Стратегии каталогов
8.4 Служба унифицированных каталогов
Многие организации со множеством каталогов сталкиваются с проблемами, связанными с администрированием данных. С целью уменьшения суммарного количества каталогов, которые необходимо администрировать, управлять ими и поддерживать, каталоги надо объединять и исключать те из них, которые являются избыточными. Чтобы выполнить это, как правило, необходимо переместить данные из одного каталога в другой. Хотя вероятность того, что большинство коммерческих организаций будут способны объединиться в единственный каталог, чрезвычайно мала, результатом объединения только двух каталогов может стать значительное снижение себестоимости работы.
Мы определяем службу унифицированных каталогов (unified directory service) как стратегию управления данными объединенных каталогов. Как правило, она базируется либо вокруг центрального, основного каталога, либо вокруг централизованно управляемого метакаталога, используемого для синхронизации каталогов либо их обоих вместе. Метакаталог (metadirectory) не является традиционным пользовательским каталогом; скорее он хранит информацию о том, где расположены данные, как к ним можно осуществить доступ и как протекают данные между различными каталогами. Так как он хранит только данные о данных, "метакаталог" является репозиторием этих "метаданных".
Основываясь на опыте работы компании IBM с другими заказчиками, существует несколько фундаментальных, наилучших методов организации работ по определению стратегии при наличии множества корпоративных каталогов. Мы обсудили их в этой лекции ранее, а теперь покажем последовательность высокоуровневых шагов, необходимых для формулирования стратегии службы каталогов.
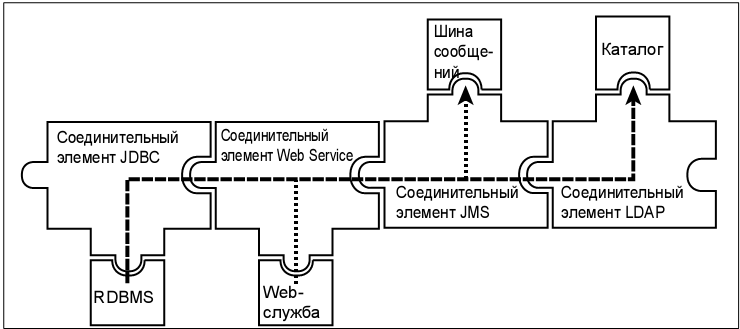
увеличить изображение
Рис. 8.11. Пример потока Directory Integrator при использовании соединительного элемента Web service
Идентификация авторитетных источников
Сохраненная в записи каталога пользователя информация организована посредством дискретных атрибутов или полей. Границы информации, сохраненной в каталоге, зачастую установлены требованиями приложения или набора приложений. Авторитетный источник определяется как наивысший организационный орган, который создает, генерирует или проверяет достоверность значений атрибутов данных. Проверка достоверности данных может происходить либо при первоначальном вхождении данных, либо в любое время, когда данные обновляются или сохраняются. Каждый атрибут может подвергаться проверке достоверности или генерироваться различными подсистемами организации.
Примером авторитетного источника может служить каталог служащих кадрового органа, где генерируется уникальный идентификатор ( ID ) служащего.
Идентификация уникальных ключей
Уникальные ключи (unique keys) являются уникальными идентифицирующими атрибутами для каждого человека, компьютера или другого ресурса. Чтобы быть ключом, атрибут должен быть универсально-используемым и универсально-уникальным. Если не применяется одиночный уникальный ключ, то для формирования уникального ключа может использоваться комбинация атрибутов. Заметьте, то, что выглядит как идеальный уникальный ключ, на самом деле может иметь ограничения. Например, SMTP-адрес электронной почты обычно уникален для каждого служащего; однако не все служащие могут иметь электронную почту.
Вторым аспектом идентификации уникальных ключей является определение границ данных, к которым может применяться ключ. Несмотря на то что ID служащего организации может быть уникальным в пределах США, он может быть не представлен или недоступен в других странах. Когда в заданном репозитории доступно множество ключей, они должны быть классифицированы как первичные (primary) и вторичные (secondary) ключи на основе их надежности. Например, первичным ключом может быть ID служащего, вторичным ключом – корпоративный SMTP-адрес электронной почты, а третичным ключом – полное имя пользователя, объединенное с номером телефона и местом работы.
