхронизированы, то теперь в каждой из них будет новая запись с идентификатором, совпадающим с идентификатором другой записи на другом сервере. Можно избежать этой неприятности, используя внешний генератор идентификаторов, при условии, что он будет однопотоковым.
В схеме на рис 12.4 каждое приложение взаимодействует с одним сервером, хотя это необязательно. Если серверы расположены рядом, можно формировать пул серверов. Тогда при выборе сервера приложение сможет учитывать возможность сбоя или применять алгоритм выравнивания нагрузки.
Подчиненный сервер контролирует, какое изменение было получено от главного сервера последним. По умолчанию сведения об этом находятся в файле master info.
Если обновление приводит к появлению ошибки, то поток, управляющий синхронизацией, останавливается. В этом случае сервер записывает сообщение в журнал ошибок. В MySQL версии 3.23.39 механизм репликации имеет ряд ограничений. В основном все они связаны с тем, что изменения фиксируются только в двоичном журнале. Функция RAND() по умолчанию инициализирует генератор псевдослучайных чисел значением системных часов, но это значение не сохраняется в двоичном журнале. В подобной ситуации можно инициализировать генератор самостоятельно с помощью функции UNIX TIMESTAMP().
Вспомните, что изменения таблиц привилегий в базе данных mysql не вступят в силу, пока не будут очищены буферы привилегий. Но дело в том, что в двоичном журнале не отслеживаются инструкции FLUSH, поэтому старайтесь не менять таблицы напрямую, а пользуйтесь инструкциями GRANT и REVOKE.
Значения переменных не реплицируются. Если в обновлении строки участвовала переменная, то на подчиненном сервере будет использовано локальное, а не реальное значение этой переменной.
Чтобы включить функции репликации, нужно отредактировать конфигурационные файлы сервера. Ниже перечислены опции демона mysqld, имеющие отношение к репликации. Все они были описаны в лекции "Утилиты командной строки".
--binlog-do-db=база данных --binlog-ignore-db=база данных --log-bin-index=каталог --log-bin[=каталог] --log-slave-updates --master-connect-retry=секунды --master-host=узел --master-info-file=файл --master-password=пароль --master-port=порт --master-user=пользователь --replicate-do-db=база данных --replicate-do-table=база данных.таблица --replicate-ignore-db=база данных --replicate-ignore-table= база данных.таблица --replicate-rewrite-db=главный->подчиненный --replicate-wind-do-table=шаблон --replicate-wind-ignore-table=шаблон --server-id=идентификатор
Прежде чем редактировать конфигурационные файлы, создайте на главном сервере учетную запись, чтобы подчиненный сервер мог получать обновления. В листинге 12.3 показана инструкция, создающая пользователя user с привилегией FILE. Никакие другие привилегии подчиненному серверу не нужны. В данном примере пользователь может посылать запросы с любого узла, но на практике обычно указывают конкретное доменное имя.
GRANT FILE ON *.* ТО slave IDENTIFIED BY ‘password’Листинг 12.3.
Теперь нужно остановить главный сервер или заблокировать все таблицы, подлежащие репликации. Создайте точные копии реплицируемых баз данных и лишь затем редактируйте конфигурационные файлы. Вспомните, что таблицы MySQL имеют системно независимый формат. Это позволяет копировать и перемещать файлы, не меняя их формат. В листинге 12.4 создается tar архив одной базы данных. Можно также выполнить на подчиненном сервере инструкцию LOAD TABLE, чтобы получить точную копию нужной таблицы.
[/usr/local/var]# tar cvfz freetimedb.tar.gz. /freetime/Листинг 12.4.
Далее требуется включить двоичный журнал на главном сервере, внеся изменения в конфигурационный файл /etc/my.cnf Соответствующая опция называется log bin. С помощью опции server id серверу присваивается уникальный идентификатор. В листинге 12.5 показаны две строки, которые добавляются в раздел [mysqld] конфигурационного файла. После внесения изменений нужно перезапустить главный сервер.
log-bin server_id=1Листинг 12.5.