
| Россия, Привольная 1/2 |
Инспектор
Вы можете этот курс.
Опубликован: 28.08.2008 | Уровень: специалист | Доступ: платный | ВУЗ: Компания IBM
Лекция 3:
Технология PowerPC
Процессоры третьего поколения Apache
Модели AS/400 1997 года используют новый дизайн процессора. Этот однокристальный процессор PowerPC, разработанный в Рочестере и названный Apache. Он предназначен для средних и старших моделей AS/400е. Младшие модели серии по-прежнему используют процессор Cobra.
Apache можно считать процессором третьего поколения. В его основе — процессор Cobra, улучшенный и оснащенный новыми возможностями, например поддержки многопроцессорных систем. Apache — первый однокристальный процессор AS/400, которому по силам поддержка конфигурации SMP до 12 процессоров (даже Muskie поддерживал лишь четырехпроцессорные конфигурации).
В отличие от Cobra или Muskie, Apache полностью реализует архитектуру PowerPC. Он использует режим активных тегов для поддержки одноуровневой памяти AS/400 и режим неактивных тегов — для поддержки стандартной модели адресации PowerPC; а также стандартные шины адреса и данных PowerPC 6хх — для соединений за пределами кристалла. Так что Apache можно использовать с любой вспомогательной микросхемой, разработанной для семейства процессоров PowerPC 6хх. (О том, как это позволило преобразовать структуру вводавывода компьютеров серии AS/400е мы поговорим подробней в "Система ввода-вывода" ). Apache — первый из когда-либо разработанных в Рочестере процессоров, который может использоваться вне рочестерских систем. Процессоры Apache используются как в RS/6000, так и AS/400е.
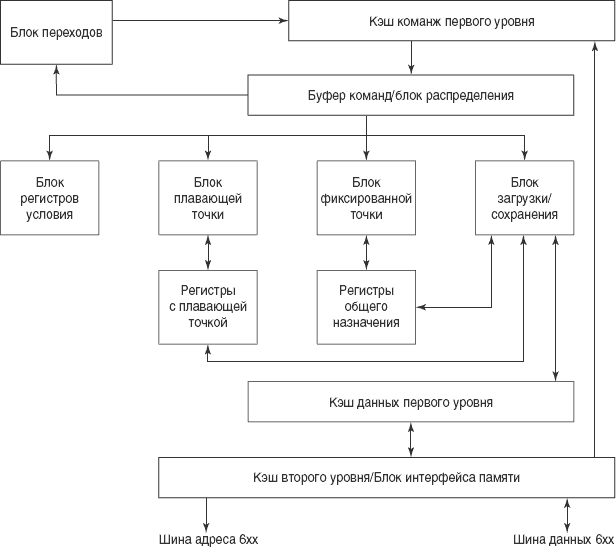
Как и Cobra, Apache — однокристальный, 64-разрядный суперскалярный RISC-процессор (его структурная схема — на рисунке 2.5). Он реализован по новейшей технологии IBM CMOS5S, что позволяет достичь большей плотности упаковки на кристалле, а также времени цикла в 8,0 наносекунд (125 МГц), хотя в некоторых моделях AS/400е используются более медленные версии. Технология КМОП значительно сокращает объем рассеиваемого тепла, который нужно отводить от процессора. В результате, на одной плате может быть установлено до четырех процессоров Apache.
В новом процессоре наиболее значительны изменения в подсистеме памяти. О том, как системы с Apache используют совершенно новую подсистему памяти, предназначенную для пересылки больших объемов данных без замедления работы, читайте в следующем разделе.
Несмотря на то, что время цикла у Apache не столь мало как в Muskie, новая подсистема памяти повышает масштабируемость Apache для конфигураций SMP, что позволяет создать еще более производительные модели AS/400е.
Прежде чем продолжить сугубо технический разговор, хочу представить вам новые корпуса, появившиеся вместе с процессорами Apache. Три оригинальных черных корпуса AS/400 Advanced Series (известные как Apex, Cedar Key и Key Largo) были заменены на два новых, также черных, корпуса (Millennium и Mako). Корпус для Advanced Entry (Eiger) остался тем же.
Мы изменили дизайн корпуса по нескольким причинам. Средние модели серии AS/400 поддерживают конфигурации SMP. Корпус Millennium допускает установку до четырех процессоров Apache, а корпус Mako для старших моделей — до 12 процессоров. (В прежний корпус для старших моделей (Key Largo) помещалось до четырех процессоров Muskie). Корпус Mako гораздо выше (около полутора метров, напоминает оригинальные белые стойки AS/400) и кроме дюжины процессоров в нем есть место для большего объема основной памяти и большего числа дисков. Новые корпуса, которые предполагается использовать в серии AS/400е до 2000 года, были разработаны совместно с подразделением RS/6000 для оптимизации общности компонентов этих систем.
