
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 15:
Создание физической модели базы данных: проектирование производительности
Аннотация: В настоящей лекции рассматриваются вопросы проектирования для обеспечения требуемого уровня производительности физической структуры хранилища данных на основе СУБД-ориентированных средств: индексов, секций, кластеров.
Ключевые слова: индексирование, индексы, секционирование, секционирование индексов, секционирование представлений, кластеризация, индексный кластер, хеш-кластер, секционирование таблиц, кластер, физические модели данных, денормализация, производительность, СУБД, ключевые поля или ключи, администратор БД, tree structure, leaf, индекс со структурой B-Tree, составной ключ, кластеризованные индексы, некластеризованные индексы, кластерный ключ или ключ кластеризации, исключительно индексные таблицы, индексированная таблица, табличное пространство, битовые индексы, индексы с обращением ключа, индексы на основе значения функций, database engineering, checksumming, кардинальность колонки, cardinality, фактор селективности выборки, фактор селективности, поддержка ссылочной целостности, дочерняя таблица, ограничение первичного ключа, разбиение таблиц, секция таблицы, ключ секционирования, секционирование по диапазону, хеш-секционирование, составное секционирование, tablespace, параллельная обработка данных, функция секционирования, схема секционирования, оптимизатор запросов, LOC, механизмы, место, таблица, операции
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- основные типы индексирования объектов базы данных;
- основные приемы повышения производительности с помощью подключения индекса ;
- основные типы индексов реляционных баз данных;
- достоинства и недостатки индексирования ;
- что такое секционирование таблиц;
- что такое секционирование индексов ;
- что такое секционирование представлений ;
- достоинства и недостатки секционирования ;
- что такое кластеризация ;
- что такое индексный кластер и хеш-кластер ;
- какие достоинства и недостатки имеет кластеризация ;
и научитесь:
- создавать различные типы индексов ;
- создавать секционированные таблицы;
- создавать секционированные индексы ;
- создавать секционированные представления;
- создавать кластеры.
Литература: [2], [3], [37], [67].
Введение
Как уже отмечалось в предыдущей лекции, одной из важнейших задач разработки физической модели данных ХД является обеспечение гарантии того, что ХД обеспечивает требуемый уровень производительности. В той же лекции мы рассмотрели основной подход к решению этой задачи — денормализацию таблиц физической модели данных ХД в рамках подхода реляционной модели. В настоящей лекции мы продолжим обсуждать методы борьбы за производительность ХД и сконцентрируем свое внимание на СУБД-ориентированных средствах для решения этой задачи: индексах, секциях, кластерах.
Повышение производительности запросов: индексы
Индексирование
Индексирование (indexing) — это способ обеспечения быстрого доступа к значениям колонки или комбинации колонок. Физически новые строки добавляются в конец таблицы, результатом чего становится неупорядоченное размещение значений в колонках. Без использования каких-либо методов упорядочения данных единственным способом просмотра значения колонки со стороны СУБД является последовательный просмотр каждой строки от начала таблицы к ее концу — так называемое сканирование таблицы. Производительность такого сканирования пропорциональна размеру таблицы, размеру физической страницы БД и длине строки таблицы.
Одним из способов внесения отношения порядка в значения колонок без нарушения физического расположения строк таблицы является создание объекта реляционной СУБД — индекса (index). Индекс — это объект в реляционной БД, который предназначен для организации быстрого доступа к строкам таблицы по значениям одной или более колонок этих строк.
Концептуально действие индекса состоит в следующем. В индексе содержатся упорядоченный список значений колонки или комбинации колонок, а также сведения о местонахождении на жестком диске соответствующих этим значениям строк таблицы. Значения колонки в индексе упорядочены. Несмотря на то, что порядок строк в таблице случаен, индекс можно быстро просмотреть, чтобы найти конкретное значение. Упорядоченный индекс можно просмотреть во много раз быстрее, чем неупорядоченную таблицу. Чем выше степень различия значений ключа в колонке, тем быстрее будет выполняться доступ к строкам этой таблицы.
