Лекция 5: Миграция кластера на HACMP V5.3
Сценарий 2: AIX 5.2 и HA 5.1
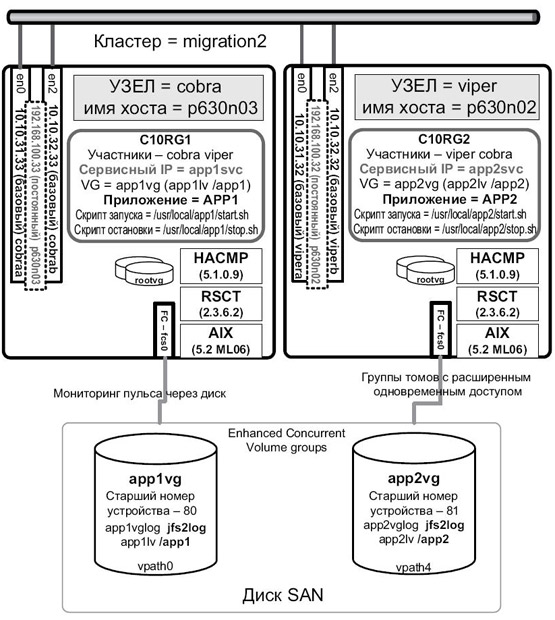
Второй тестовый сценарий представлял собой миграцию двухузлового кластера AIX 5.2 / HA 5.1, настроенного на взаимный перехват ресурсов, на AIX 5.3 / HA 5.3. Мы использовали серверы p630 (7028-6C4) в конфигурации кластера. На рис. 5.3 представлена схема используемой конфигурации.
Топология была настроена на использование стандартных IP-синонимов. На каждом узле были сконфигурированы постоянные IP-адреса в той же подсети, в которой находятся и сервисные адреса. Хранилище содержало ESS LUN (2105-800) с подключением к коммутатору, а также скрипт подключения хоста (ibm2105.rte) и драйвер SDD. Каждый узел был настроен на использование собственных групп ресурсов, каждая из которых включает свою группу томов, сервисный IP-адрес и сервер приложения. Группы томов были сконфигурированы как группы томов с расширенным одновременным доступом, чтобы установить сеть пульса через диски, отличную от IP.
Циклическая миграция: сценарий 2
Мы протестировали стабильность кластера и выполнение перемещения при сбое, прежде чем перейти к тестам миграции. Первым протестированным нами методом миграции для этого двухузлового кластера была циклическая миграция.
Мы выполнили следующие предварительные действия:
- Сохранение снимка с рабочего кластера (со всеми активными узлами).Внимание! Не сохраняйте снимок в каталог /tmp, так как при установке AIX содержимое каталога /tmp удаляется. Сохраните снимок в другой каталог или на другой сервер. Не забудьте также сохранить скрипты приложения в надежный каталог.
- Создание резервной копии ( mksysb ).
- Создание alt_disk_install как средства возврата к прежней конфигурации. Это было сделано с целью ускорения повторного тестирования.
Сценарий миграции
Сначала мы решили выполнить обновление узла cobra. Для этого мы выполнили следующие действия:
- Остановка HACMP на узле cobra (постепенная остановка с передачей ресурсов
на резервный узел – graceful with takeover):
- перемещение C10RG1 на узел viper;
- проверка с использованием /usr/es/sbin/cluster/utilities/clRGinfo.
- Инициация миграции AIX 5.3/RSCT с использованием кода NIM вместе с последними исправлениями: smit remove sdd – должно быть выполнено удаление и замена:
- Выполнение smit update_all для загрузки наборов файлов HA 5.3.
- Перезагрузка узла cobra.
- Реинтеграция узла cobra в кластер путем запуска служб кластера. Политика ресурсов была настроена на перемещение при сбое на узел с более высоким приоритетом, вследствие чего группа ресурсов C10RG1 возвратилась на узел cobra.
- Остановка HACMP на узле viper (постепенная остановка с передачей ресурсов на резервный узел – graceful with takeover). Группа ресурсов C10RG2 перемещается на узел cobra.
