|
Здравствуйте, прошел курс "Концептуальное проектирование систем в AnyLogic и GPSS World". Можно ли получить по нему сертификат? У нас в институте требуют сертификаты для создания портфолио. |
Опубликован: 15.02.2013 | Доступ: свободный | Студентов: 257 / 0 | Длительность: 16:52:00
ISBN: 978-5-9556-0146-5
Темы: САПР, Программное обеспечение
Специальности: Архитектор программного обеспечения, Разработчик аппаратуры
Теги:
Лекция 2:
Модель обработки запросов сервером
Решение обратной задачи
Для решения обратной задачи возьмем количество запросов, ожидаемое время обработки которых нужно определить, N = 29 - результат решения прямой задачи.
Программа модели приведена ниже.
; Обработка запросов сервером. Обратная задача ; Задание исходных данных T1_ EQU 120 ; Средний интервал поступления запросов, с S1_ EQU 60000000 ; Среднее значение вычислительной сложности запросов, оп S2_ EQU 200000 ; Стандартное отклонение вычислительной сложности запросов, оп Q_ EQU 600000 ; Средняя производительность сервера, оп/c Emk EQU 5 ; Ёмкость входного буфера Koef EQU 1 ; Коэффициент изменения характеристик нормального распределения Koef1 EQU 1 ; Коэффициент учета дробной части N_ EQU 29 ; Количество запросов ; Сегмент имитации обработки запросов GENERATE (Exponential(1,0,T1_)) ; Источник запросов KolZap TEST L Q$Server,Emk,PotZap ; Занят ли буфер? QUEUE Server ; Встать в очередь к серверу SEIZE Server ; Занять сервер DEPART Server ; Покинуть очередь к серверу ADVANCE ((Normal(2,(S1_#Koef),(S2_#Koef)))/Q_) ; Имитация обработки запроса RELEASE Server ; Освободить сервер TRANSFER ,ObrZap ; Запрос отправляется в сегмент завершения моделирования PotZap TERMINATE ; Потерянные запросы ; Сегмент организации завершения моделирования и расчета результатов ObrZap TEST L X$Prog,TG1,Met1 ; Если X$Prog < TG1, SAVEVALUE Prog,TG1 ; то X$Prog = TG1 SAVEVALUE NZap,0 ; Обнуление счетчика обработанных запросов Met1 SAVEVALUE NZap+,1 ; Счет количества обработанных запросов TEST E X$NZap,N_,Ter1 ; Если X$NZap = N_, то TEST E TG1,1,Met2 ; если TG1 = 1, то SAVEVALUE VerObr,(N$ObrZap/N$KolZap) ; расчет и сохранение в ячейке VerObr вероятности обработки запросов SAVEVALUE TimeNZap,((AC1-X$AC2)/(X$Prog#Koef1)) ;расчет и сохранение в ячейке TimeNZap времени обработки запросов SAVEVALUE AC2,AC1 ; Запомнить абсолютное модельное время в ячейке АС2 Met2 SAVEVALUE NZap,0 ; Обнуление счетчика обработанных запросов TERMINATE 1 Ter1 TERMINATE START 1000,NP ; Прогоны до установившегося режима RESET ; Сброс накопленной статистики START 9604 ; Количество прогонов модели
При решении обратной задачи один прогон определяется заданным количеством запросов N_, которые нужно обработать сервером, а не временем моделирования. Для этого организован счетчик обработанных запросов в виде сохраняемой ячейки X$NZap. Как только содержимое X$NZap = N_, из счетчика завершений вычитается единица. Таким образом, фиксируется один прогон модели. После этого ячейка X$NZap обнуляется и начинается очередной прогон.
Для расчета времени обработки заданного количества запросов используется арифметическое выражение (AC1-X$AC2)/X$Prog. В состав этого выражения входят абсолютное модельное время АС1 и опять количество прогонов. Запоминается количество прогонов также как и при решении прямой задачи.
Кроме этого, в арифметическом выражении есть сохраняемая ячейка X$AC2. Дело в том, что команда RESET не влияет на абсолютное модельное время АС1. Время же выполнения 1000 прогонов до установившегося режима не должно участвовать в расчёте. Поэтому оно запоминается, а затем вычитается из абсолютного модельного времени выполнения 1000 + 9604 = 10604 прогонов. Количество прогонов до установившегося режима может быть и другим.
В результате моделирования получим среднее время обработки 29 запросов 3579,401 с.
