Московский государственный университет путей сообщения
Опубликован: 22.12.2006 | Доступ: свободный | Студентов: 2514 / 629 | Оценка: 4.07 / 4.02 | Длительность: 16:07:00
ISBN: 978-5-9556-0071-0
Специальности: Разработчик аппаратуры
Лекция 1:
Параллельные структуры вычислительных систем
"Исторические" модели
Векторная ВС ПС-2000
Разрабатывалась как проблемно-ориентированная ВС для задач обработки геофизической информации, информации со спутников в интересах геологии, картографии, обработки изображений, моделирования поведения среды и т.д. Является типичной иллюстрацией типа ОКМД.
Схема ВС приведена на рис. 1.9.
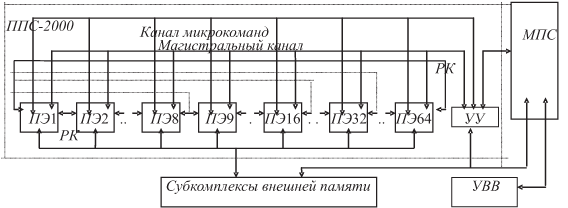
Основу ПС-2000 составляет параллельный процессор с общим потоком команд ППС-2000, содержащий до 64 ПЭ.
Отмечая типичные архитектурные
особенности моделей, иллюстрируя их на архитектурах ВС, ставших
классическими, уделим второстепенное внимание быстро устаревающим
характеристикам этих ВС. Однако отметим, что ПЭ ППС-2000 — 24-разрядный
микропроцессор с производительностью 3 млн оп./с, а это было
значительным достижением в начале 1980-х годов.
Соседние ПЭ связаны регулярными каналами РК для оперативного обмена данными. В связи с проблемной ориентированностью ВС это обеспечивает быстрый обмен при обработке "соседними" ПЭ "соседних" же элементов поверхностей, конечно же, информационно взаимосвязанных. Связь с помощью РК — циклическая, в частности, ПЭ1 с помощью РК связан с ПЭ64. Т.е. при "прокатывании" 64 ПЭ по длинной последовательности обрабатываемых элементов поверхности ПЭ1 и ПЭ64 являются "соседними": после элемента поверхности, обрабатываемого ПЭ64, следует элемент поверхности, обрабатываемый ПЭ1. Затем пошли дальше, превратив векторную ППС-2000 в матричную ВС.
Ввели сегментирование множества процессоров (процессоров решающего поля ). 64 ПЭ разбиваются или на 8 сегментов по 8 ПЭ, или на 4 сегмента по 16 ПЭ, или на 2 сегмента по 32 ПЭ. Это осуществляется, прежде всего, за счет установления связи с помощью РК между первым и последним ПЭ каждого сегмента. Тогда при обработке поверхности ПЭ "прокатываются" циклически не только по "длинному" вектору, но и, при сегментировании, по матричным элементам поверхности, как будет показано далее.
Для общей связи всех элементов ППС-2000, включая УУ, используется магистральный канал — общая шина. По магистрали микрокоманд каждому ПЭ сообщаются команды, микропрограммы операций и микрокоманды из УУ.
ППС-2000 имеет распределенную память.
В ППС-2000 предусмотрена двухуровневая схема управления: на уровне микрокоманд и команд. Память для их хранения — в УУ. На микрокомандном уровне пишутся отдельные фрагменты задачи — подпрограммы процедур, на командном — последовательность обращения к этим подпрограммам.
Основным, задающим, является вычислительный процесс в мониторной подсистеме МПС. В ней в режиме разделения времени могут выполняться несколько задач. С ППС-2000 в данный момент может быть связана только одна задача. Т.е. ППС-2000 по отношению к малой машине (типа СМ-2), выполняющей функции МПС, является интеллектуальным терминалом с последовательным доступом.
