|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Опубликован: 21.08.2007 | Доступ: свободный | Студентов: 1821 / 194 | Оценка: 4.23 / 3.74 | Длительность: 15:37:00
Тема: Программирование
Специальности: Программист, Системный архитектор
Лекция 2:
Определение языков программирования
Аннотация: В данной лекции рассматривается задача определения систем программирования. Строится простейшее определение семантики языка программирования в виде интерпретатора, задающего операционную семантику на примере подмножества языка Лисп
Ключевые слова: определение, Лисп, синтаксис, семантика, прагматика, класс, IBM, ПО, абстрактный синтаксис, абстрактная машина, автомат, представление, отображение, АС, функция, компромисс, операционная семантика, БНФ, семантическая функция, вычисление, значение, YACC, константы, подкласс, переменная, объединение, выражение, статическое связывание, ветвь, список, аргумент, категории функций, списочные структуры, множества, интерпретатор, теория вычислений, безымянная функция, имя новой функции, ассоциативный список, evcon, evlis, верификации программы, рекурсивно определенная функция
Прежде чем анализировать конкретные парадигмы программирования, рассматривается задача определения систем программирования. Строится простейшее определение семантики языка программирования в виде интерпретатора, задающего операционную семантику на примере подмножества языка Лисп.
Обычно при разработке системы программирования различают три уровня: синтаксис, семантика и прагматика реализуемого языка. Разграничение уровней носит условный характер, но можно констатировать, что синтаксис определяет внешний вид программ, семантика задает класс процессов, порождаемых программами, а прагматика реализует процессы в рамках конкретных условий применения программ. При изучении парадигм программирования центральную роль играет семантика, а синтаксис и прагматика используются как вспомогательные построения на примерах. Венская методика определения языков программирования с помощью операционной семантики, использующей концепции программирования при спецификации систем программирования, удобна для сравнения парадигм программирования [ [ 74 ] ].
Венский метод (ВМ) определения языков программирования был разработан в 1968 году в Венской лаборатории IBM под руководством П. Лукаса на основе идей, восходящих к Дж. Маккарти [ [ 74 ] , [ 75 ] ]. Благодаря хорошо разработанной концепции абстрактных объектов, позволяющей концентрировать внимание лишь на существенном и игнорировать второстепенные детали, Венский метод годится для описания и машин, и алгоритмов, и структур данных, особенно при обучении основам системного программирования. По мнению В.Ш. Кауфмана Венский метод вне конкуренции в области описания абстрактных процессов, в частности, процессов интерпретации программ на языках программирования. Согласно концепции абстрактных объектов (абстрактный синтаксис, абстрактная машина, абстрактные процессы) интерпретирующий автомат содержит в качестве компоненты состояния управляющую часть, содержимое которой может изменяться с помощью операций, подобно прочим данным, имеющимся в этом состоянии [ [ 53 ] ].
Модель автомата с состояниями в виде древовидных структур данных, созданного согласно Венской методике для интерпретации программ, является достаточно простой. Тем не менее она позволяет описывать основные нетривиальные понятия программирования, включая локализацию определений по иерархии блоков вычислений, вызовы процедур и функций, передачу параметров. Такая модель дает представление понятий программирования, полезное в качестве стартовой площадки для изучения разных парадигм программирования и сравнительного анализа стилей программирования.
Определение языка программирования (ЯП) по Венской методике начинается с четкого отделения существа семантики от синтаксического разнообразия определяемого языка [ [ 74 ] ]. С этой целью задается отображение конкретного синтаксиса (КС) ЯП в абстрактный (АС), вид которого инвариантен для семейства эквивалентных языков.
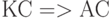
Семантика ЯП определяется как универсальная интерпретирующая функция (ИФ), дающая смысл любой программе, представленной в терминах АС. Такая функция использует определенную языком схему команд - языково ориентированную абстрактную машину (АМ), позволяющую смысл программ формулировать без конкретики компьютерных архитектур.
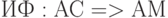
Выбор команд абстрактной машины представляет собой компромисс между уровнем базовых средств языка и сложность их реализации на предполагаемых конкретных машинах (КМ), выбор которых осуществляется на уровне прагматики.
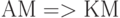
Способ такого определения семантики языка программирования с помощью интерпретатора над языково ориентированной абстрактной машиной называют операционной семантикой языка. Принятая в операционной семантике динамика управления обладает большей гибкостью, чем это принято в стандартных системах программирования (СП) компилирующего типа. Это показывает резервы развития СП навстречу современным условиям разработки и применения информационных систем с повышенными требованиями к надежности и безопасности.
Синтаксис программ в языке программирования сводится к правилам представления данных, операторов и выражений языка. Начнем с выбора абстрактного синтаксиса на примере определения небольшого, но функционально полного подмножества языка Лисп [ [ 75 ] ].
