|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Инспектор
Вы можете этот курс.
Опубликован: 01.03.2005 | Уровень: для всех | Доступ: платный
Лекция 10:
Базы данных и СУБД. Введение в SQL
Аннотация: В лекции рассматриваются понятия базы данных и СУБД, дается краткое
описание существующих типов баз данных (сетевые, реляционные,
иерархические). Рассматриваются основы языка запросов SQL: операции
выбора, добавления, изменения и удаления строки, а также операции
создания, изменения и удаления таблицы. База данных MySql.
Использование PhpMyAdmin для взаимодействия с базой данных MySql.
Обсуждаются основные принципы отображения объектной модели документа
на реляционную структуру базы данных. Пример – проектирование базы
данных виртуального музея истории.
Ключевые слова: база данных, mysql, реализация языка, SQL, СУБД, адрес, средства автоматизации, ПО, определение, глоссарий, информационная модель предметной области, централизованное управление, реляционная модель, объединение, пересечение, разность, декартово произведение, представление, отношение, информация, cache, IBM, DB2, ключ, индексирование, первичный ключ, структуры хранения, организация связи, artifact, внешний ключ, ссылочная целостность, последовательный перебор, PRIMARY, UNIQUE, INDEX, B-дерево, уникальный индекс, ключ индекса, phpmyadmin, Internet, Windows, файл, сервер, права, доступ, администратор, пароль, команда, оператор DELETE, flush, privileges, GRANT, localhost, пользователь, структурированный язык, SQL/89, SQL/92, SQL3, компания oracle, компания informix, компания ibm, оператор CREATE TABLE, оператор ALTER TABLE, оператор DROP TABLE, имя таблицы, temporary, unsigned, BLOB, ENUM, foreign, heap, ISAM, innodb, myisam, оператор SELECT, restriction, ALTER, SET DEFAULT, literal, DESCRIBE, ASC, DESC, AVG, оператор INSERT, delay, оператор UPDATE
В данной лекции мы рассмотрим основные понятия теории баз данных и познакомим читателей с системой управления базами данных MySql, способами работы с ней, ее особенностями и реализацией языка запросов SQL в этой СУБД. В основе приводимых в лекции примеров лежит информационная модель виртуального музея истории информатики. Эта модель есть набор коллекций описания исторических личностей, экспонатов музея (артефактов), статей и изображений.
Базы данных: основные понятия
В жизни мы часто сталкиваемся с необходимостью хранить какую-либо информацию, а потому часто имеем дело и с базами данных. Например, мы используем записную книжку для хранения номеров телефонов своих друзей и планирования своего времени. Телефонная книга содержит информацию о людях, живущих в одном городе. Все это своего рода базы данных. Ну а раз это базы данных, то посмотрим, как в них хранятся данные. Например, телефонная книга представляет собой таблицу (табл. 10.1).
В этой таблице данные – это собственно номера телефонов, адреса и ФИО., т.е. строки "Иванов Иван Иванович", "32-43-12" и т.п., а названия столбцов этой таблицы, т.е. строки "ФИО", "Номер телефона" и "Адрес" задают смысл этих данных, их семантику.
| ФИО | Номер телефона | Адрес |
|---|---|---|
| Иванов Иван Иванович | 32-43-12 | ул. Ленина, 12, 43 |
| Ильин Федор Иванович | 32-32-34 | пр. Маркса, 32, 45 |
Теперь представьте, что записей в этой таблице не две, а две тысячи, вы занимаетесь созданием этого справочника и где-то произошла ошибка (например, опечатка в адресе). Видимо, тяжеловато будет найти и исправить эту ошибку вручную. Нужно воспользоваться какими-то средствами автоматизации. Для управления большим количеством данных программисты (не без помощи математиков) придумали системы управления базами данных ( СУБД ). По сравнению с текстовыми базами данных электронные СУБД имеют огромное число преимуществ, от возможности быстрого поиска информации, взаимосвязи данных между собой до использования этих данных в различных прикладных программах и одновременного доступа к данным нескольких пользователей.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных – это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных ( СУБД ). СУБД обеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.
Итак, мы пришли к выводу, что хранить данные независимо от программ, так, что они связаны между собой и организованы по определенным правилам, целесообразно. Но вопрос, как хранить данные, по каким правилам они должны быть организованы, остался открытым. Способов существует множество (кстати, называются они моделями представления или хранения данных). Наиболее популярные – объектная и реляционная модели данных.
Автором реляционной модели считается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данных представляет собой набор таблиц (точно таких же, как приведенная выше), связанных между собой. Строка в таблице соответствует сущности реального мира (в приведенном выше примере это информация о человеке).
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной модели положена концепция объектно-ориентированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone (от Servio Corporation), ONTOS (ONTOS).
В последнее время производители СУБД стремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры таких СУБД – IBM DB2 for Common Servers, Oracle8.
