
|
Сайт dreamspark пишет что код истек :( |
Опубликован: 28.01.2014 | Доступ: свободный | Студентов: 2289 / 277 | Длительность: 14:33:00
Лекция 7:
Бизнес-аналитика и анализ данных с SQL Reporting и Hadoop
Анализ данных с Hadoop
Сервис Windows Azure HDInsight (Hadoop) — это облачный сервис, предлагающий экосистему и создание кластеров Hadoop по запросу пользователя. С помощью портала Windows Azure могут быть созданы и развернуты кластеры Hadoop размером до 32 узлов (необходимо уточнить, что на момент написания сервис Windows Azure HDInsight находится в закрытой Preview-версии). Кроме создания задач MapReduce, разработчик имеет доступ к интерактивной консоли, которая позволяет писать запросы к данным на JavaScript и Hive.
MapReduce – это параллельное и распределённое решение, разработанное корпорацией Google для обработки больших массивов данных и активно использующееся в таких сферах, как, например, поисковые движки. MapReduce, или M/R, состоит из двух функций-компонентов – Map и Reduce. Первая функция, Map, используется для вычисления наборов ключ-значение. Reduce – функция, получающая результаты вычисления функции Map и применяющая к ним другую функцию. В подходе M/R подразумевается, что между данными нет прям зависимостей, что упрощает процесс параллелизации. Узел-мастер распределяет задачи M/R по обработчикам Map и Reduce, собирая информацию. Все пары ключ-значение с идентичным значением ключа отправляются на обработку на один обработчик.
Типичным примером использования MapReduce, а значит, и Hadoop, является анализ файлов логов. Для файлов логов обычна ситуация разрастания до очень больших размеров, при этом все файлы соблюдают строгий синтаксис данных, что позволяет применять логику обработки к этим файлам. Несмотря на простоту, однако, обработки, если файлы логов содержат очень большое количество записей, их обработка на одном компьютере может занять долгое время.
С помощью MapReduce можно разделять большие файлы логов на части. Функция Map ищет уникальные вхождения записей (например, Web-страниц). Каждый раз, когда Web-страница находится в файле, в функцию Reduce поступает ключ-значение,где ключ – Web-страница, а значение – 1. Обработчики функции Reduce агрегируют количество для каждой из Web-страниц, и в результате пользователь получает общее количество входов для каждой из Web-страниц.
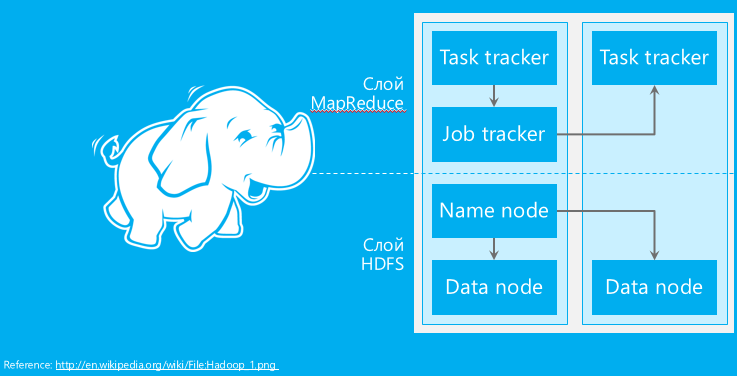
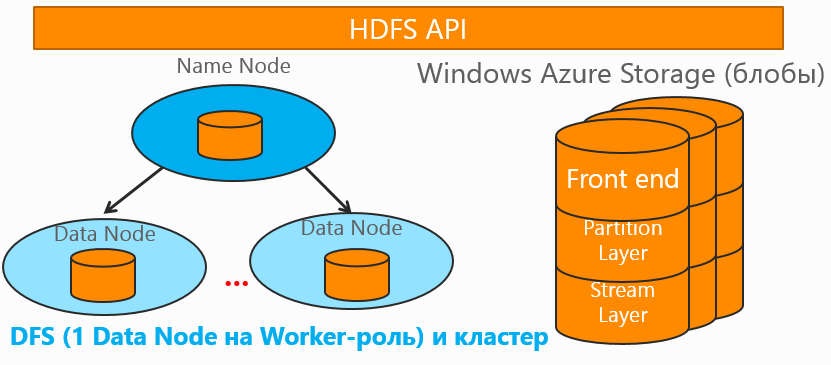
