| Беларусь, Минск |
Инспектор
Вы можете этот курс.
Опубликован: 01.02.2008 | Уровень: профессионал | Доступ: платный | ВУЗ: Компания IBM
Лекция 2:
Составляющие высокой доступности
Для вывода текущих значений используется команда lssrc -ls clstrmgrES.
odin:/# lssrc -ls clstrmgrES Current state: ST_STABLE sccsid = "@(#)36 1.135.1.37 src/43haes/usr/sbin/cluster/hacmprd/main.C, hacmp.pe, 51haes_r530, r5300525a 6/20/05 14:13:01" i_local_nodeid 1, i_local_siteid 1, my_handle 2 ml_idx[1]=0 ml_idx[2]=1 ml_idx[3]=2 There are 0 events on the Ibcast queue There are 0 events on the RM Ibcast queue CLversion: 8 Example 2-1cluster fix level is "0" The following timer(s) are currently active: Current DNP values DNP Values for NodeId 1 NodeName frigg PgSpFree = 0 PvPctBusy = 0 PctTotalTimeIdle = 0.000000 DNP Values for NodeId 2 NodeName odin PgSpFree = 130258 PvPctBusy = 0 PctTotalTimeIdle = 99.325169 DNP Values for NodeId 3 NodeName thor PgSpFree = 0 PvPctBusy = 0 PctTotalTimeIdle = 0.000000Пример 2.1. Проверка значений динамического приоритета узлов с точки зрения clstrmgrES
Порядок обработки групп ресурсов (resource group processing order)
При попытке подключения узлом нескольких групп ресурсов по умолчанию происходит объединение всех ресурсов в одну большую группу ресурсов с последующей их обработкой как одной "группы ресурсов". Это называется параллельной обработкой, хотя и не является действительной параллельной обработкой, так как обработка выполняется в едином потоке.
Такой режим работы по умолчанию может быть изменен, и для определенных групп ресурсов может быть задана последовательная обработка путем определения списка последовательной активизации. Этот список определяет порядок обработки на определенном узле, а не по всем узлам. При последовательной обработке происходит следующее:
- заданные группы ресурсов будут обрабатываться по порядку;
- группы ресурсов, содержащие только NFS-подключения, будут обрабатываться параллельно;
- остальные группы ресурсов будут обрабатываться по порядку;
- освобождение ресурсов будет осуществляться в обратном порядке.
Расположение, отменяющее приоритет (Priority override location, POL)
При перемещении группы ресурсов на другой узел или сайт, ее отключении или подключении администратором устанавливается расположение, отменяющее приоритет (POL) для узла и группы ресурсов. Так как такое действие не согласуется с установленным режимом работы групп ресурсов, задается атрибут POL, чтобы остановить немедленный возврат группы ресурсов на соответствующий узел. Этот атрибут замещает атрибут "sticky" из предыдущих версий. Группы ресурсов с конфигурацией подключения на всех доступных узлах могут подключаться и отключаться на отдельных узлах без использования атрибута POL.
Атрибут POL может быть задан как:
- Постоянный. Продолжает действовать после перезапуска служб кластера на всех узлах в кластере.
- Непостоянный: Действует только до перезапуска служб кластера на всех узлах в кластере. После перезагрузки кластера группа ресурсов возвращается к стандартному режиму работы.
Примечание. При перемещении группы ресурсов с политикой "без выполнения возврата после восстановления" устанавливается атрибут POL и для группы ресурсов выполняется возврат на этот узел, пока атрибут POL не будет удален.
При перемещении подключенной группы ресурсов на другой узел предлагаются следующие варианты:
- Список узлов (Node list). Узел, на который следует переместить группу ресурсов. Этот узел будет задан в качестве атрибута POL.
- Восстановление порядка приоритетов узлов (Restore node priority order). Группа ресурсов перемещается на узел с наивысшим приоритетом, и атрибут POL не устанавливается.
- Эта информация хранится в файле /usr/es/sbin/cluster/etc/clpol на каждом узле в кластере.
Зависимости групп ресурсов (resource group dependencies)
Может быть задано сочетание двух типов зависимостей групп ресурсов:
Отношения "родительский объект / дочерний объект" между группами ресурсов предназначены для многоуровневых приложений, где одна или несколько групп ресурсов не могут быть успешно запущены, пока определенная группа ресурсов не станет активной. При определении отношения "родительский объект/дочерний объект" родительская группа ресурсов должна быть подключена до подключения любой дочерней группы ресурсов на каком-либо узле. При необходимости отключения родительской группы ресурсов сначала нужно отключить дочерние группы.
