Московский государственный университет путей сообщения
Опубликован: 22.12.2006 | Доступ: свободный | Студентов: 2514 / 629 | Оценка: 4.07 / 4.02 | Длительность: 16:07:00
ISBN: 978-5-9556-0071-0
Специальности: Разработчик аппаратуры
Лекция 1:
Параллельные структуры вычислительных систем
"Фон-Неймановские" и "не-Фон-Неймановские" архитектуры
Немного истории. Первую ЭВМ создал в 1939 г. в США профессор Джон Атанасов, болгарин, со своим аспирантом К.Берри. Две малые ЭВМ, созданные ими в период 1937 — 1942 гг., были прототипами большой ЭВМ АВС для решения систем линейных уравнений, которая в 1942 г. доводилась по устройствам ввода-вывода и должна была войти в строй в 1943 г., но призыв Атанасова в армию в 1942 г. воспрепятствовал этому. Проект электронной ЭВМ Эниак (Electronics Numerical Integrator and Computer) был сделан в 1942 г. Д.Моучли и Д.Эккертом и осуществлен в 1945 г. в Муровской электротехнической лаборатории Пенсильванского университета. В 1946 г. Эниак был публично продемонстрирован в работе. В нем впервые были применены триггеры. Рождение Эниак считают началом компьютерной эры, посвящая ему научные симпозиумы и другие торжественные мероприятия. (Международный симпозиум, посвященный 50-летию первой ЭВМ, был проведен и в Москве в июне 1996 г.)
Однако еще в начале 40-х годов XX века Атанасов поделился с Моучли информацией о принципах, заложенных в ЭВМ АВС. Хотя Моучли впоследствии утверждал, что он не воспользовался этой информацией в патенте на Эниак, суд не согласился с этим. Вернувшись из армии после войны, Атанасов узнал, что более мощная ЭВМ Эниак уже создана, и потерял интерес к этой теме, не поинтересовавшись, насколько Эниак похож на его ЭВМ АВС.
Известный английский математик Алан Тьюринг был не только теоретиком по информации и теории алгоритмов, автором теоретического автомата "машины Тьюринга", но и талантливым инженером, создавшим в начале 1940-х годов первую работающую специализированную ЭВМ. Эта ЭВМ под названием "Колосс" была сконструирована и сделана им совместно с Х.А.Ньюменом в Блетчи (Англия) и начала работать в 1943 г. Сообщения о ней своевременно не публиковались, т.к. она использовалась для расшифровки секретных германских кодов во время войны.
Основные архитектурно-функциональные принципы построения ЭВМ были разработаны и опубликованы в 1946 г. венгерским математиком и физиком Джоном фон Нейманом и его коллегами Г.Голдстайном и А.Берксом в ставшем классическим отчете "Предварительное обсуждение логического конструирования электронного вычислительного устройства". Основополагающими принципами ЭВМ на основании этого отчета являются: 1) принцип программного управления выполнением программы, и 2) принцип хранимой в памяти программы. Они легли в основу понятия фон-Неймановской архитектуры, широко использующей счетчик команд .
Вернемся к настоящему. Счетчик команд отражает "узкое горло", которое ограничивает поток команд, поступающих на исполнение, их последовательным анализом.
Альтернативной архитектурой является "не-фон-Неймановская" архитектура, допускающая одновременный анализ более одной команды. Поиски ее обусловлены необходимостью распараллеливания выполнения программы между несколькими исполнительными устройствами — процессорами. Счетчик команд при этом не нужен. Порядок выполнения команд определяется наличием исходной информации для выполнения каждой из них. Если несколько команд готовы к выполнению, то принципиально возможно их назначение для выполнения таким же количеством свободных процессоров. Говорят, что такие ВС управляются потоком данных (data flow).
Общая схема потоковых ВС представлена на рис. 1.4.
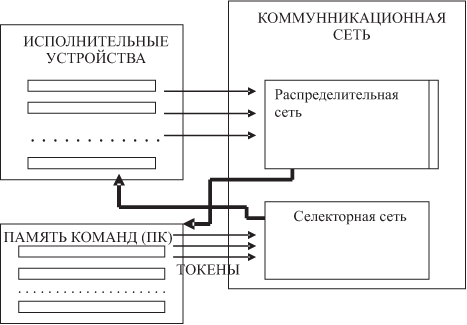
Программа или ее часть (сегмент) размещается в памяти команд ПК, состоящей из ячеек команд. Команды имеют структуру
{код операции, операнд 1, ..., операнд L,
адрес результата 1, ..., адрес результата M}В командах проверки условия возможно альтернативное задание адреса результата (ИЛИ — ИЛИ). Адреса результатов являются адресами ПК, т.е. результаты выполнения одних команд в качестве операндов могут поступать в текст других команд. Команда не готова к выполнению, если в ее тексте отсутствует хотя бы один операнд. Ячейка, обладающая полным набором операндов, переходит в возбужденное состояние и передает в селекторную сеть информационный пакет (токен), содержащий код операции и необходимую числовую и связную информацию. Он поступает по сети на одно из исполнительных устройств. Там же операция выполняется, и в распределительную сеть выдается результирующий пакет, содержащий результат вычислений и адреса назначения в ПК (возможно, за счет выбора альтернативы, т.е. такой выбор — тоже результат). По этим адресам в ПК результат и поступает, создавая возможность активизации новых ячеек. После выдачи токена в селекторную сеть операнды в тексте команды уничтожаются, что обеспечивает повторное выполнение команды в цикле, если это необходимо.
