Опубликован: 24.04.2015 | Доступ: свободный | Студентов: 149 / 0 | Длительность: 04:57:00
Специальности: Менеджер, Математик, Преподаватель, Физик
Лекция 5:
Инструменты Gnumeric для статистиков
Ключевые слова: меню, статистика, ПО, значение, стандартное отклонение, генерация случайных чисел, дистрибутив, вывод, диапазон, диапазон ячеек, интервал, лист, выборка, место, операции, сглаживание, вектор, N/A, график, графика, анализ, коэффициент корреляции, случайная величина, параметр, вычисление, значимость, прямой, пересечение, модуль, инверсия, обратное преобразование, путь, дисперсия, энергия, Гистограмма, таблица, формат вывода, процентили, ранг, процент, деление, список, группа, объём
Инструменты статистической обработки данных находятся в пункте главного меню "Статистика" (рис. 5.1). В этой главе рассмотрим принципы работы большинства из них, поскольку от версии к версии добавляются новые инструменты и возможности.
5.1 Описательные статистики
Исследование возможностей Gnumeric по статистической обработке данных начнем с простейшей задачи – получения основных статистических характеристик выборки. В качестве исходных данных будем использовать диапазоны ячеек, заполненные последовательностью случайных чисел. Примеры данных здесь приводить не имеет смысла, поэтому будет описываться вид исходного модельного распределения и его параметры, а на рисунках будут приводиться диалоги формирования исходных данных и результаты.

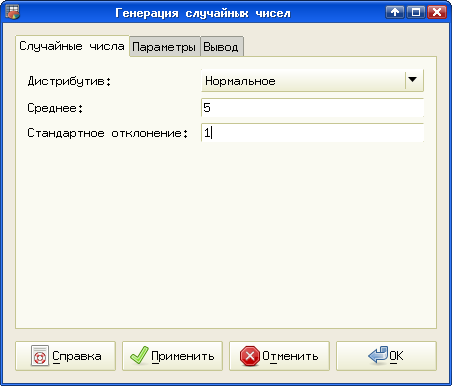
Для начала сформируем выборку с нормальным распределением, задав среднее значение 5 и стандартное отклонение 1. Это делается в помощью диалога "Генерация случайных чисел" (рис. 5.2), вызываемого из главного меню ("Правка/Заполнить/Генерация случайных чисел..." или "Данные/Заполнить/Генерация случайных чисел...").
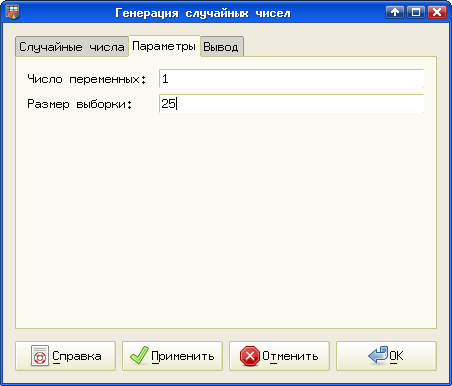
На вкладке "Случайные числа" устанавливаем вид распределения (здесь названный "Дистрибутив") – Нормальное, Среднее значение – 5 и Стандартное отклонение – 1. На вкладке "Параметры" устанавливаем Число переменных – 1 и Размер выборки – 25 (рис. 5.3).
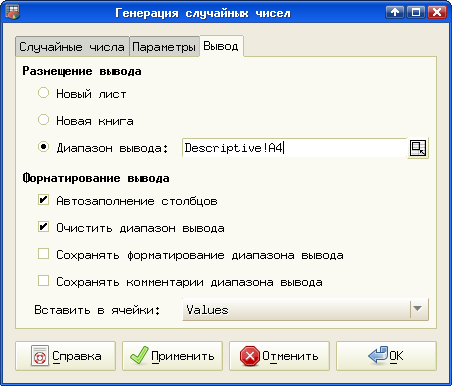
Наконец, на вкладке "Вывод" устанавливаем диапазон вывода – диапазон ячеек, начиная, например, с A4 на текущем листе (рис. 5.4). После нажатия на кнопки "Применить" и "ОК" будет получено 25 случайных чисел с заданным законом распределения.
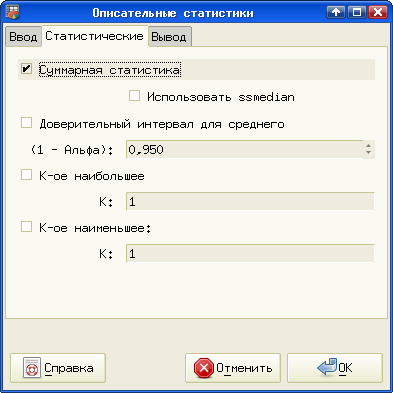
Теперь получим базовые статистические характеристики этой выборки как будто мы про неё ничего не знаем. Для этого выделим наши данные и вызовем диалог "Описательные статистики" ("Статистика/Описательные статистики/Описательные статистики...") (рис. 5.5).
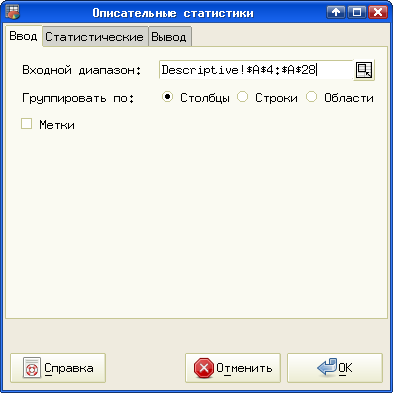
На вкладке "Ввод" проверяем правильность диапазона ввода, на вкладке "Статистические" при необходимости уточняем доверительный интервал и другие параметры (можно все оставить по умолчанию, как на рис. 5.6). Наконец, на вкладке "Вывод" опять-таки задаем ячейку текущего листа, с которой начнется вывод результатов (рис. 5.7).
Очевидно, что раз 25 точек данных начинаются с A4, то имеет смысл выводить результаты статистического анализа после окончания данных. Хотя ничто не мешает вывести результаты на отдельный лист, это не очень удобно, если приходится сравнивать характеристики нескольких выборок.
В дальнейшем без особой необходимости все эти однотипные диалоги приводиться не будут. Теперь посмотрим на результаты обработки исходных данных – те самые описательные статистики для нормального распределения (рис. 5.8).
Из приведённых результатов видно, что сгенерированы были действительно случайные числа. Вычисленные по выборке значения близки к параметрам, по которым формировалась эта выборка, но совпадение не идеальное, т.е. фактор "случайности" действительно имеет место. Отсутствие значения для моды, вероятно, связано с тем, что исходная выборка воспринимается как вариативный ряд, в котором нет варианты с максимальной частотой, поскольку значения не повторяются.
Теперь проделаем те же операции для однородного распределения в диапазоне ![[-2;2]](/sites/default/files/tex_cache/615951c7c4b124cb26541f3feb881b2b.png) и посмотрим на результаты (рис. 5.9).
и посмотрим на результаты (рис. 5.9).
Здесь стандартное отклонение очень велико по сравнению с диапазоном от минимума до максимума, что неудивительно для однородного распределения.
Таким образом, инструмент "Описательные статистики" позволяет получить практически все необходимые статистические характеристики имеющейся выборки.