
|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Инспектор
Вы можете этот курс.
Опубликован: 16.12.2009 | Уровень: для всех | Доступ: платный
Дополнительный материал 1:
Вероятностно-статистические основы эконометрики
П1-2. Математическая статистика и ее новые разделы
Приведем краткие описания (типа статей в энциклопедических изданиях) математической статистики и ее наиболее важных для эконометрики сравнительно новых разделов, разработанных в основном после 1970 г., а именно, статистики объектов нечисловой природы и статистики интервальных данных.
Статистика математическая - наука о математических методах анализа данных, полученных при проведении массовых наблюдений (измерений, опытов). В зависимости от математической природы конкретных результатов наблюдений статистика математическая делится на статистику чисел, многомерный статистический анализ, анализ функций (процессов) и временных рядов, статистику объектов нечисловой природы. Существенная часть статистики математической основана на вероятностных моделях.
Выделяют общие задачи описания данных, оценивания и проверки гипотез. Рассматривают и более частные задачи, связанные с проведением выборочных обследований, восстановлением зависимостей, построением и использованием классификаций (типологий) и др.
Для описания данных строят таблицы, диаграммы, иные наглядные представления, например, корреляционные поля. Вероятностные модели обычно не применяются. Некоторые методы описания данных опираются на продвинутую теорию и возможности современных компьютеров. К ним относятся, в частности, кластер-анализ, нацеленный на выделение групп объектов, похожих друг на друга, и многомерное шкалирование, позволяющее наглядно представить объекты на плоскости, в наименьшей степени исказив расстояния между ними.
Методы оценивания и проверки гипотез опираются на вероятностные модели порождения данных. Эти модели делятся на параметрические и непараметрические. В параметрических моделях предполагается, что изучаемые объекты описываются функциями распределения, зависящими от небольшого числа (1-4) числовых параметров. В непараметрических моделях функции распределения предполагаются произвольными непрерывными. В статистике математической оценивают параметры и характеристики распределения (математическое ожидание, медиану, дисперсию, квантили и др.), плотности и функции распределения, зависимости между переменными (на основе линейных и непараметрических коэффициентов корреляции, а также параметрических или непараметрических оценок функций, выражающих зависимости) и др. Используют точечные и интервальные (дающие границы для истинных значений) оценки.
В статистике математической есть общая теория проверки гипотез и большое число методов, посвященных проверке конкретных гипотез. Рассматривают гипотезы о значениях параметров и характеристик, о проверке однородности (т.е. о совпадении характеристик или функций распределения в двух выборках), о согласии эмпирической функции распределения с заданной функцией распределения или с параметрическим семейством таких функций, о симметрии распределения и др.
Большое значение для эконометрики имеет раздел статистики математической, связанный с проведением выборочных обследований, со свойствами различных схем организации выборок и построением адекватных методов оценивания и проверки гипотез.
Задачи восстановления зависимостей активно изучаются более 200 лет, с момента разработки К. Гауссом в 1794 г. метода наименьших квадратов. В настоящее время наиболее актуальны методы поиска информативного подмножества переменных и непараметрические методы.
Различные методы построения (кластер-анализ), анализа и использования (дискриминантный анализ) классификаций (типологий) именуют также методами распознавания образов (с учителем и без), автоматической классификации и др.
Математические методы в статистике основаны либо на использовании сумм (на основе Центральной Предельной Теоремы теории вероятностей) или показателей различия (расстояний, метрик), как в статистике объектов нечисловой природы. Строго обоснованы обычно лишь асимптотические результаты. В настоящее время компьютеры играют большую роль в статистике математической. Они используются как для расчетов, так и для имитационного моделирования (в частности, в методах размножения выборок и при изучении пригодности асимптотических результатов).
Классическая статистика математическая лучше всего представлена в [2], [3]. Обзор современного состояния статистики математической дан в [5].
Статистика объектов нечисловой природы - раздел математической статистики, в котором статистическими данными являются объекты нечисловой природы, т.е. элементы множеств, не являющихся линейными пространствами. Объекты нечисловой природы нельзя складывать и умножать на число. Примерами являются результаты измерений в шкалах наименований, порядка, интервалов; ранжировки, разбиения, толерантности и другие бинарные отношения; результаты парных и множественных сравнений; люсианы, т.е. конечные последовательности из 0 и1; множества; нечеткие множества. Необходимость применения объектов нечисловой природы возникает во многих областях научной и практической деятельности, в том числе и в социологии. Примерами являются ответы на "закрытые" вопросы в эконометрических, маркетинговых, социологических анкетах, в которых респондент должен выбрать одну или несколько из фиксированного числа подсказок, мили измерение мнений о привлекательности (товаров, услуг, профессий, политиков и др.), проводимое по порядковой шкале. Наряду со специальными теориями для каждого отдельного вида объектов нечисловой природы в статистике объектов нечисловой природы имеется и теория обработки данных, лежащих в пространстве общей природы, результаты которой применимы во всех специальных теориях.