Так, при вставке новой записи в таблицу проверка уникальности первичного ключа реализуется не реальным просмотром таблицы БД, а тем, что требование уникальности предъявляется к значениям колонки первичного ключа в индексе. Таким образом, индекс — это объект базы данных, который может существенно сократить время поиска нужных строк в таблице.
Индексы занимают место в БД. При вводе новых данных или удалении данных СУБД приходится обновлять и таблицы, и индексы. Это может замедлить выполнение операций модификации данных, особенно для таблиц с большим числом строк, как в ХД. Таким образом, может появиться проблема, суть которой состоит в возникновении конфликта между скоростью обновления данных в таблице и скоростью ее считываний. При разрешении этой проблемы следует придерживаться следующего эмпирического правила: создавать индексы для колонок первичных ключей и других колонок, часто используемых в тех запросах, в которых для выборки данных применяются логические критерии. Если в результате скорость обновления данных ухудшается, то можно рассмотреть вопрос об удалении некоторых индексов.
Каждая таблица БД может иметь один или несколько индексов. Индексы создаются по одной колонке или нескольким колонкам таблицы. Колонки, входящие в индекс, принято называть ключевыми полями (key fields), или ключами. Индексы могут быть уникальными и неуникальными. Уникальность индекса означает, что не существует двух строк с одним и тем же значением ключа индекса. Неуникальный индекс может иметь несколько ключей с одинаковыми значениями.
Основными целями создания индексов в БД являются:
- ускорение поиска строк в таблицах;
- обеспечение уникального значения в колонках;
- извлечение строк в заданном порядке на основании значений индексированных колонок (что оправдано только для очень больших таблиц, когда использование предложения ORDER ухудшает производительность).
На этапе создания физической модели данных ХД необходимо принять ряд важных решений о том, что и как индексировать; при этом важно четко сформулировать правила индексирования. Для каждого ИТ-проекта с ХД необходимо создать и оформить в письменном виде правила индексирования как часть общих правил обеспечения производительности. Поддержка и сопровождение индексов в процессе эксплуатации ХД является в основном задачей администратора БД. Решая задачи обеспечения производительности, администратор БД будет ставить вопрос о перепроектировании ее физической структуры (обратные задачи проектирования), в том числе и вопрос об удалении и создании новых индексов. Он может решать эти задачи самостоятельно. Тем более важно знать, по каким правилам и из каких соображений создавались индексы того или иного типа. Разработка таких правил значительно повысит качество эксплуатации ХД с точки зрения обеспечения ее производительности.
Чтобы решать эти задачи, проектировщик должен знать, как работает индекс, какие типы индексов поддерживает СУБД, и понимать смысл методов индексирования.
Сначала мы опишем типы индексов вместе с методами индексирования для каждого типа, затем разберем вопрос о том, как работает индекс, и в заключение дадим некоторые рекомендации по созданию и использованию индексов.
Индекс со структурой B-Tree
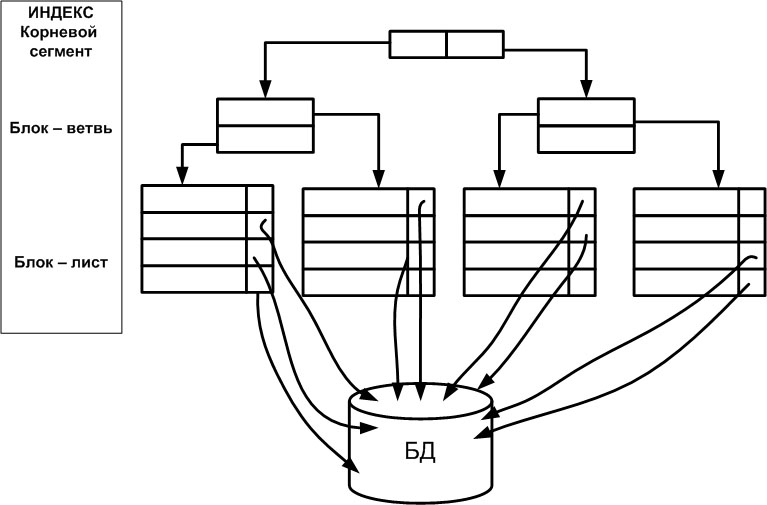
Индекс на основе сбалансированной иерархической структуры (или индекс B-Tree, balanced tree structured object) напоминает дерево, если смотреть на него снизу вверх. При работе СУБД с этой структурой сначала считывается самый верхний блок — корневой узел (root), затем блок на следующем уровне — блок-ветвь (branch), и так далее, до тех пор, пока не будет извлечен блок-лист (leaf) с индексируемыми колонками (колонкой) строки. Обратим внимание, что значения индексируемых колонок сохраняется в индексе ( рис. 20.1).