В обычном режиме набор процедур, выполняемых в ППС-2000, по запросам со стороны МПС, определяется заранее. Микропрограммы, реализующие этот набор процедур, загружаются в память ППС-2000 заранее. Если в ходе вычислительного процесса в МПС возникает необходимость в какой-либо процедуре из этого набора, задача запускает соответствующую микропрограмму и передает ей необходимые данные.
Возможна и динамическая загрузка микропрограмм в память ППС-2000.
Матричные ВС
Матричная ВС также является типичным представителем ОКМД, расширением принципа векторных ВС.
Классическим примером, прототипом и эталоном стала ВС ILLIAC 1V, разработанная в 1971 г. в Иллинойском университете и в начале 1972 г. установленная в Эймском научно-исследовательском центре NASA (Калифорния).
Одна последовательность команд программы управляет работой множества 64 ПЭ, одновременно выполняющих одну и ту же операцию над данными, которые могут быть различными и хранятся в ОП каждого ПЭ. (Производительность — до 200 млн. оп./с)
В целом структура центральной части может быть представлена аналогичной векторной ВС (рис. 1.10).
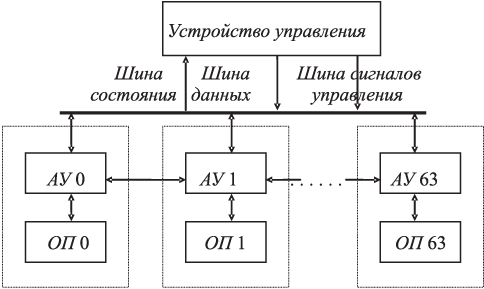
УУ — фактически простая вычислительная машина небольшой производительности и может выполнять операции над скалярами одновременно с выполнением матрицей ПЭ операций над векторами или матрицами. Посылает команды в независимые ПЭ и передает адреса в их ОП.
К центральной части подключена система ввода-вывода с управляющей машиной В-6500, устройство управления вводом-выводом, файловые диски, буферная память и коммутатор ввода-вывода. Операционная система, ассемблеры и трансляторы размещаются в памяти В-6500.
Почему же ВС — матричная?
ПЭ образуют матрицу, в которой информация от одного ПЭ к другому может быть передана через сеть пересылок данных при помощи специальных команд обмена. Регистры пересылок (рис. 1.11) каждого i -го ПЭ связаны высокоскоростными линиями обмена с регистрами пересылок ближайшего левого ( i-1 -го) и ближайшего правого ( i+1 )-го ПЭ, а также с регистрами пересылок ПЭ, отстоящего влево на 8 позиций от данного ( i-8 )-й и отстоящего вправо на 8 позиций от данного ( i+8 )-й, при этом нумерация ПЭ рассматривается как циклическая с переходом от 63 к 0 (нумерация возрастает по mod 64 ) слева направо и от 0 к 63 справа налево.
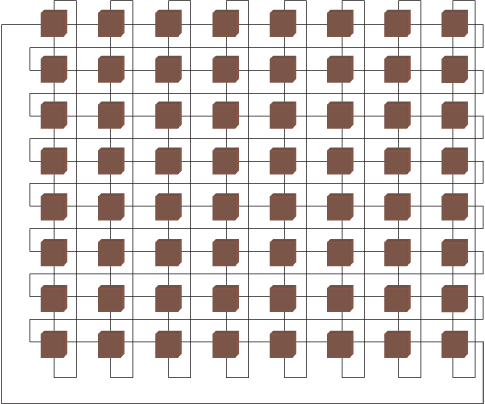
Расстояния между ПЭ в сети пересылок и соответствующие пути передачи информации задаются комбинациями из (-1, +1, -8, +8).
Предусмотрено маскирование ПЭ. Каждый ПЭ может индексировать свою ОП независимо от других ПЭ, что важно для операций матричной алгебры, когда к двухмерному массиву данных требуется доступ как по строкам, так и по столбцам.
Доступ к ОП имеют АУ соответствующего ПЭ, УУ системы и подсистема ввода-вывода. Управление доступом и разрешение конфликтов при доступе к ОП осуществляет УУ системы.