Определение стратегии интеграции
Когда идентифицированы и инвентаризированы существующие источники данных и ключи корреляции, следующий шаг состоит в выборе стратегии объединения (или интеграции) данных. Как упоминалось ранее, в основном существует два типа стратегий интеграции каталогов:
- метакаталог;
- центральный основной каталог.
Для большинства организаций реализация метакаталога является более быстрым и простым решением, чем реализация центрального многоцелевого основного каталога. Важно понимать различие между метакаталогом и центральным основным каталогом.
Метакаталог определяет взаимоотношения и потоки данных между различными существующими каталогами. Типично они имеют соединительные элементы, которые специально разработаны для конкретных каталогов, таких, как Domino, Active Directory, PeopleSoft HRMS и т. д. Соединительные элементы могут использоваться для преобразования данных между различными каталогами, отчасти независимо (например, А в Б, Б в А и В ). Как правило, сами они не используют постоянное хранилище данных, полагаясь на хранилища данных каталогов, к которым они подключаются для создания "виртуального" каталога. Подобный виртуальный каталог может предоставлять службу LDAP, которая осуществляет доступ к данным из множества каталогов в целях получения способности отвечать на запросы LDAP. Однако сам он может ничего не хранить в базе данных. Каждый запрос требует подключения и поиска по отношению к существующим базам данных-источникам, а метакаталог для ответа на исходный запрос LDAP выполняет объеди нение собранных данных "на лету".
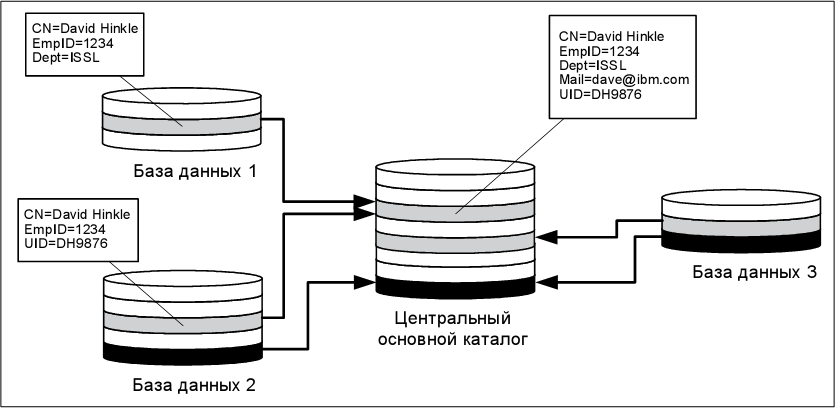
Как показано на рис. 8.12, атрибут Dept изменен в базе данных 3 с применением данных из базы данных 1, а атрибут Mail добавлен в базу данных 2 по информации из базы данных 3. Это простой пример синхронизации данных между различными каталогами, выполняемой метакаталогом.

Центральный каталог принимает данные от различных существующих второстепенных каталогов и может предоставлять объединенные данные обратно различным второстепенным каталогам. Как и метакаталог, он требует наличия соединительных элементов с разнообразными каталогами-"спицами" для чтения и записи данных. В отличие от метакаталога он предусматривает свое собственное хранилище, а преобразование данных всегда определяется исходя из атрибутов, сохраненных в центральном каталоге (например, A в Д, Б в Д, В в Д ). Объединение данных выполняется как часть постоянной синхронизации с каталогами-"спицами", а сохраняются уже объединенные данные.
Как показано на рис. 8.13, центральный основной каталог выполняет функцию группирования всех атрибутов и сохранения их в "основной записи" (master record). Нанесенные стрелки отображают поток данных, идущий от каталогов-источников (базы данных 1, 2 и 3) к центральному основному каталогу. Обратите внимание на то, что атрибуты CN и EmpID используются в качестве ключей корреляции для данных, предоставляемых из баз данных 1 и 2. Это типичный сценарий, когда основной каталог группирует "подачи" от всех других второстепенных каталогов (каталогов"спиц"). Хотя это и не отображено на схеме, обратите внимание на то, что существует также возможность помещать атрибуты, которые сохранены в центральном основном каталоге и пришли от одного второстепенного каталога, из основного каталога в другой второстепенный каталог. Для этой архитектуры типично, что между второстепенными каталогами совместно используется ограниченное количество атрибутов. При изменении атрибутов во второстепенных каталогах чрезвычайно важно отслеживать авторитетный источник для каждого из атрибутов. Центральный каталог, как правило, не строго осуществляет эти изменения в авторитетных источниках. Как результат, надо быть внимательным при разрешении приема идентичного атрибута (отличного от ключей корреляции) из второстепенных каталогов.