Может быть задано до трех уровней зависимости, т. е. родительская группа ресурсов может иметь дочерние группы ресурсов, которые, в свою очередь, являются родительскими объектами по отношению к другим группам ресурсов. Однако циклические зависимости не допускаются.
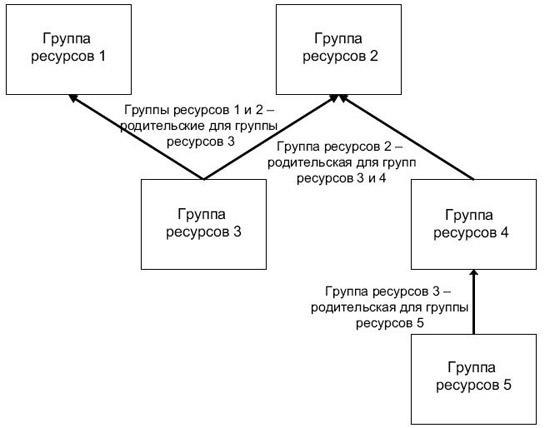
рис. 2.24 иллюстрирует пример, где группа ресурсов 2 имеет две дочерние группы ресурсов, одна из которых также имеет свою дочернюю группу ресурсов. Таким образом, группа ресурсов 2 должна быть подключена прежде, чем можно будет подключить группы ресурсов 3 и 4. Подобным образом группа ресурсов 4 должна быть подключена прежде, чем можно будет подключить группу ресурсов 5. Группа ресурсов 3 имеет две родительские группы ресурсов (1 и 2), которые должны быть подключены прежде, чем можно будет ее подключить.
Так как HACMP запускает приложения в фоновом режиме (при этом зависание скрипта не останавливает работу HACMP), важно, чтобы работали мониторы запуска приложений для родительских групп ресурсов в каждой зависимости "родительский объект/дочерний объект". Как только монитор (или мониторы) запуска приложения подтвердят успешный запуск приложения, можно будет начинать обработку дочерних групп ресурсов.
В группах ресурсов HACMP 5.3 также могут быть определены зависимости расположения. Возможны следующие варианты:
- Подключение на том же узле (online on same node): Для заданных групп ресурсов запуск, перемещение при сбое и возврат после восстановления всегда осуществляются на одном и том же узле, т. е. узлы осуществляют перемещение набора групп. Группа ресурсов с зависимостью может быть подключена только на том узле, на котором уже подключены другие группы ресурсов из того же набора, если только она не является первой подключаемой группой ресурсов в наборе.
- Подключение на разных узлах (online on different nodes). Для заданных групп ресурсов запуск, перемещение при сбое и возврат после восстановления осуществляются на разных узлах. Группам ресурсов назначается приоритет, так что группы ресурсов с более высоким приоритетом обслуживаются первыми и сохраняются в подключенном состоянии при ограниченном количестве узлов. Группы ресурсов с низким приоритетом отключаются, если группа ресурсов с более высоким приоритетом не имеет узла. Группы ресурсов со средним приоритетом не отключаются. Группа ресурсов с такой зависимостью может быть подключена только на узле, на котором не подключены другие группы ресурсов, являющиеся частью этой зависимости.
- Подключение на том же сайте (online on same site). Заданные группы ресурсов всегда подключаются на одном и том же сайте.
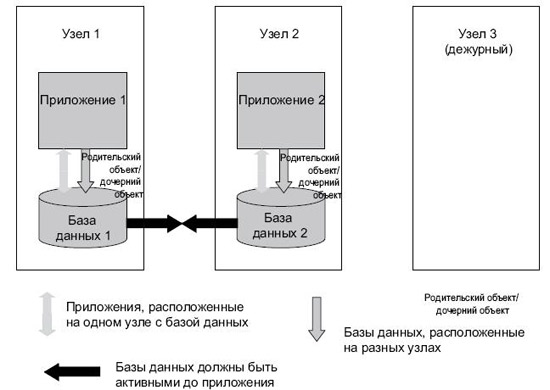
Группа ресурсов с этой зависимостью может быть подключена только на том же сайте, на котором уже подключены другие группы ресурсов с этой зависимостью, если только она не является первой подключаемой группой ресурсов с этой зависимостью. На рис. 2.25 представлен пример кластера из трех узлов с двумя базами данных и двумя приложениями. Приложения не могут быть запущены до подключения баз данных, поэтому устанавливается зависимость "родительский объект/дочерний объект".
В целях производительности базы данных должны располагаться на разных узлах, а приложения должны располагаться на одних узлах с базами данных, поэтому устанавливаются зависимости расположения.