- Повтор операций установки AIX/RSCT и HACMP на узле viper.
- Перезагрузка узла viper.
- Реинтеграция узла viper в кластер путем запуска служб кластера.
Результаты циклической миграции: сценарий 2
Общее тестирование циклической миграции было успешным. Как и в сценарии 1, миграция AIX представляла самый медленный этап обновления. После ее выполнения мы протестировали перемещение при сбое в кластере и не обнаружили проблем. Реинтеграция последнего узла была успешной, и мы убедились в том, что изменения в ODM соответствовали новой версии HACMP.
В целях тестирования мы решили прервать миграцию, когда узлы были в смешанном режиме. Мы остановили узел cobra, когда на нем выполнялся HACMP 5.3 и он содержал обе группы ресурсов. В это время на узле viper выполнялся процесс установки HACMP 5.3. После перезагрузки узла cobra и перезапуска служб кластера, он подхватил свою группу ресурсов (C10RG1). После этого мы вручную подключили группу ресурсов узла viper:
#smit hacmp > System Management (C-SPOC) > HACMP Resource Group and Application Management (Управление группами ресурсов и приложениями HACMP) > Bring a Resource Group online (Подключение группы ресурсов) > выбор C10RG2 и нажатие Enter.
Группа ресурсов была подключена без каких-либо проблем. После этого мы выполнили обновление AIX и HACMP на втором узле, после чего смогли выполнить успешную интеграцию в кластер без каких-либо проблем. После завершения мы использовали инструмент тестирования кластера (Cluster Test Tool) для запуска различных тестов и не обнаружили каких-либо проблем. Мы снова выполнили тестирование миграции и не обнаружили проблем с функционированием кластера.
Миграция с использованием снимков: сценарий 2
В том же кластере из двух узлов мы проверили работу метода преобразования снимков. Мы использовали образы установки на резервных дисках для возврата к прежней среде, после чего перезапустили службы кластера на обоих узлах, на которых выполнялся HA 5.1. Тестирование содержало следующие действия:
- Остановка HACMP на всех узлах: cobra viper
- Выполнение команды smit remove и деинсталляция всех наборов файлов cluster.* со всех узлов.
- Миграция кода AIX/RSCT с использованием NIM.
- Установка пакетов HACMP с текущими уровнями PTF на всех узлах.
- Перезагрузка всех узлов кластера.
- Копирование файла snapshot.odm, предварительно сохраненного в процессе циклической миграции и имеющего расположение /usr/es/sbin/cluster/utilities/ snapshot.odm.
- Выполнение следующей команды для преобразования снимка: #/usr/es/sbin/ cluster/conversion/clconvert_snapshot -v 5.1 -s snapshot.odm.
- Применение снимка: smit hacmp > Extended Configuration (Расширенное конфигурирование) > Snapshot Configuration (Конфигурирование снимка) > Apply a Cluster Snapshot (Применение снимка кластера) > выбор снимка и нажатие Enter.
- Запуск служб кластера поочередно на каждом узле.
Результаты миграции с использованием снимков: сценарий 2
В целом миграция с использованием снимка также прошла успешно. Преобразование файла снимка заняло несколько секунд, и его применение на обоих узлах также произошло очень быстро. После завершения миграции мы убедились в корректности преобразования разделов HACMP ODM путем проверки версии кластера в объектных классах HACMPcluster и HACMPnode.
Также после завершения миграции мы использовали инструмент тестирования кластера (Cluster Test Tool) для выполнения нескольких тестов. После обновления не было обнаружено каких-либо проблем функционирования кластера.
Мы считаем, что, если ваша среда допускает перерыв в обслуживании в масштабе кластера, можно использовать этот быстрый и надежный метод, позволяющий полностью избежать функционирования узлов в смешанном режиме. Использование снимка для возврата конфигурации HACMP после обновления всех узлов позволяет избежать потенциальных проблем, которые могут возникнуть в процессе циклической миграции. Дополнительные сведения о потенциальных проблемах см. в разделе "Аспекты", в этой лекции.