Процессоры четвертого и следующих поколений
Итак, мы рассмотрели процессор Muskie и то, каким образом он производит коммерческие вычисления, обрабатывая большие объемы данных. Четырехканальная супер-скалярная архитектура, а также шины шириной 16 байт (128 бит) и 32 байта (256 бит) ясно свидетельствуют, что Muskie создан для обработки больших объемов данных и команд. А теперь представьте себе, процессор Muskie, упакованный вместе с набором 64-килобайтных кэшей для команд и данных в одну микросхему КМОП. Добавьте к этому полную архитектуру PowerPC процессора Apache и возможность поддерживать конфигурации с 12 или даже 16 процессорами. Что получилось? Конечно, это наш процессор четвертого поколения Northstar.
Сегодня можно уверенно сказать, что через несколько лет на первый план выйдут однокристальные КМОП-процессоры, помещенные в новые черные корпуса. Мы также знаем, что они будут использовать преимущества новой подсистемы памяти, впервые появившейся в Apache.
А впрочем, давайте отложим обсуждение процессоров будущего до "AS/400 в XXI веке" . Там мы рассмотрим некоторые новейшие технологии, включая те, которые сегодня раз рабатывает IBM для процессоров AS/400.
Подсистема памяти
Одна из самых больших проблем любого процессора — обеспечение его загрузки. За последние несколько лет производительность процессоров необычайно выросла, в среднем удваиваясь каждые два года. Производительность памяти и ввода-вывода не успевает за этими темпами.
В 1991 году я купил новую IBM PC для домашних нужд. В ней был установлен процессор Intel 386 20 МГц, 70-наносекундная память и жесткий диск с временем доступа 16 миллисекунд. Маломощный процессор 386 не долго меня устраивал; поэтому я, как и многие другие, начал бесконечную гонку за новейшей аппаратурой, приобретая последовательно системы с процессорами 486 и Pentium. В последнем купленном мною компьютере (который уже тоже устарел) установлены процессоры Pentium Pro 200 МГц, 60-наносекундная память и жесткие диски со временем доступа 8,5 миллисекунд.
Да, за последние несколько лет разрыв в скорости между процессором и памятью вводом/выводом вырос невероятно. Теперь вполне возможна ситуация, когда память и ввод-вывод не смогут поставлять достаточно информации для поддержания загрузки процессора, и последний будет проводить множество своих высокоскоростных циклов в ожидании выборки команд или данных.
Универсальный прием для компенсации разницы в производительности между процессором и основной памятью — применение кэшей. Как мы уже говорили, кэш — это быстродействующая память, используемая для хранения блоков команд и данных, к которым процессор недавно обращался. При этом предполагается, что в ближайшем будущем процессор будет обращаться к тем же самым блокам.
Кэши эффективны благодаря тому, что большинство программ обладают так называемыми пространственной и временной локализацией. Это означает, что программа, скорее всего, обратится к команде или элементу данных, расположенным в памяти недалеко от места последнего обращения (пространственная локализация); а также что такой доступ произойдет через короткий отрезок времени (временная локализация). Нетрудно предположить, некоторые программы обладают большей степенью локализации, чем другие. Программа, предполагающая выполнение многих циклов или большой объем повторной обработки одних и тех же данных, имеет очень высокую степень локализации. Приложения для коммерческих расчетов, наоборот, выполняют мало обработки такого сорта, и имеют несколько меньшую степень локализации. Большие кэши и иерархия кэшей могут обеспечить загрузку процессора данными и командами даже при низких уровнях локализации.
При использовании иерархии кэшей происходит следующее: если нужная процессору информация отсутствует в кэше L1, процессор обращается к кэшу L2. Если информация не найдена и там, то происходит обращение к основной памяти. Пока идет поиск информации и выборка ее в регистр, процессор простаивает. Обычно это называют циклами простоя (stall cycles) процессора. В том случае, если информации нет даже в основной памяти и система должна обратиться к диску, процессор не ждет, а переключается на выполнение другой задачи в системе. Такую ситуацию обычно называют страничной ошибкой (page fault). Подробней мы поговорим об этом в "Одноуровневая память" .
Высокая производительность Muskie достигается с помощью небольшого 8-килобайтного кэша команд L1 и 256килобайтного кэша данных L1. Большой кэш данных реализован на четырех отдельных 64килобайтных микросхемах памяти высокого быстродействия. Будучи однокристальными процессорами, Cobra и Apache имеют гораздо меньшие внутренние кэши L1 (4К и 8К для команд и данных соответственно). Эти внутренние кэши дополняются кэшами L2 большего размера, выполненными в виде отдельных микросхем. Часть производительности Apache достигается за счет очень больших кэшей L2 объемом от 4 до 8 мегабайт.
Несмотря на использование больших кэшей и иерархии кэшей, большинство процессоров все равно тратят много циклов простоя, ожидая выборки из памяти. Проблема заключается в шине между процессором и основной памятью. Большая часть систем, включая ранние AS/400, имеют одну такую шину, обычно высокоскоростную, но все равно работающую медленнее самого процессора. Например, мой Intel Pentium Pro 200 МГц работает с шиной памяти 66 МГц. Это означает, что при обращении к памяти процессор простаивает по три цикла на каждый цикл шины. Легко понять, что таких циклов простоя может быть много.
В конфигурации SMP ситуация может значительно ухудшиться. Теперь одну шину памяти и одну основную память пытаются задействовать несколько процессоров. Так как в данный момент времени шина может использоваться только одним процессором, то все остальные процессоры, которым она понадобилась в этот момент, обречены ждать. А если та же шина памяти используется еще и для вводавывода, положение еще более усугубляется.
Эта борьба за шину памяти приводит к уменьшению производительности при добавлении к системе SMP каждого нового процессора. Например, добавление второго процессора не позволит увеличить общую производительность на 100 процентов; фактическое увеличение будет несколько меньшим из-за борьбы за память. Добавление третьего и четвертого процессора еще сильнее сократит прирост производительности на один процессор. А когда дело дойдет до восьми и более процессоров, рост производительности системы SMP может и вовсе прекратиться.
Организация памяти
Давайте проведем краткий обзор организаций памяти для многопроцессорных систем. Нас интересуют три схемы организации памяти: централизованная разделяемая память, распределенная память и распределенная разделяемая память.
Машина с централизованной разделяемой памятью предоставляет центральную память для использования всеми процессорами. Обычно, к такой разделяемой памяти подключены посредством одной шины несколько десятков процессоров. Подобная организация называется SMP (ее мы рассматривали выше). Преимущества SMP в том, что все процессоры используют общую память, и время необходимое для доступа к любой части этой памяти, для них одинаково. Поэтому конфигурации SMP часто называют машинами с однородным доступом к памяти UMA (uniform memory access). Недостаток SMP — в ограниченности максимально поддерживаемого числа процессоров.
В машинах с распределенной памятью последняя поделена между несколькими узлами, каждый из которых содержит несколько процессоров, соединенных с памятью узла как в SMP. Пример — кластер AS/400 OptiConnect (подробнее см. "Интегрированная база данных" ). Иногда машины с распределенной памятью называют архитектурами без разделения (shared-nothing), так как память не разделяется между узлами, а для связи между ними используется передача сообщений. Преимущество разделяемой памяти в том, что она может быть очень большой, если такое разделение памяти не требуется приложениям.
Если каждый процессор в машине с распределенной памятью может выполнять одну и ту же операцию или одну и ту же программу над множеством независимых друг от друга наборов данных, то подобная конфигурация называется процессором с массовым параллелизмом MPP (massively parallel processor). Пример — система MPP в IBM SP2, использующая по одному процессору на узел15Когда книга готовилась к печати, появилась возможность использовать до 8 процессоров SMP в каждом узле. Кстати, SP2 изменил название и теперь называется просто SP. — Прим. консультанта.. У SP2 также очень хороший механизм передачи сообщений, позволяющий процессорам быстро обменивать ся информацией друг с другом. Системы MPP могут насчитывать тысячи процессоров; их недостаток в том, что такая архитектура полезна только для некоторых типов приложений, таких как параллельная обработка баз данных или научных вычислений (то есть там, где совместное использование данных не требуется).
Третья конфигурация — с распределенной разделяемой памятью, представляет собой вариант распределенной памяти. Здесь все узлы, состоящие из одного или нескольких процессоров, подключенных по схеме SMP, используют общее адресное пространство. Отличие этой конфигурации от машины с распределенной памятью в том, что здесь любой процессор может обратиться к любому участку памяти. Однако, время обращения к разным участкам памяти для каждого процессора различно в зависимости от того, где участок физически расположен в кластере. По этой причине такие конфигурации еще называют машинами с неоднородным доступом к памяти NUMA (nonuniform memory access). Мы рассмотрим NUMA в "AS/400 в XXI веке" .
Это отступление от основной линии повествования здесь для того, чтобы помочь Вам, читатель, понять новую подсистему памяти, используемую сейчас в серии AS/400е. Эта подсистема разработана для конфигурации SMP, так как последняя наилучшим образом подходит для решения коммерческих задач, когда процессорам требуется использовать память совместно. Но Вы увидите, что она может использоваться и с другими конфигурациями памяти.