Инспектор

Вы можете этот курс.
Опубликован: 22.04.2006 | Уровень: специалист | Доступ: платный
Лекция 24:
Инструменты Data Mining. Система PolyAnalyst
Модули текстового анализа
В системе PolyAnalyst реализована интеграция инструментов Data Mining с методами анализа текстов на естественном языке - алгоритмов Text Mining. Иллюстрация работы модулей текстового анализа показана на рис. 24.3.
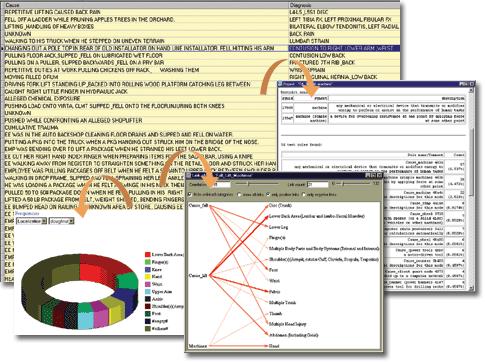
Text Analysis (ТА) - текстовый анализ
Text Analysis представляет собой средство формализации неструктурированных текстовых полей в базах данных. При этом текстовое поле представляется как набор булевых признаков, основанных на наличии и/или частоте данного слова, устойчивого словосочетания или понятия (с учетом отношений синонимии и "общее-частное") в данном тексте. Тем самым появляется возможность распространить на текстовые поля всю мощь алгоритмов Data Mining, реализованных в системе PolyAnalyst. Кроме того, этот метод может быть использован для лучшего понимания текстовой компоненты данных за счет автоматического выделения наиболее распространенных ключевых понятий.
Text Categorizer (TC) - каталогизатор текстов
Этот модуль позволяет автоматически создать иерархический древовидный каталог имеющихся текстов и пометить каждый узел этой древовидной структуры наиболее индикативным для относящихся к нему текстов. Это нужно для понимания тематической структуры анализируемой совокупности текстовых полей и для эффективной навигации по ней.
Link Terms (LT) - связь понятий
Этот модуль позволяет выявлять связи между понятиями, встречающимися в текстовых полях изучаемой базы данных, и представлять их в виде графа. Граф также может быть использован для выделения записей, реализующих выбранную связь.
В PolyAnalyst встроены алгоритмы работы с текстовыми данными двух видов:
- Алгоритмы, извлекающие ключевые понятия и работающие с ними.
- Алгоритмы, сортирующие тексты на классы, которые определяются пользователем с помощью языка запросов.
Первый вид алгоритмов работает только с текстами на английском языке - при этом используется специальный словарь понятий английского языка. Алгоритмы второго типа могут работать с текстами и на английском, и на русском языках.
Text OLAP (матрицы измерений) и Taxonomies (таксономии) - это похожие друг на друга методы категоризации текстов. В Text OLAP пользователь создает именованные столбцы (измерения), состоящие из текстовых запросов. Например: "[добыча] и [нефть] и не ([руда] или [уголь] или [газ])". В процессе работы алгоритма PolyAnalyst применяет каждое из условий к каждому документу в базе данных и в случае удовлетворения условия относит этот документ к соответствующей категории. После работы модуля пользователь может выбирать различные элементы матрицы измерений и просматривать на экране тексты, удовлетворяющие выбранным условиям. Найденные слова будут в этих документах подкрашены разным цветом.
Работа с таксономиями очень похожа на работу с Text OLAP, только здесь пользователь строит иерархическую структуру из таких же условий, как и в матрицах измерений. Система пытается соотнести каждый документ с узлами этого дерева. После работы модуля пользователь также может перемещаться по узлам наполненной таксономии, просматривая отфильтрованные документы с подкрашенными словами.
Матрицы измерений и таксономии дают возможность пользователю взглянуть на коллекцию его документов под самыми разными углами. Но это не все: на основе этих объектов можно делать и другие, более сложные методы анализа, (например, анализ связей (Link Analysis), который показывает, насколько связаны друг с другом различные категории текстов, описанные пользователем) или включать тексты как независимые сущности в другие методы линейного и нелинейного анализа. Все это приводит к плотной интеграции подходов Data Mining и Text Mining в единую концепцию анализа информации.