Фрагмент из отчета моделирования приведен ниже:
SAVEVALUE RETRY VALUE PROG 0 9604.000 NZAP 0 0 VEROBR 0 0.971 TIMENZAP 0 3579.401
А почему не 3600 сек? Ведь это же время моделирования было задано при решении прямой задачи? Потому что мы отбросили дробную часть, т. е. взяли 29, а не 29,161. Как же поступить, чтобы учесть и отброшенную дробную часть? Ведь в счётчике фиксируются обработанные запросы только целыми числами, а не дробными?
Для учёта десятых долей дробной части зададим N_ = 291, т. е. увеличим в 10 раз. Это нужно учесть и в арифметическом выражении: ((AC1-X$AC2)/(X$Prog#Koef1)). Переменной пользователя Koef1 задается значение 10. По завершении моделирования получим 3594,826 с. Этот результат уже ближе к 3600.
Для учёта сотых долей дробной части установим N_ = 2916, а Koef1 = 100. Получим 3602,099.
Вероятность обработки запросов в обоих случаях практически одна и та же, т. е. 0,971. Однако время моделирования существенно возрастает: 2 с, 21 с и 3 мин 34 c соответственно, т. е. более чем в 10 и 100 раз.
В примере обратной задачи также показано, что арифметические выражения можно не описывать отдельно до блоковой части программы вместе с заданием исходных данных (как в программе модели прямой задачи), а сразу записывать в соответствующих блоках, заключив в скобки (скобки можно и не ставить, но лучше это делать).
Например (см. сегмент организации завершения моделирования и расчета результатов):
ADVANCE ((Normal(2,(S1_#Koef),(S2_#Koef)))/Q_) ; Розыгрыш времени обработки запроса SAVEVALUE VerObr,(N$ObrZap/N$KolZap)) ; Расчет вероятности обработки запросов SAVEVALUE TimeNZap,((AC1-X$AC2)/(X$Prog#Koef1)) ; Расчет среднего времени обработки запросов
Модель в AnyLogic
Постановка задачи
Сервер обрабатывает запросы, поступающие с автоматизированных рабочих мест с интервалами, распределенными по показательному закону со средним значением 2 мин. Время обработки сервером одного запроса распределено по экспоненциальному закону со средним значением 3 мин. Сервер имеет входной буфер емкостью 5 запросов.
Построить имитационную модель для определения математического ожидания времени и вероятности обработки запросов.
Как уже отмечалось, сервер представляет собой однофазную систему массового обслуживания разомкнутого типа с ограниченной входной емкостью. Версия 6 AnyLogic при создании подобных простейших моделей предоставляет возможность использования шаблонов моделей. То есть выполнение первых одних и тех же шагов можно перепоручить Мастеру создания модели. Все, что нужно пользователю, это указать, какой метод моделирования будете применять, и выбрать те опции, которые нужны в модели. После этого Мастер автоматически создаст простейшую модель. Далее можно продолжить ее разработку, изменяя свойства объектов модели и добавляя при необходимости другие объекты.
Поскольку мы только приступаем к разработке моделей в AnyLogic, то воспользуемся шаблоном. В дальнейшем, при изменении и дополнении модели согласно постановке задачи, вам станет понятно, как начинать разработку не только простейшей, но и более сложной модели "с нуля".
Создание диаграммы процесса
- Выполните Файл/Создать/Модель
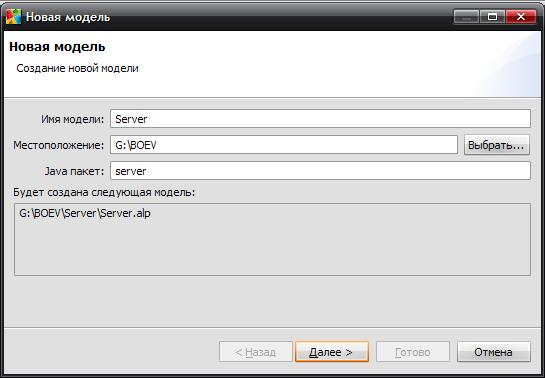
 на панели инструментов. Появится диалоговое окно Новая модель (Рис. 1.11).
на панели инструментов. Появится диалоговое окно Новая модель (Рис. 1.11).
- Задайте имя новой модели. В поле Имя модели введите Server.
- Выберите каталог, в котором будут сохранены файлы модели. Если хотите сменить предложенный по умолчанию каталог на какой-то другой, то можете ввести путь к нему в поле Местоположение или выбрать этот каталог с помощью диалога навигации по файловой системе, открывающегося нажатием кнопки Выбрать.