Такая структура позволяет сократить до минимума число операций ввода-вывода. Для получения индексируемых колонок строки обычно требуется одно посещение блока-листа, т.е. физической страницы файловой структуры БД, отведенной под индекс.
Следует отметить два случая, когда после выборки индексируемых колонок строки из индекса может понадобиться несколько посещений физической страницы индекса:
- когда строка имеет длину более одной физической страницы файловой структуры БД — так называемая расщепленная строка ;
- когда строка за время своего существования в БД увеличилась и была перемещена из исходной страницы в другую страницу — так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе – высотой (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree — это физический объект реляционной БД, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree.
- Количество операций ввода-вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавления новых данных СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.
- Корневой узел и узлы — ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений. Узлы-листья содержат полное значение ключа.
- Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
- Индекс можно использовать для поиска как точного соответствия, так и диапазона значений.
- Индексы могут быть построены для нескольких колонок таблицы — так называемый составной индекс. СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа. Например, составной индекс {"Фамилия" (Ename), "Должность" (Job)} для обработки запроса SELECT * FROM EMPLOYEE WHERE Job='Инженер'; применяться не будет.
- СУБД обычно сама принимает решение, использовать индекс или нет.
- Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться применять его в некоторых операциях, например, ORDER BY.
В СУБД семейства MS SQL Server все индексы организованы на основе сбалансированной иерархической структуры. Помимо того, что индексы обладают свойствами уникальности ( UNIQUE ) и неуникальности, индексы в СУБД семейства MS SQL Server могут быть кластеризованными ( CLUSTERED ) или некластеризованными ( NONCLUSTERED ), являющимися индексами по умолчанию.
Кластеризованный индекс – это индекс, в котором логический порядок значений ключа определяет физический порядок соответствующих строк в таблице. На нижнем (конечном) уровне такого индекса хранятся действительные строки данных таблицы. Для таблицы или представления в каждый момент времени может существовать только один кластеризованный индекс.
Некластеризованный индекс – это индекс, в котором задается логическое упорядочение для таблицы. Логический порядок строк в некластеризованном индексе не влияет на их физический порядок. Для каждой таблицы можно создать до 999 некластеризованных индексов, независимо от того, каким образом они создаются: неявно, с помощью ограничений PRIMARY KEY и UNIQUE, или явно, с помощью команды CREATE INDEX, которая была рассмотрена в "Знакомство с CASE инструментом" .
В кластеризованном индексе конечные узлы содержат страницы данных базовой таблицы. На страницах индекса корневого и промежуточного узлов находятся строки индекса. Каждая строка индекса содержит ключевое значение и указатель либо на страницу промежуточного уровня сбалансированного дерева, либо на строку данных на конечном уровне индекса. Страницы на каждом уровне связаны в двунаправленный список.
По умолчанию кластеризованный индекс занимает одну секцию на дисковом пространстве. Если кластеризованный индекс занимает несколько секций, каждая секция включает сбалансированное дерево, содержащее данные этой секции. Например, если кластеризованный индекс занимает четыре секции, существует четыре сбалансированных дерева: по одному в каждой секции.
SQL Server движется вниз по индексу, чтобы найти строку, соответствующую ключу кластеризованного индекса. Чтобы найти диапазон ключей, SQL Server сначала находит начальное значение ключа в диапазоне, а затем сканирует страницы данных, используя указатели на следующую и предыдущую страницу. Чтобы найти первую страницу в цепочке страниц данных, SQL Server движется по самым левым указателям от корня индекса.
В зависимости от типов данных каждая структура кластеризованного индекса состоит из одной или более единиц распределения, которые применяются для хранения и управления данными секциями. Для каждой секции кластеризованный индекс содержит как минимум одну единицу распределения IN_ROW_DATA. Для хранения столбцов больших объектов ( LOB ) кластеризованному индексу требуется одна единица распределения LOB_DATA для каждой секции. Кроме того, для хранения строк переменной длины, которые превышают ограничение на размер строки, равное 8 060 байтам, для каждой секции требуется одна единица распределения ROW_OVERFLOW_DATA.
По своей организации некластеризованные индексы отличаются от кластеризованных следующим: строки данных в базовой таблице не сортируются и хранятся в порядке, который основан на их некластеризованных ключах; конечный уровень некластеризованного индекса состоит из страниц индекса вместо страниц данных.
Некластеризованные индексы могут определяться на таблице или представлении с кластеризованным индексом либо на куче. Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение.
Указатели строк на строках некластеризованных индексов являются либо указателем на строку, либо ключом кластеризованного индекса для строки, как описано ниже.
Если таблица является кучей (то есть не содержит кластеризованный индекс ), то указатель строки является указателем на строку. Указатель строится на основе идентификатора файла ( ID ), номера страницы и номера строки на странице. Весь указатель целиком называется идентификатором строки ( RID ).
Если для таблицы имеется кластеризованный индекс или индекс построен на индексированном представлении, то указатель строки — это ключ кластеризованного индекса для строки. Если кластеризованный индекс не является уникальным индексом, то SQL Server создает все имеющиеся повторяющиеся ключи уникальными путем добавления внутри созданного значения, называемого uniqueifier. Это четырехбайтовое значение невидимо для пользователей. Оно применяется тогда, когда необходимо сделать кластеризованный ключ уникальным, чтобы использовать в некластеризованных индексах. SQL Server получает строку данных путем поиска по кластеризованному индексу, задействуя ключ кластеризованного индекса, который хранится в конечной строке некластеризованного индекса.
По умолчанию некластеризованный индекс включает одну секцию. Если он состоит из нескольких секций, то каждая секция имеет структуру сбалансированного дерева, в которой содержатся индексные строки для данной конкретной секции. Например, если некластеризованный индекс содержит четыре секции, то существуют четыре структуры сбалансированного дерева, по одной на каждую секцию.
В зависимости от типов данных в некластеризованном индексе каждая его структура будет содержать одну или более единиц распределения, в которых хранятся данные для определенной секции. Каждый некластеризованный индекс будет иметь по меньшей мере одну единицу распределения IN_ROW_DATA на секцию, в которой хранятся страницы сбалансированного дерева индекса. Некластеризованный индекс будет также содержать одну единицу распределения LOB_DATA на секцию, если в индексе есть столбцы типа большого объекта (LOB). Кроме того, некластеризованный индекс будет включать одну единицу распределения ROW_OVERFLOW_DATA на секцию, если в индексе имеются столбцы переменной длины, в которых превышается максимальный размер строки, равный 8 060 байт.
Пример 20.1.
Далее в примерах, если не оговорено особо, мы будем использовать таблицу "Служащий" (EMPLOYEE) ( рис. 20.2) из "Проектирования модели ХД по логической модели" . Повторим ее здесь.
| № | Наименование атрибута | Наименование колонки |
|---|---|---|
| 1 | Номер личной карточки | EMPNO (PK) |
| 2 | Фамилия | ENAME |
| 3 | Имя | LNAME |
| 4 | Номер подразделения | DEPNO |
| 5 | Должность | JOB |
| 6 | Дата рождения | AGE |
| 7 | Стаж | HIREDATE |
| 8 | Доплаты | COMM |
| 9 | Зарплата | SAL |
| 10 | Штрафы | FINE |
| 11 | Автобиография | Biog |
| 12 | Фотография | Foto |
Создадим для таблицы "Служащий" (EMPLOYEE) составной индекс по колонкам "Фамилия" (Ename) и "Должность" (Job).
CREATE INDEX emp_ndx2 ON EMPLOYEE (Ename, Job) GO
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|