В статистике объектов нечисловой природы классические задачи математической статистики - описание данных, оценивание, проверку гипотез - рассматривают для данных неклассического типа, что приводит к своеобразию постановок задач и методов их решения. Например, из-за отсутствия линейной структуры в пространстве, в котором лежат статистические данные, в статистике объектов нечисловой природы математическое ожидание определяют не через сумму или интеграл, как в классическом случае, а как решение задачи минимизации некоторой функции. Эта функция представляет собой математическое ожидание (в классическом смысле) показателя различия между значением случайного объекта нечисловой природы и фиксированным элементом пространства. Эмпирическое среднее определяют как результат минимизации суммы расстояний от нечисловых результатов наблюдений до фиксированного элемента пространства. Справедлив закон больших чисел: эмпирическое среднее сходится при увеличении объема выборки к математическому ожиданию, если результаты наблюдений являются независимыми одинаково распределенными случайными объектами нечисловой природы и выполнены некоторые математические "условия регулярности".
Аналогичным образом определяют условное математическое ожидание и регрессионную зависимость. Из доказанной в статистике объектов нечисловой природы сходимости решений экстремальных статистических задач к решениям соответствующих предельных задач вытекает состоятельность оценок в параметрических задачах оценивания параметров и аппроксимации, а также ряд результатов в многомерном статистическом анализе. Большую роль в статистике объектов нечисловой природы играют непараметрические методы, в частности, методы непараметрической оценки плотности и регрессионной зависимости в пространствах общей природы, в том числе и в дискретных пространствах.
Для решения многих задач статистики объектов нечисловой природы - нахождения эмпирического среднего, оценки регрессионной зависимости, классификации наблюдений и др. - используют показатели различия (меры близости, расстояния, метрики) между элементами рассматриваемых пространств, вводимые аксиоматически. Так, в монографии [6] аксиоматически введено расстояние между множествами. Принятое в теории измерений как части статистики объектов нечисловой природы условие адекватности (инвариантности) алгоритмов анализа данных позволяет указать вид средних величин, расстояний, показателей связи и т.д., соответствующих измерениям в тех или иных шкалах. Методы построения, анализа и использования классификаций и многомерного шкалирования дают возможность сжать информацию и дать ей наглядное представление. К статистике объектов нечисловой природы относятся методы ранговой корреляции, статистического анализа бинарных отношений (ранжировок, разбиений, толерантностей), параметрические и непараметрические методы обработки результатов парных и множественных сравнений. Теория люсианов (последовательностей независимых испытаний Бернулли) развита в асимптотике растущей размерности.
Статистика объектов нечисловой природы как самостоятельный раздел прикладной математической статистики выделена в монографии [6]. Обзору ее основных направлений посвящен, например, сборник [7]. Ей посвящен раздел в энциклопедии [2].
Статистика интервальных данных (СИД) - раздел статистики объектов нечисловой природы, в котором элементами выборки являются интервалы в 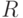 , в частности, порожденные наложением ошибок измерения на значения случайных величин. СИД входит в теорию устойчивости (робастности) статистических процедур (см. [6]) и примыкает к интервальной математике (см. [8]). В СИД изучены проблемы регрессионного анализа, планирования эксперимента, сравнения альтернатив и принятия решений в условиях интервальной неопределенности и др.
, в частности, порожденные наложением ошибок измерения на значения случайных величин. СИД входит в теорию устойчивости (робастности) статистических процедур (см. [6]) и примыкает к интервальной математике (см. [8]). В СИД изучены проблемы регрессионного анализа, планирования эксперимента, сравнения альтернатив и принятия решений в условиях интервальной неопределенности и др.
Развиты асимптотические методы статистического анализа интервальных данных при больших объемах выборок и малых погрешностях измерений. В отличие от классической математической статистики, сначала устремляется к бесконечности объем выборки и только потом - уменьшаются до нуля погрешности. Разработана общая схема исследования (см. [13]), включающая расчет двух основных характеристик СИД - н о т н ы (максимально возможного отклонения статистики, вызванного интервальностью исходных данных) и р а ц и о н а л ь н о г о о б ъ е м а в ы б о р к и (превышение которого не дает существенного повышения точности оценивания и статистических выводов, связанных с проверкой гипотез). Она применена к оцениванию математического ожидания и дисперсии, медианы и коэффициента вариации, параметров гамма-распределения в ГОСТ 11.011-83 [14] и характеристик аддитивных статистик, для проверки гипотез о параметрах нормального распределения, в т.ч. с помощью критерия Стьюдента, а также гипотезы однородности двух выборок по критерию Смирнова, и т.д.. Разработаны подходы СИД в основных постановках регрессионного, дискриминантного и кластерного анализов (см. [15]).
Многие утверждения СИД отличаются от аналогов из классической математической статистики. В частности, не существует состоятельных оценок: средний квадрат ошибки оценки, как правило, асимптотически равен сумме дисперсии этой оценки, рассчитанной согласно классической теории, и квадрата нотны. Метод моментов иногда оказывается точнее метода максимального правдоподобия. Нецелесообразно с целью повышения точности выводов увеличивать объем выборки сверх некоторого предела. В СИД классические доверительные интервалы должны быть расширены вправо и влево на величину нотны, и длина их не стремится к 0 при росте объема выборки.
Многим задачам классической математической статистики могут быть поставлены в соответствие задачи СИД, в которых элементы выборок - действительные числа заменены на интервалы. В статистическое программное обеспечение включают алгоритмы СИД, "параллельные" их аналогам из классической математической статистики. Это позволяет учесть наличие погрешностей у результатов наблюдений.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |