

|
Сайт dreamspark пишет что код истек :( |
Опубликован: 28.01.2014 | Доступ: свободный | Студентов: 2289 / 277 | Длительность: 14:33:00
Лекция 7:
Бизнес-аналитика и анализ данных с SQL Reporting и Hadoop
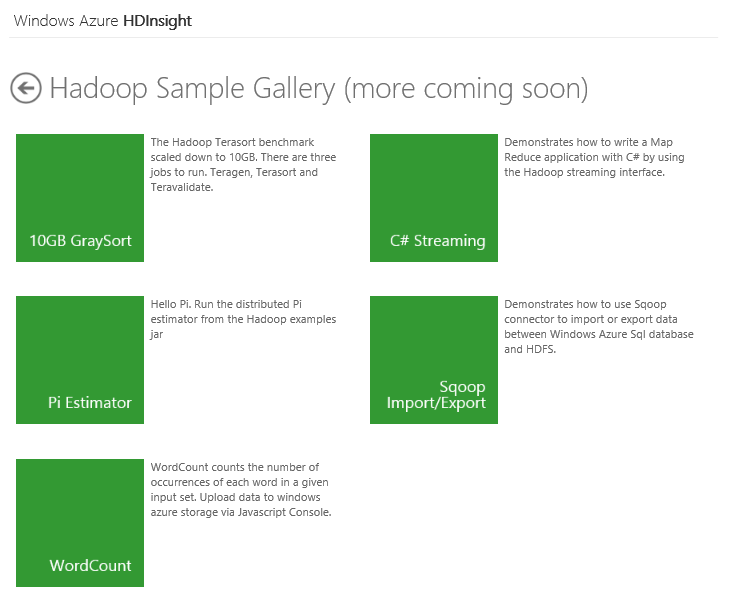
Создадим задачу Map/Reduce из тестового набора. Для этого нажмем кнопку Samples.
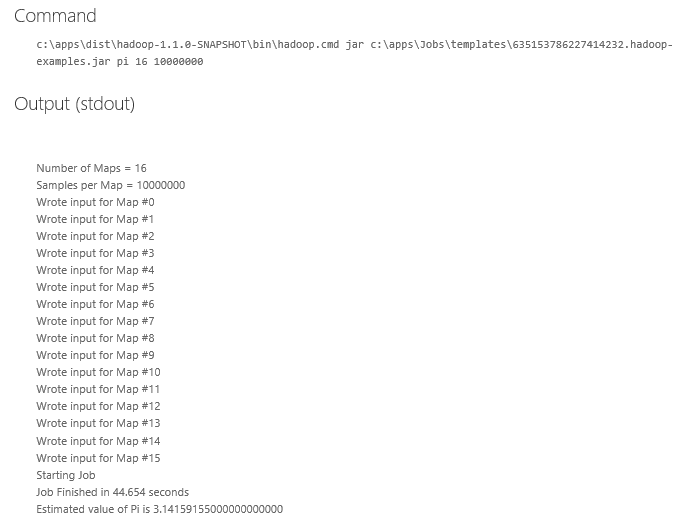
Нажмем кнопку Pi Estimator. На странице тестовой задачи нажмем Deploy to your cluster. Это приведет к странице, которую можно также вызвать, нажав кнопку Create Job. Будет открыта страница добавления новой задачи, на которой необходимо ввести название задачи, указать JAR-файл задачи и настроить параметры (если таковые есть). В случае тестовой задачи эти данные заполняются автоматически.
Задача, которую мы запустим, инициирует расчет числа Пи, исходя из 16 Maps (первый параметр в команде) и 10 млн. сэмплов на каждый Map (второй параметр).
Нажмем Execute Job и дождемся выполнения задачи. После окончания выполнения будут выведены результаты и служебная информация о задаче.
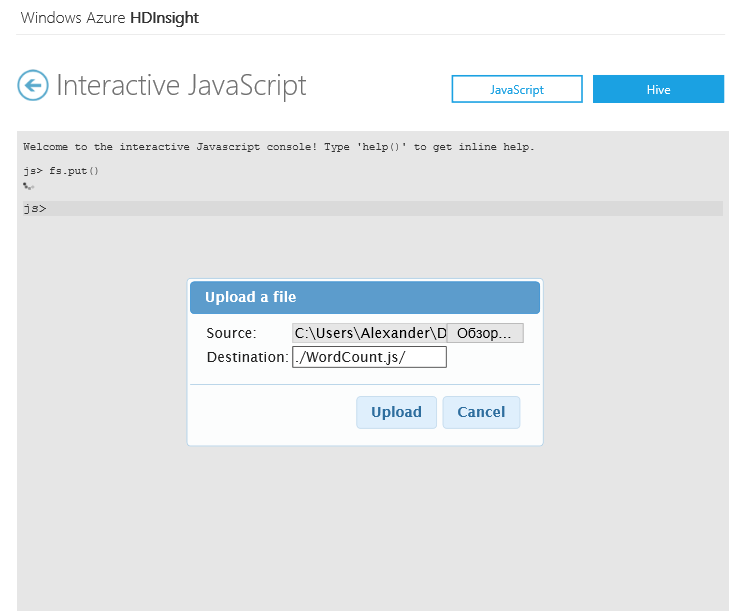
Воспользуемся интерактивной консолью для расчета скрипта на Javascript (Map/Reduce). В качестве примера возьмем тестовую задачу по подсчету слов. Для этого загрузим скрипт WordCount.js и текстовый файл davinci.txt, зайдя на страницу Samples и нажав на кнопку WordCount.
Вернемся на главную страницу панели управления кластером и нажмем на кнопку Interactive Console. Обратите внимание, что ту же задачу можно выполнить, нажав Deploy to your cluster.
Введем в интерактивную консоль команду fs.put() для загрузки файла WordCount.js. Выберем загруженный локально файл. Значение Destination укажем равным ./WordCount.js/. Повторим процедуру для загрузки файла davinci.txt. Значение Destination для davinci.txt укажем равным ./example/data/.
Выполним команду, указанную ниже, и, после выполнения задачи, нажмем View Log для просмотра информации о задаче.
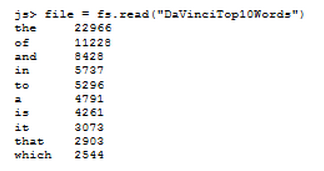
pig.from("/example/data/davinci.txt").mapReduce("WordCount.js",
"word, count:long").orderBy("count DESC").take(10).to("DaVinciTop10Words")
Увидеть результаты мы можем, введя команду fs.read("DaVinciTop10Words").
Подробнее про разработку приложений для HDInsight рассказано в блоге на MSDN: http://blogs.msdn.com/b/benjguin/archive/2012/02/09/analyzing-1-tb-of-iis-logs-with-hadoop-map-reduce-on-azure-with-javascript-analyse-d-1-to-de-journaux-iis-avec-hadoop-map-reduce-en-javascript.aspx
Заключение
С появлением тенденции быстрого увеличения количества данных, существующей в сегодняшнем мире, и распространением термина Big Data (Большие данные), локальные центры, которые часто не могут покрыть потребности в обработке все возрастающих массивов данных, могут быть как заменены, так и дополнены (в зависимости от сценариев) ресурсами, хранящимися в облаке, для того, чтобы оптимизировать затраты и увеличить эффективность производства.