Метакаталоги имеют преимущество, состоящее в объединении данных в реальном времени в дополнение к синхронизации каталогов, но с этой способностью приходит и риск, связанный с производительностью службы. Так как доступ к различным каталогам-источникам осуществляется с использованием сетевых соединений, то выборка данных посредством соединительных элементов настолько быстра и надежна, насколько быстра и надежна лежащая в основе инфраструктура.
Центральные каталоги имеют преимущество, состоящее в способности немедленно предоставлять объединенные данные. Однако частота синхронизации с каталогами"спицами" (источниками) может ограничивать точность предоставленных данных. Такие каталоги могут также требовать серьезного сервера и ресурсов для хранения данных.
Альтернативным подходом является комбинация двух стратегий. Комбинированный подход, как показано на рис. 8.14, использует метакаталог для выполнения гибкого объединения данных из различных каталогов-источников, а также центральный каталог-хранилище как долговременное хранилище объединенных данных для использования приложениями, требующими службы каталогов. При этом гибридном подходе центральный каталог является приемником данных и обычно не позволяет производить прямые изменения, но представляется как нечто большее, чем служба LDAP с ее возможностями только чтения. Единственной областью, когда может быть необходимо разрешение на прямые изменения, вероятно, будут случаи изменения паролей пользователей, так как они не могут быть синхронизированы (дополнительную информацию относительно проблем с паролями и их синхронизацией см. в разделе "Синхронизация паролей"). При наличии каталога LDAP, который содержит объединенные данные, можно избежать проблем с запаздывани ем данных, вызываемых виртуальным динамическим объединением данных.
Этот подход идеален для организации, которая желает переместить данные и приложения для использования общего каталога LDAP наряду с продолжением поддержки приложений, являющихся зависимыми от частных или унаследованных каталогов.
В этом примере наш основной каталог LDAP содержит все сгруппированные атрибуты. Данный пример также иллюстрирует, как применялась синхронизация каталогов между базой данных 3 и нашим основным каталогом LDAP. В этом случае база данных 3 представляет каталог Domino и в целях использования каталога LDAP для управления доступом к Domino мы синхронизировали иерархическое имя Notes с основным каталогом LDAP. Также настало время указать, что синхронизация на рис. 8.14 может быть выполнена при использовании трех сборочных конвейеров, сконфигурированных в интеграторе каталогов IBM Tivoli Directory Integrator, а основной каталог LDAP может быть реализован с помощью IBM Directory Server.
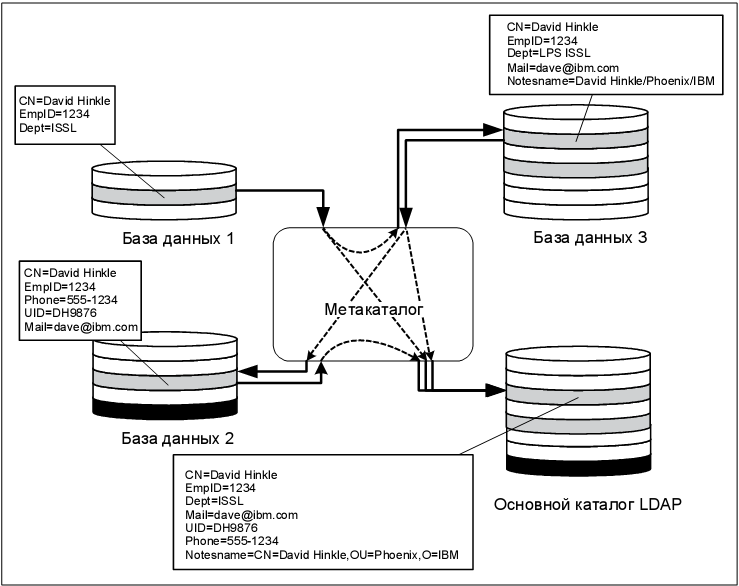
увеличить изображение
Рис. 8.14. Комбинированная архитектура метакаталога с основным каталогом-хранилищем LDAP
Определение схемы
Схема каталога имеет три главных компонента. Ими являются:
- Классы объектов ( object classes ): имеют отношение к типу сохраняемого объекта. Объект может использовать множество классов объектов при обеспечении того, что классы не являются взаимно исключающими. Мы обсудили этот тип компонента более подробно в разделе 8.3.2, "Классы объектов".