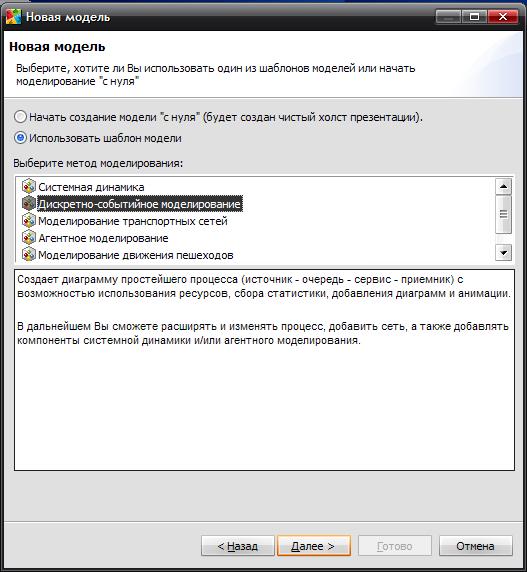
- Щелкните кнопку Далее. Откроется вторая страница Мастера создания модели (Рис. 1.12).
- Здесь будет предложено выбрать шаблон, на базе которого будете разрабатывать модель. Поскольку мы хотим создать новую дискретно-событийную модель не "с нуля", установите флажок Использовать шаблон модели и выберите Дискретно-событийное моделирование в расположенном ниже списке.
- Щелкните кнопку Далее. На следующей странице Мастера будет предложено выбрать: хотите ли вы сразу же добавить в создаваемую модель ресурсы, график, отображающий длину очереди к сервису, анимацию обслуживающихся и ожидающих обслуживания заявок или гистограмму, отображающую распределение времени пребывания заявок в моделируемой системе. Поскольку мы хотим лишь создать с помощью Мастера простейшую диаграмму процесса, а остальные шаги выполнять совместно по шагам, чтобы вы знали, как добавлять ресурсы, создавать анимацию модели и собирать статистику и могли в дальнейшем делать это самостоятельно, то не выбирайте никаких опций модели, оставьте Анимация Нет и закончите создание модели, щелкнув мышью кнопку Готово.
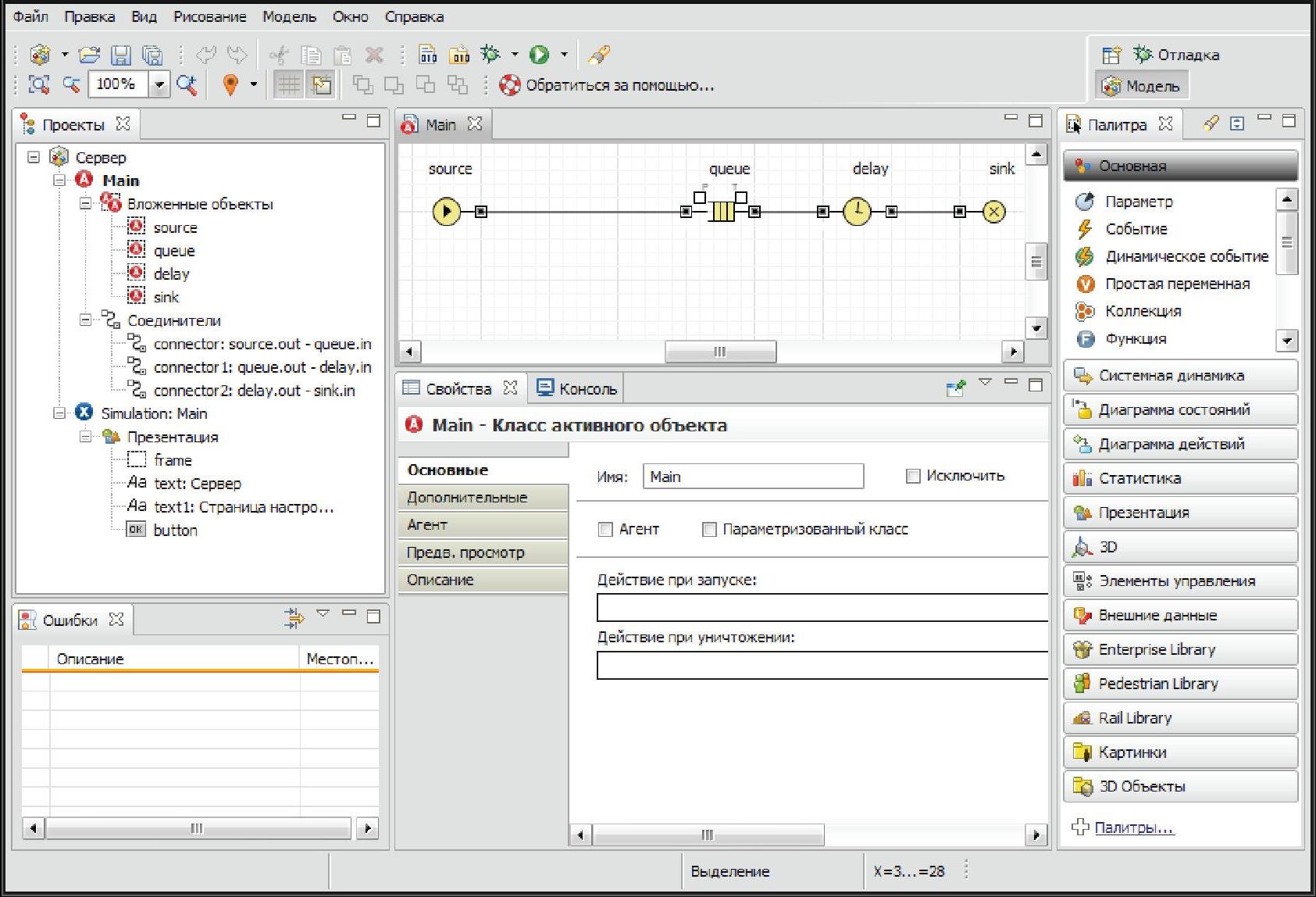
- Вы создали новую модель. Далее познакомимся с пользовательским интерфейсом AnyLogic (Рис. 1.13).
- В левой части рабочей области находится панель Проект. Панель Проект обеспечивает навигацию по элементам моделей, открытых в текущий момент времени. Поскольку модель организована иерархически, то она отображается в виде дерева. Сама модель образует верхний уровень дерева. Эксперименты, классы активных объектов и Java классы образуют следующий уровень. Элементы, входящие в состав активных объектов, вложены в соответствующую подветвь дерева класса активного объекта и т. д.
- В правой рабочей области будет отображаться панель Палитра, а внизу в средней части интерфейса - панель Свойства. Панель Палитра содержит разделенные по категориям элементы, которые могут быть добавлены на диаграмму класса активного объекта или эксперимента. Панель Свойства используется для просмотра и изменения свойств выбранного в данный момент элемента (или элементов) модели.
- В центре рабочей области AnyLogic находится графический редактор диаграммы класса активного объекта Main.
- В левой нижней части расположена панель Ошибки. Она отображает ошибки в модели и помогает их локализовать.
Замечание. При работе с моделью не забывайте сохранять производимые Вами изменения с помощью нажатия кнопки панели инструментов Сохранить.
Изменение свойств блоков модели, её настройка и запуск
Помним, что мы хотим сначала создать простейшую модель, в которой будем рассматривать только обработку запросов сервером.
В основе каждой дискретно-событийной модели лежит диаграмма процесса - последовательность соединенных между собой блоков (в AnyLogic это блоки библиотеки Enterprise Library), задающих последовательность операций, которые будут производиться над проходящими по диаграмме процесса заявками.
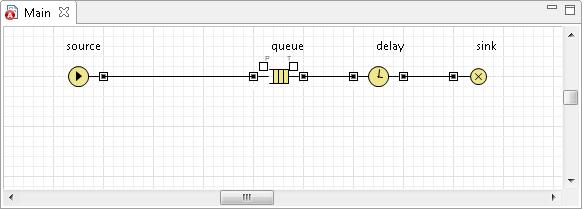
Обратите внимание на диаграмму класса Main. Вы увидите, что диаграмма нашего простейшего процесса (Рис. 1.14) была автоматически создана Мастером создания модели, поскольку такая модель является ничем иным, как простейшей системой массового обслуживания, наиболее часто используемой в качестве отправной точки создания дискретно-событийных моделей. Поэтому она и выбрана в качестве базового шаблона при разработке дискретно-событийных моделей.
Диаграмма процесса в AnyLogic создается путем добавления объектов библиотеки из палитры на диаграмму класса активного объекта, соединения их портов и изменения значений свойств блоков в соответствии с требованиями модели.
Всё, что нам нужно, чтобы сделать созданный шаблон модели адекватным постановке задачи - это изменить некоторые свойства объектов.