Для установки или вывода зависимостей групп ресурсов можно воспользоваться командой clrgdependency, как показано в примере 2.2.
odin:># clrgdepdency -t [PARENT_CHILD | NODECOLLOCATION | ANTICOLLOCATION | SITECOLLOCATION ] -sl odin:># clrgdepdency -t PARENT_CHILD -sl #Parent Child rg1 rg2 rg1 rg3 odin:># clrgdepdency -t NODECOLLOCATION -sl odin:># clrgdepdency -t ANTILOCATION -sl #HIGH:INTERMEDIATE:LOW rg01::rg03frigg odin:># clrgdepdency -t SITECOLLOCATION -sl rg01 rg03 friggПример 2.2. Изменение и проверка зависимостей групп ресурсов
Другой способ проверки состоит в использовании команды odmget HACMPrg_ loc_dependency.
Управление группой ресурсов
Для групп ресурсов могут выполняться следующие операции:
- Подключение (online). Группа ресурсов может быть подключена на узле из списка узлов группы ресурсов. Группа ресурсов должна быть до этого отключена, если она не является группой ресурсов, подключаемой на всех доступных узлах.
- Отключение (offline). Группа ресурсов может быть отключена на определенном узле.
- Перемещение на другой узел с подключением. Группа ресурсов, являющаяся подключенной на одном узле, может быть отключена и перемещена на другой узел из списка узлов группы ресурсов и подключена. Это может включать и перемещение группы ресурсов на другой сайт.
Атрибут (priority override location) устанавливается в соответствии с приведенным выше описанием.
Некоторые изменения являются недопустимыми:
- родительская группа ресурсов не может быть отключена или перемещена, если существует дочерняя группа ресурсов в подключенном состоянии;
- дочерняя группа ресурсов не может быть запущена, пока не будет подключена родительская группа ресурсов.
Состояния групп ресурсов
В HACMP 5x способ обработки отказов групп ресурсов был изменен и, по сути, вмешательство оператора не всегда является обязательным.
Если узел при подключении к кластеру не может перевести группу ресурсов в подключенное состояние, группа ресурсов остается в ошибочном состоянии (ERROR). При возникновении отказа, если группа ресурсов не настроена на подключение на всех доступных узлах, HACMP попытается перевести группу ресурсов в подключенное состояние на другом активном узле из списка узлов группы ресурсов.
Начиная с HACMP 5.2 каждый узел, подключаемый к кластеру, автоматически пытается подключить все группы ресурсов, находящиеся в ошибочном состоянии.
Если узлу не удалось выполнить "подхват" группы ресурсов во время перемещения при сбое, группа ресурсов помечается как "восстанавливаемая" (recoverable), и HACMP попытается подключить группу ресурсов на других узлах из списка узлов группы ресурсов. Если это не удается сделать на всех узлах, группа ресурсов остается в ошибочном состоянии.
При отказе сети на определенном узле HACMP определяет, какие группы ресурсов были затронуты (которые имели сервисные IP-метки в этой сети), после чего пытается выполнить подключение на другом узле. В случае отсутствия узлов с требуемыми сетевыми ресурсами группы ресурсов остаются в ошибочном состоянии. Если какие-либо интерфейсы становятся доступными, HACMP решает, какие группы ресурсов в ошибочном состоянии могут быть подключены, после чего пытается их подключить.
Совет. Если требуется отменить автоматический режим подключения группы ресурсов в ошибочном состоянии, нужно указать, что она должна оставаться отключенной на узле, установив для нее POL.
Выборочные перемещения при сбое (selective fallovers)
- Отказ интерфейса. Если возможно, HACMP заменяет интерфейсы; в противном случае выполняется перемещение группы ресурсов на узел с наивысшим приоритетом с доступным интерфейсом, и в случае неуспешного перемещения группа ресурсов переводится в ошибочное состояние.
- Отказ сети:
- локальный – перемещение затронутых групп ресурсов на другой узел;
- глобальный – вызов события node_down для всех узлов.
- Отказ приложения. Если монитор приложения указывает на отказ приложения, то в зависимости от конфигурации HACMP попытается сначала перезапустить приложение на том же узле (обычно выполняется три попытки), затем, если попытки были неудачными, HACMP перемещает группу ресурсов на другой узел, и, если это тоже не удается, группа ресурсов переводится в ошибочное состояние.
- Отказ коммуникационного канала:
- HACMP пытается переместить группу ресурсов на другой узел;
- если настроено выборочное перемещение при сбое для группы томов при возникновении ошибки "LVM_SA_QUORCLOSE", то HACMP пытается переместить затрагиваемые группы ресурсов на другой узел.