- Атрибуты ( attributes ): это "поля" записи данных для объекта. Например, объект OrganizationPerson может иметь значение атрибута Title. В этом случае атрибут Title является необязательным. Атрибуты могут также быть обязательными для заданного класса объектов, например, объект Person должен иметь значения атрибутов CN [common name (общее имя)] и SN [surname (фамилия)]. Мы обсудили этот тип компонента более подробно в разделе 8.3.3, "Атрибуты".
- Дерево информации каталога [Directory Information Tree ( DIT )]: данные каталога LDAP используют организационную структуру иерархического дерева. Как и в любой иерархии, существует как минимум один корень с возможностью наличия множества ветвей ( branches ) с листьями ( leaves ), известными также как конечные узлы (b). Каждый узел в дереве, сам корень, точки ветвления и листья, является отличительным именем ( Distinguished Name, DN ). Начиная от корня, вы определяете ветви дерева, которые являются либо контейнерами (например, CN=users ), либо организационными подразделениями ( OU= ). Обратите внимание на то, что отдельный каталог LDAP может иметь множество корней с различными списками доступа и структурами дерева под ними. Реальная осуществимость этого зависит от масштабируемости каталога LDAP. В целях поддержания администрирования настолько простым, насколько это возможно, отдельный корень обычно используется для всех объектов пользовател я.
Хотя DIT технически и не является частью "схемы", структура иерархического дерева имеет прямое отношение к каждому отличительному имени ( DN ) объекта. DN является полностью уточненным иерархическим именем. Напримеру, DN может быть "CN=john q public,OU=sales,O=acme,C=us" или другой типичной формой "UID=jsmith4 ,CN=users,DC=acme,DC=com". В первом примере дерево следует более традиционной структуре X.500, со страной "C=US" в качестве корня. Второй пример отображает корень, который следует соглашениям по именованию DNS с доменными компонентами "DC=acme, DC=com" в качестве корня. Отличительные имена должны быть уникальными, поэтому "плоские" деревья предписывают использование уникальных идентификаторов, таких, как во втором примере, когда вместо DN (общего имени) используется идентификатор пользователя UID (User ID). Как правило, наш опыт говорит о том, что плоские деревья, несмотря на связанные с необходимостью наличия методов генерирования уникальных идентификаторов или имен накладные расходы, в конечном счете более просты в администрировании. Но в больших организациях (более 10 000 пользователей) присутствует компромисс в этом плане. Структура плоского дерева в большой организации требует наличия неинтуитивной схемы именования пользователей, которая зачастую вынуждает употреблять дополнительные идентификационные атрибуты. Например, рассмотрим существование двух уникальных пользователей:
DN= uid=bhinkle,cn=users,dc=acme,dc=com cn=Brendan C Hinkle mail=b_c_hinkle@acme.com DN= uid=bhinkle2,cn=users,dc=acme,dc=com cn=Bill Hinkle mail=b_hinkle@acme.com
Обратите внимание на то, что из элементов примера трудно или даже невозможно определить, какого пользователя мы намереваемся выбрать на основе DN. Нашим приложениям, таким, как электронная почта, необходимо нести дополнительные непроизводительные издержки по выборке атрибутов для элемента в дополнение к DN, чтобы пользователь или приложение смогли установить соответствующий элемент. В приведенном примере общее имя может позволить нам отличить человека, которого мы хотим выбрать. Но в больших организациях с большой долей вероятности будут существовать идентичные или подобные общие имена. Таким образом, далее, возможно, будет необходимо также запрашивать другой атрибут, такой, как департамент или место работы. Значит, если мы пересмотрим дерево с целью сделать его "более высоким" (или менее "плоским"), мы легко сможем создать отличительные имена, которые предоставляют более гранулированную информацию об элементах без необходимости доступа к дополнительным атрибутам:
DN= uid=bhinkle,ou=sales,dc=acme,dc=com mail=b_c_hinkle@acme.com DN= uid=bhinkle2,ou=hr,dc=acme,dc=com mail=b_hinkle@acme.com