Поскольку мы собираемся работать с Mysql, то будем обсуждать аспекты работы только с реляционными базами данных. Нам осталось рассмотреть еще два важных понятия из этой области: ключи и индексирование, после чего мы сможем приступить к изучению языка запросов SQL.
Ключи
Для начала давайте подумаем над таким вопросом: какую информацию нужно дать о человеке, чтобы собеседник точно сказал, что это именно тот человек, сомнений быть не может, второго такого нет? Сообщить фамилию, очевидно, недостаточно, поскольку существуют однофамильцы. Если собеседник человек, то мы можем приблизительно объяснить, о ком речь, например вспомнить поступок, который совершил тот человек, или еще как-то. Компьютер же такого объяснения не поймет, ему нужны четкие правила, как определить, о ком идет речь. В системах управления базами данных для решения такой задачи ввели понятие первичного ключа.
Первичный ключ (primary key, PK) – минимальный набор полей, уникально идентифицирующий запись в таблице. Значит, первичный ключ – это в первую очередь набор полей таблицы, во-вторых, каждый набор значений этих полей должен определять единственную запись (строку) в таблице и, в-третьих, этот набор полей должен быть минимальным из всех обладающих таким же свойством. Поскольку первичный ключ определяет только одну уникальную запись, то никакие две записи таблицы не могут иметь одинаковых значений первичного ключа .
Например, в нашей таблице (см. выше) ФИО и адрес позволяют однозначно выделить запись о человеке. Если же говорить в общем, без связи с решаемой задачей, то такие знания не позволяют точно указать на единственного человека, поскольку существуют однофамильцы, живущие в разных городах по одному адресу. Все дело в границах, которые мы сами себе задаем. Если считаем, что знания ФИО, телефона и адреса без указания города для наших целей достаточно, то все замечательно, тогда поля ФИО и адрес могут образовывать первичный ключ. В любом случае проблема создания первичного ключа ложится на плечи того, кто проектирует базу данных (разрабатывает структуру хранения данных). Решением этой проблемы может стать либо выделение характеристик, которые естественным образом определяют запись в таблице (задание так называемого логического, или естественного, PK), либо создание дополнительного поля, предназначенного именно для однозначной идентификации записей в таблице (задание так называемого суррогатного, или искусственного, PK). Примером логического первичного ключа является номер паспорта в базе данных о паспортных данных жителей или ФИО и адрес в телефонной книге (таблица выше). Для задания суррогатного первичного ключа в нашу таблицу можно добавить поле id (идентификатор), значением которого будет целое число, уникальное для каждой строки таблицы. Использование таких суррогатных ключей имеет смысл, если естественный первичный ключ представляет собой большой набор полей или его выделение нетривиально.
Кроме однозначной идентификации записи, первичные ключи используются для организации связей с другими таблицами.
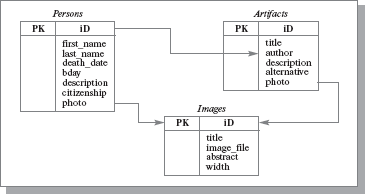
Например, у нас есть три таблицы: содержащая информацию об исторических личностях (Persons), содержащая информацию об их изобретениях (Artifacts) и содержащая изображения как личностей, так и артефактов (Images) (рис 10.1).
Первичным ключом во всех этих таблицах является поле id (идентификатор). В таблице Artifacts есть поле author, в котором записан идентификатор, присвоенный автору изобретения в таблице Persons. Каждое значение этого поля является внешним ключом для первичного ключа таблицы Persons. Кроме того, в таблицах Persons и Artifacts есть поле photo, которое ссылается на изображение в таблице Images. Эти поля также являются внешними ключами для первичного ключа таблицы Images и устанавливают однозначную логическую связь Persons-Images и Artifacts-Images. То есть если значение внешнего ключа photo в таблице личности равно 10, то это значит, что фотография этой личности имеет id=10 в таблице изображений. Таким образом, внешние ключи используются для организации связей между таблицами базы данных (родительскими и дочерними) и для поддержания ограничений ссылочной целостности данных.
Индексирование
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно небольшое время и с достаточной точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше таблица, тем больше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY , UNIQUE , и INDEX , а слово ключ ( KEY ) используется как синоним слова индекс ( INDEX ). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL ). Таблица может иметь только один первичный индекс, но он может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как мы описали выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Федор Антонов
Сергей Крупко
|
Добрый день. Я сейчас прохожу курс повышения квалификации - "Профессиональное веб-программирование". Мне нужно получить диплом по этому курсу. Я так полагаю нужно его оплатить чтобы получить диплом о повышении квалификации. Как мне оплатить этот курс?
|
Александр Верещагин
| Россия, Тольятти, ОАО "АвтоВАЗ", Инженер-программист 1 категории отдела информационной безопасности специального управления |