
| Китай, ?? |
Инспектор
Вы можете этот курс.
Опубликован: 12.07.2012 | Уровень: специалист | Доступ: платный
Лекция 7:
OpenMP fundamentials
OpenMP for directive
#pragma omp for [ clause [ clause ] ...
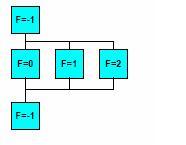
Following loop will be executed in parallel (the iterations will be divided by the execution threads)
#pragma omp parallel private(f)
{
f=7;
#pragma omp for
for (i=0; i<20; i++)
a[i] = b[i] + f * (i+1);
} /* omp end parallel */
private( list ) reduction( operator: list ) schedule( type [ , chunk ] ) nowait (для #pragma omp for)
At the end of the loop all threads will be synchronized unless"nowait" directive is mentioned
schedule defines iteration space scattering method (default behaviour depend on OpenMP version)
OpenMP variables
- private ( list ) Each of the listed variables will have the local copy for each exection thread
- shared ( list ) All the thread will share the same instance of the variable
- firstprivate ( list ) All the local copies will be initialized by master thread value
- lastprivate ( list ) The resulting master thread value will be taken from the last thread executed
- …
All the variables are shared by default, except the local variables inside a function calls and the loop iterators
Example
int x;
x = 0; // Initialize x to zero
#pragma omp parallel for firstprivate(x) // Copy value
// of x
// from master
for (i = 0; i < 10000; i++) {
x = x + i;
}
printf( "x is %d\n", x ); // Print out value of x
/* Actually needs lastprivate(x) to copy value back out to master */
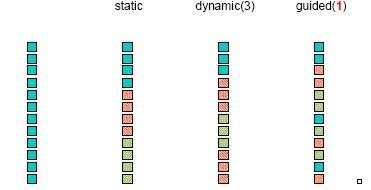
OpenMP schedule clause
- static: Every thread gets fixed amount of data
- dynamic: Amount of data will depend on the thread execution speed
- guided: Threads will get decreased amounts of data dynamically
- runtime: Schedule type will be defined at runtime
Main OpenMP functions
int omp_get_num_threads(void); int omp_get_thread_num(void); …
OpenMP synchronization
Implicit sunchrionization is performed at the end of any parallel section (unless nowait option is mentioned)
- сritical – can be executed only by one thread at a time.
- atomic – Special critical section version for the atomic operations
- barrier – synchronization point
- ordered – sequential execution
- master – only the main thread will execute the following code
- …
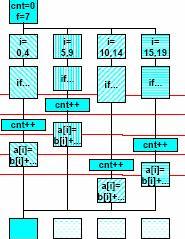
OpenMP critical
cnt = 0;
f=7;
#pragma omp parallel
{
#pragma omp for
for (i=0; i<20; i++) {
if (b[i] == 0) {
#pragma omp critical
cnt ++;
} /* endif */
a[i] = b[i] + f * (i+1);
} /* end for */
} /*omp end parallel */
More information
OpenMP Homepage: http://www.openmp.org/
Introduction to OpenMP - tutorial from WOMPEI 2000 http://www.llnl.gov/computing/tutorials/workshops/workshop/openMP
Writing and Tuning OpenMP Programs on Distributed Shared Memory Machines http://www.sao.nrc.ca/~gabriel/openmp
R.Chandra, L. Dagum, D. Kohr, D. Maydan, J. McDonald, R. Menon:
Parallel programming in OpenMP.
Academic Press, San Diego, USA, 2000, ISBN 1-55860-671-8
R. Eigenmann, Michael J. Voss (Eds):
OpenMP Shared Memory Parallel Programming.