Использование ветви OU либо ветви DC под корнем обычно рекомендуется в меньших организациях (до 10 000 элементов) только в тех случаях, если администрирование пользователей распределено. Так рекомендуется, потому что элементы управления доступом проще реализовать на уровне узла ветви, чем на уровне каждого индивидуального листового (пользовательского) узла. Какой корень лучше – традиционный корень страны X.500 или корень компонента домена DNS, – является предметом спора. Учитывая, что интернациональная служба X.500 никогда не рассматривалась на предмет общего соединения корней стран унифицированным образом, доменная структура стала более популярным подходом. Теоретически использование компонентов домена DNS может в конечном счете поддерживать способность к получению чьих-либо открытых сертификатов X.500 для отправки зашифрованных SMIME-сообщений. Но мы чувствуем, что этого не случится в реальности на протяжении еще как минимум 3–5 лет, если случится вообще. Наш опыт свидетельству ет о том, что коммерческие организации вряд ли когда-либо предоставят свободно доступную службу каталогов для своих внутренних пользователей. Беспокойства по поводу неправильного применения, такого, как почтовый "спам", несомненно, в этом случае оправданны. Но при повсеместности распространения DNS как наиболее пригодный вариант мы можем рекомендовать использование DIT компонентов домена для тех организаций, которые рассматривают вопрос новой реализации LDAP.
Определение DIT требует большого объема планирования. Обычно в этом случае присутствует компромисс между гранулированной организацией и простотой администрирования. Очень часто трудно уже когда-нибудь осуществить замену и наполнение каталога. DIT, которое кажется хорошо подходящим для одной организации, может быть полностью неподходящим для другой организации, даже если обе они работают в одной и той же отрасли экономики.
Ключевые элементы при рассмотрении вопроса проектирования вашего DIT должны включать:
- размер организации и уникальную схему именования;
- административную структуру данных (централизованная или распределенная);
- разнообразие географических и функциональных подразделений организации;
- возможности каталога (такие, как количество листовых элементов под отдельным узлом);
- частоту изменения любого из этих элементов.
Итак, что же можно сказать насчет ваших уже существующих каталогов, которые не являются каталогами LDAP? Помните о том, что очень немногие LDAP-каталоги основаны на X.500 или Open LDAP. Несмотря на то что важно быть способными к определению схемы в стандартных показателях LDAP, еще более важно определить схему в показателях, специфичных для заданного каталога. Хотя LDAP предусматривает стандартные классы объектов и имена полей атрибутов, большинство LDAP-каталогов применяют различные внутренние имена полей для атрибутов данных пользователей. Некоторые программные продукты разрешают преобразование своих собственных атрибутов в атрибуты LDAP с целью настройки, в то время как в других преобразование невозможно. При первых попытках установить связь собственного атрибута с его именем поля атрибута LDAP имена атрибутов LDAP становятся универсальным языком, с которым могут проводить сравнение все каталоги.
Несмотря на то что создание основной таблицы преобразования атрибутов для нескольких каталогов может быть трудоемким по времени, этот шаг является необходимым условием для проведения любой работы по автоматической синхронизации данных и объединению каталогов.
Для тех организаций, которые только начали формулировать корпоративную стратегию каталогов, мы предлагаем прочесть некоторые из работ, выполненных образовательным сообществом как часть проектов каталогов комитета Middleware Architecture Committee for Education (MACE). Этот материал доступен по адресу:
http://middleware.internet2.edu/dir/
Только имейте в виду, что образовательное сообщество как единое целое производит впечатление наличия значительно более общих требований к каталогам, чем те, которые имеют коммерческие организации. По своей природе коммерческие организации процветают при проведении четких различий между собой и своими конкурентами. По этой причине мы не видим заслуживающих внимания полных энтузиазма попыток со стороны широких масс построить общие службы каталогов в интересах коммерческого сообщества.
За отличной, полной дополнительной информацией относительно корпоративной стратегии каталогов, ее планирования и разработки обратитесь к следующему источнику:
Charles Carrington (Editor), Timothy Speed, Juanita Ellis, and Steffano Korper, Enterprise Directory and Security Implementation Guide: Designing and Implementing Directories in Your Organization.