Селекторная и распределительная сети образуют коммуникационную сеть ВС.
Ожидаемая сверхвысокая производительность такой системы может быть достигнута за счет одновременной и независимой активизации большого числа готовых команд, проблематичном допущении о бесконфликтной передаче пакетов по сетям и параллельной работы многих исполнительных устройств.
Существует ряд трудностей, в силу которых "не-фон-Неймановские" архитектуры не обрели технического воплощения для массового применения в "классическом", отраженном выше, исполнении. Однако многие устройства используют данный принцип, но чаще всего взаимодействие процессоров при совместном решении общей задачи и их синхронизация при использовании общих данных основаны на анализе готовности данных для их обработки. Это дает основание многим конструкторам заявлять, что в своих моделях они реализовали принцип data flow.
Системы с общей и распределенной памятью
Системы с общей (разделяемой) оперативной памятью образуют современный класс ВС — многопроцессорных супер-ЭВМ. Одинаковый доступ всех процессоров к программам и данным представляет широкие возможности организации параллельного вычислительного процесса (параллельных вычислений). Отсутствуют потери реальной производительности на межпроцессорный (между задачами, процессами и т.д.) обмен данными (рис. 1.5a).
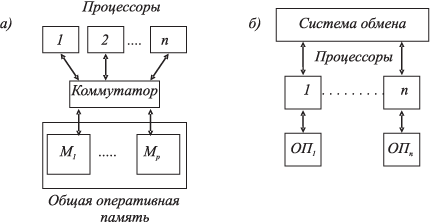
Системы с распределенной памятью образуют вычислительные комплексы (ВК) — коллективы ЭВМ с межмашинным обменом для совместного решения задач (рис. 1.5б). В ВК объединяются вычислительные средства систем управления, решающие специальные наборы задач, взаимосвязанных по данным. Принято говорить, что такие ВК выполняют распределенные вычисления, а сами ВК называют распределенными ВК.
Другое, противоположное воплощение принципа МИМД — масспроцессорные или высокопараллельные архитектуры, объединяющие сотни — тысячи — десятки тысяч процессоров.
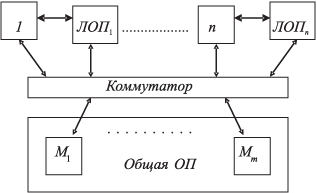
В современных супер-ЭВМ наметилась тенденция объединения двух принципов: общей (распределяемой) и распределенной (локальной) оперативной памяти (ЛОП). Такая структура используется в проекте МВК "Эльбрус-3" и "Эльбрус-3М" (рис. 1.6).
Способы межмодульного соединения (комплексирования)
Различают два противоположных способа комплексирования: с общей шиной (шинная архитектура) и с перекрестной (матричной) коммутацией модулей ВС (процессоров, модулей памяти, периферии).
На рис. 1.7 представлена система с общей шиной. Шина состоит из линий, по которым передаются информационные и управляющие сигналы.
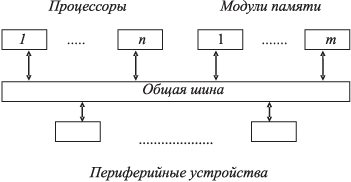
Шина используется в режиме разделения времени, при котором лишь один модуль в данный момент работает на передачу. Принимать принципиально могут все модули, хотя преимущественно информация при выдаче в нее адресуется. Применяется в микро- и мини-ЭВМ при сравнительно небольшом числе модулей. Практически производится разделение шины на управляющую, адресную и шину данных.
В высокопроизводительных ВС для возможности одновременного обмена многими парами абонентов используется перекрестная или матричная коммутация.
Матричный коммутатор можно представить (прямоугольной) сеткой шин. К одному концу каждой подсоединен источник-потребитель информации (рис. 1.8). Точки пересечения — узлы этой сетки — представляют собой управляющие ключи, которые соединяют или разъединяют соответствующие шины, устанавливая или прекращая связь между модулями. Реализуется связь "каждый с каждым". Одновременно могут связываться многие (до n/2 ) пары модулей.
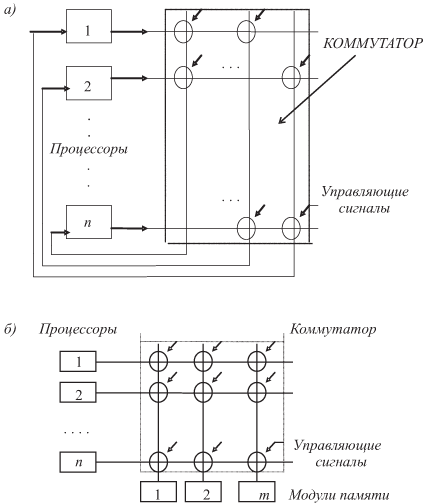
Рис. 1.8. Матричные коммутаторы: а) — перекрёстная коммутация процессоров, б) — коммутация процессоров и модулей памяти
На рис. 1.8а — перекрестная связь между процессорами в ВС с распределенной памятью, на рис. 1.8б — между n процессорами и m модулями ОП.