Конкретный синтаксис языков программирования принято представлять в виде простых БНФ (Формул Бекуса-Наура). Данные языка Лисп - это атомы, списки и более общие структуры из бинарных узлов - пар, строящихся из любых данных:
<атом> ::= <БУКВА> <конец_атома>
<конец_атома> ::= <пусто>
| <БУКВА> <конец_атома>
| <цифра> <конец_атома>
<данное> ::= <атом>
| (<данное> ... ) -- список
2.1.
Синтаксис данных языка Лисп
Это правило констатирует, что данные - это или атомы, или списки из данных.
/Три точки означают, что допустимо любое число вхождений предшествующего вида объектов, включая ни одного./
Согласно такому правилу () есть допустимое данное. Оно в языке Лисп по соглашению эквивалентно атому Nil.
Такая единая структура данных вполне достаточна для представления сколь угодно сложных программ. Дальнейшее определение языка Лисп можно рассматривать как восходящий процесс генерации семантического каркаса, по ключевым позициям которого распределены семантические действия по обработке программ. Позиции распознаются как вызовы соответствующих семантических функций.
Другие правила представления данных нужны лишь при расширении и специализации лексики языка (числа, строки, имена особого вида и т.п.). Они не влияют ни на общий синтаксис языка, ни на строй его понятий, а лишь характеризуют разнообразие сферы его конкретных приложений.
Абстрактный синтаксис программ является утончением синтаксиса данных, а именно - выделением подкласса вычислимых выражений (форм), т.е. данных, имеющих смысл как выражения языка и приспособленных к вычислению. Внешне это выглядит как объявление объектов, заранее известных в языке, и представление разных форм, вычисление которых обладает определенной спецификой.
Операционная семантика языка определяется как интерпретация абстрактного синтаксиса, представляющего выражения, имеющие значение. Учитывая исследованность проблем синтаксического анализа и существование нормальных форм, гарантирующих генерацию оптимальных распознавателей программными инструментами типа YACC-LEX, в качестве абстрактного синтаксиса для Лиспа выбрано не текстовое, а списочное представление программ. Такое решение снимает задачу распознавания конструкций языка - она решается простым анализом первых элементов списков. Одновременно решается и задача перехода от конкретного синтаксиса текстов языка к абстрактному синтаксису его понятийной структуры. Переход получается просто чтением текста, строящим древовидное представление программы.
Ниже приведены синтаксические правила для обычных конструкций, к которым относятся идентификаторы, переменные, константы, аргументы, формы и функции. (Правила упорядочены по сложности взаимосвязи формул.)
<идентификатор> ::= <атом>
Идентификатор - это подкласс атомов, используемых при именовании неоднократно используемых объектов программы - функций и переменных. Предполагается, что идентифицируемые объекты размещаются в памяти так, что по идентификатору их можно найти.
<форма> ::= <константа>
| <переменная>
| (<функция> <аргумент> ... )
| (IF <предикат> <форма> <форма> )
<константа> ::= (QUOTE <данное>)
<переменная> ::= <идентификатор>
<аргумент> ::= <форма>
<предикат> ::= <форма>
Пример
2.2.
Синтаксис выражений подмножества языка Лисп
Переменная - это подкласс идентификаторов, которым сопоставлено многократно используемое значение, ранее вычисленное в подходящем контексте. Подразумевается, что одна и та же переменная в разных контекстах может иметь разные значения.
Таким образом, класс форм - это объединение класса переменных и подкласса списков, начинающихся с QUOTE, IF или с представления некоторой функции.
Форма - это выражение, которое может быть вычислено.
Форма, представляющая собой константу, выдает эту константу как свое значение. В таком случае нет необходимости в вычислениях, независимо от вида константы. Константные значения могут быть любой сложности, включая вычислимые выражения. Чтобы избежать двусмысленности, предлагается константы изображать как результат специальной функции QUOTE, блокирующей вычисление. Представление констант с помощью QUOTE устанавливает границу, далее которой вычисление не идет. Константные значения аргументов характерны при тестировании и демонстрации программ.
Если форма представляет собой переменную, то ее значением должно быть данное, связанное с этой переменной до момента вычисления формы. ( Динамическое связывание, в отличие от традиционного правила, требующего связывания к моменту описания формы, т.е. статического связывания.)
Третья ветвь определения формы гласит, что можно написать функцию, затем перечислить ее аргументы, и все это как общий список заключить в скобки.
Аргументы представляются формами. Это означает, что допустимы композиции функций. Обычно аргументы вычисляются в порядке вхождения в список аргументов. Позиция "аргумент" выделена для того, чтобы было удобно в дальнейшем локализовать разные схемы обработки аргументов в зависимости от категории функций. Аргументом может быть любая форма, но метод вычисления аргументов может варьироваться. Функция может не только учитывать тип обрабатываемого данного, но и управлять временем обработки данных, принимать решения по глубине и полноте анализа данных, обеспечивать продолжение счета при исключительных ситуациях и т.п.