Сервис основан на распределенной файловой системе HDFS (Hadoop Distributed File System), реализованной на кластере узлов Hadoop двух видов – Data Node и Name Node. Подобный кластер может быть как гомогенной структуры (с унифицированными характеристиками узлов), так и гетерогенной (большим количеством узлов разных характеристик). Name Nodes содержат информацию о том, на каком из узлов данных (Data Node) содержится конкретная реплика (реплики используются для обеспечения высокой надежности и избыточности), и представляют клиенту эту информацию. При выходе из строя реплики фрагмента одна из его вторичных реплик назначается основной. Масштабируемость на достигается за счет параллельной обработки задач. Task Tracker называются узлы, хранящие входные фрагменты задач (файлов) и запускающие экземпляры выполнения Map/Redurce, координирует же эти экземпляры выполнения узел, носящий название Job Tracker. В различных реальных задачах экосистема Hadoop/HDInsight состоит из гораздо большего количества компонентов и модулей интеграции с другим программным обеспечением и форматами данных.
Данные, используемые HDInsight в задачах, хранятся в Windows Azure Storage в блобах и получаются для обработки по парадигме MapReduce узлом-мастером, который затем распределяет задачи согласно заданной логике по обработчикам. По этой причине для работоспособности кластера необходимо создать и настроить аккаунт хранилища Windows Azure и создать кластер максимально близко к географическому расположению хранилища (для избежания увеличения латентности).
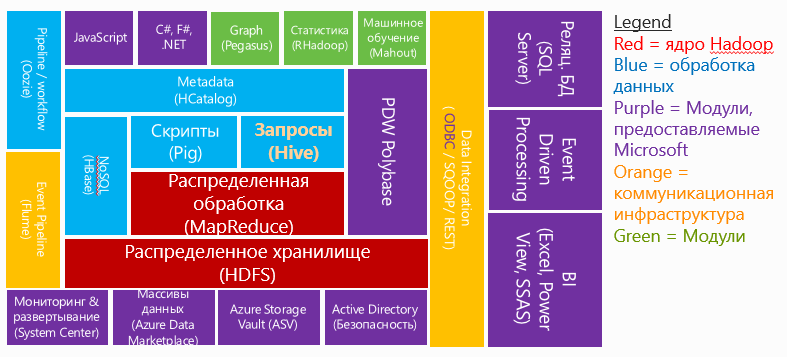
Экосистема HDInsight
Как уже было сказано ранее, сервис HDInsight предоставляет облачный сервис по управлению большими данными. HDInsight имеет собственные реализации Hive и Pig, которые используются для обработки данных и хранения соответственно, а также способен интегрироваться с существующими мощными средствами BI, разработанными Microsoft: SQL Server Analysis Services, Reporting Services, PowerPivot, Excel.
Говоря о том, что представляет собой Pig, необходимо уточнить, что Pig – это высокоуровневая платформа, которая обеспечивает возможность обработки больших данных в кластерах Hadoop. Pig состоит из специального языка запросов Pig Latin, которые выполняются к массивам данных в консоли, и способен интегрироваться User Defined Functions (UDF) на Java, Python, C# и JavaScript.
Hive является распределенным сервисом хранения данных "над" HDFS, и предоставляет интерфейс для взаимодействия с данными с помощью SQL запросов на языке HiveQL (поддиалекте SQL) и реляционной модели. Аналогично Pig, Hive трансформирует запрос на собственном языке в задачи Map/Reduce
Функциональность HDInsight гарантирует также то, что разработчик может использовать уже привычные ему средства, такие как, например, Powershell, .NET, Java, F#, Javascript и Node.js, для разработки, управления и мониторинга происходящего на кластере. Также HDInsight может быть установлен в его локальной версии на серверный продукт Microsoft Windows Server.