|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 17:
SQL в хранилищах данных: аналитическая обработка данных
Функция ROW_NUMBER
Функция ROW_NUMBER() назначает уникальный номер (последовательно, начиная с 1, в порядке, определенном ORDER BY ) каждой строке в секции.
Синтаксис:
ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
<partition_by_clause> делит результирующий набор, полученный по предложению FROM.
<order_by_clause> определяет порядок, в котором значение функции ROW_NUMBER назначается строкам в секции. Целое число не может представлять столбец, если аргумент <order_by_clause> используется в ранжирующей функции.
Предложение ORDER BY определяет последовательность, в которой строкам назначаются уникальные номера с помощью функции ROW_NUMBER в пределах указанной секции.
Пример 23.8. Использование функции ROW_NUMBER ()
Пусть нам нужно провести группировку проданных товаров по объему продаж, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT p_productkey, s_amount,
ROW_NUMBER() (ORDER BY s_amount DESC) AS srnum
FROM product, sales
WHERE product.p_productkey = sales.p_productkey;Результат выполнения запроса приведен ниже.
Вывод 8.
| P_PRODUCTKEY | S_AMOUNT | SRNUM |
|---|---|---|
| Ботинки | 100 | 1 |
| Жакеты | 90 | 2 |
| Рубашки | 89 | 3 |
| Футболки | 84 | 4 |
| Свитеры | 75 | 5 |
| Джинсы | 75 | 6 |
| Ремни | 75 | 7 |
| Брюки | 69 | 8 |
| Ленты | 56 | 9 |
| Носки | 45 | 10 |
| Костюмы | NULL | 11 |
Свитерам, джинсам и ремням (с s_amount = 75) назначаются различные номера строк (5, 6, 7).
Подобно функции NTILE(), функция ROW_NUMBER() является недетерминистической функцией, так что "свитеры" мог бы получить номер строки 7 (вместо 5), а "ремни" — 5 (вместо 7). Чтобы избежать подобных ситуаций, необходимо сортировать результирующее множество по уникальному ключу.
Функции, генерирующие отчеты
После того как запрос выполнен, значения агрегатов (типа количество строк в результирующем множестве или среднее значение в колонке) могут быть вычислены для секции и быть доступными для других отчетов. Агрегатные функции генерирования отчетов (Reporting aggregate functions) возвращают значения агрегатов для каждой строки в секции. К агрегатным функциям генерирования отчетов относятся функции SUM(), AVG(), MAX(), MIN(), COUNT(), использующее предложение OVER. Их поведение относительно NULL-значений такое же, как и в агрегатных функциях SQL.
В предыдущих разделах настоящей лекции мы уже обсуждали такое применение агрегатных функций. Поэтому в настоящем разделе приведем только несколько примеров.
Функции генерирования отчетов допустимы только для предложений SELECT. Основное их назначение состоит в способности выполнять многократный разбор блока данных результирующего множества запроса. Запросы типа "Подсчитать число продавцов, у которых уровень продаж больше на 10% от числа продаж по городу" не требуют соединений между отдельными блоками запроса.
Пример 23.9. Использование агрегатных функций для генерирования отчетов
Пусть нам нужно для каждого товара найти регион, в котором наблюдается максимальный уровень продаж каждого товара, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT s_productkey, s_regionkey, sum_s_amount
FROM
(SELECT p_productkey, r_regionkey, SUM(s_amount) AS 'sum_s_amount',
MAX(SUM(s_amount)) OVER
(PARTITION BY p_productkey) AS 'max_sum_s_amount'
FROM sales
GROUP BY p_productkey, r_regionkey)
WHERE sum_s_amount = max_sum_s_amount;Данные внутреннего запроса к таблице фактов "Продажи" (sales), сгруппированные по колонкам p_productkey и p_regionkey, агрегируются для первых трех колонок, и функция MAX(SUM(s_amount)) возвращает результат.
Вывод 9.
| P_PRODUCTKEY | S_REGIONKEY | SUM_S_AMOUNT | MAX_SUM_S_AMOUNT |
|---|---|---|---|
| Жакеты | Запад | 99 | 99 |
| Жакеты | Восток | 50 | 99 |
| Брюки | Восток | 20 | 45 |
| Брюки | Запад | 45 | 45 |
| Рубашки | Восток | 60 | 80 |
| Рубашки | Запад | 80 | 80 |
| Ботинки | Запад | 100 | 130 |
| Ботинки | Восток | 130 | 130 |
| Свитеры | Запад | 75 | 75 |
| Свитеры | Восток | 75 | 75 |
| Носки | Восток | 95 | 95 |
| Носки | Запад | 66 | 95 |
Результат выполнения внешнего запроса приведен ниже.
Вывод 10.
| P_PRODUCTKEY | S_REGIONKEY | SUM_S_AMOUNT |
|---|---|---|
| Жакеты | Запад | 99 |
| Брюки | Запад | 45 |
| Рубашки | Запад | 80 |
| Ботинки | Восток | 130 |
| Свитеры | Запад | 75 |
| Свитеры | Восток | 75 |
| Носки | Восток | 95 |
Пример 23.10. Использование агрегирующих и ранжирующих функций для генерации отчета.
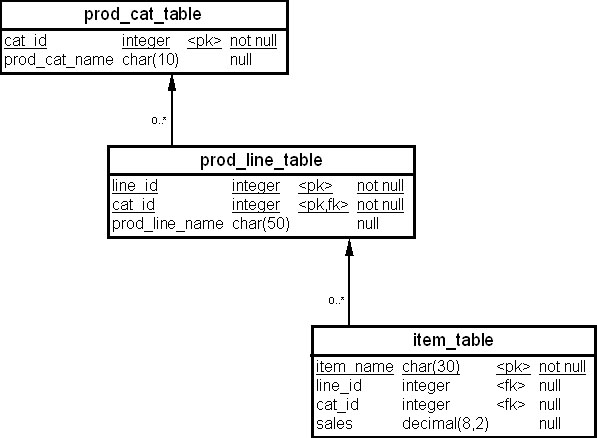
Более сложным является пример вычисления первых 10-ти (top 10) продаж той линейки товаров, которая имеет вклад более 10% в продажи товаров этой категории. Физическая схема для таблиц, используемых для решения этой задачи, приведена на рис. 23.6. Первая колонка является ключом для всех таблиц запроса.
SELECT *
FROM (
SELECT item_name, prod_line_name, prod_cat_name,
SUM(sales) OVER (PARTITION BY prod_cat_table.cat_id) cat_sales,
SUM(sales) OVER (PARTITION BY prod_line_table.line_id) line_sales,
RANK(sales) OVER (PARTITION BY prod_line_table.line_id
ORDER BY sales DESC) rnk
FROM item_table, prod_line_table, prod_cat_table
WHERE item_table.line_id = prod_line_table.line_id AND
prod_line_table.cat_id = prod_cat_table.cat_id
)
WHERE line_sales > 0.1 * cat_sales AND rnk <= 10;
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|