Система эффективна при решении задач большой размерности, использующих исчисление конечных разностей, матричной арифметики, быстрого преобразования Фурье, обработки сигналов и изображений, линейного программирования и др.
Например, приближенные методы решения задач математической физики и, прежде всего, — системы дифференциальных уравнений используют исчисление конечных разностей (конечно-разностные методы решения, "метод сеток").
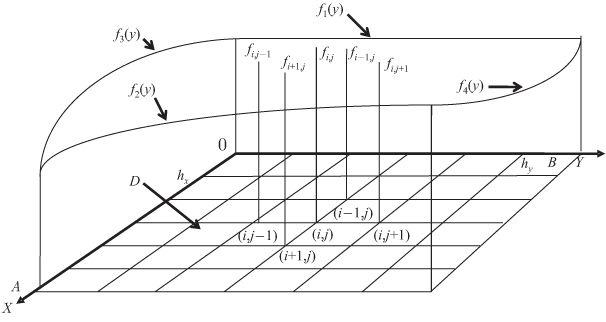
Кратко рассмотрим план решения подобной задачи на матричной ВС.
Пусть необходимо решить уравнение с частных производных
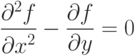
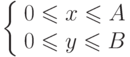
Граничные условия:
f(0,y)= f1(y),
f(A,y)= f2(y),
f(x,0)= f3(x),
f(x,B)= f4(x).
Частные производные можно выразить через конечные разности несколькими способами, например:
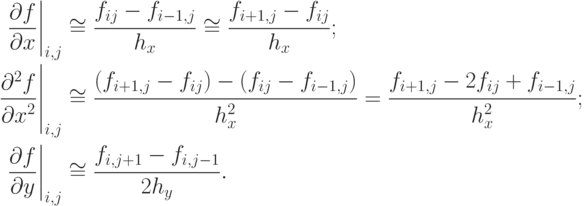
Подставив полученные выражения в уравнение, получим основное рекуррентное соотношение для нахождения значения функции через ее значения в соседних четырех узлах:
fi, j = 0,5 fi+1, j + 0,5 fi-1, j - 0,25 hx2/hy(fi, j+1 - fi, j-1).
Распараллеливание вычислений и "прокатывание" матрицей ПЭ области B — многократные, до получения необходимой точности — очевидны.
А именно: первоначально в одном цикле итерации 64 ПЭ по выведенной формуле рассчитывают 8 x 8 узловых значений функции близ вершины координат, "цепляя" при этом граничные значения. Затем производится смещение вправо на следующую группу узловых значений функции. По окончании обработки по горизонтали производится смещение по вертикали и т.д. При следующей итерации процесс повторяется. От итерации к итерации распространяется влияние граничных условий на рассчитываемые значения функции. Процесс сходится для определения значений функции-решения в узлах сетки с требуемой точностью.
Вернемся к отечественной разработке ПС-2000 (ПС-2100) —
векторной ВС. В ней предусмотрена возможность сегментации процессоров, при
которой последний процессор в сегменте связывается регулярным каналом
(аналог высокоскоростной линии) с первым. Все 64 процессора могут
составить один сегмент, могут быть сформированы два сегмента по 32 ПЭ,
четыре по 16, 8 по 8 ПЭ. Итак,
получается идеальная схема для "покрытия" двумерной подобласти обсчитываемой области. Правда,
отсутствуют быстрые связи по вертикали, что должно быть возмещено
хранением всей информации по столбцам в ОП каждого ПЭ. Зато, при смещении
процессоров на смежную подобласть по горизонтали, последний ПЭ предыдущей
подобласти остается "левым" для первого в новой подобласти. Т.е.
при таком смещении сохраняется регулярность фактических связей между узлами
сетки.
В ILLIAC-1V такая регулярность сохранялась бы, если бы существовали быстрые связи между ПЭ7 и ПЭ0, ПЭ15 и ПЭ8 и т.д., то есть циклически по строкам матрицы.
Как видим, такие связи учтены при более поздних разработках матричных ВС.