Инспектор
Вы можете этот курс.
Опубликован: 02.08.2007 | Уровень: специалист | Доступ: платный
Лекция 10:
Создание физической модели базы данных. Учет влияния транзакций
Денормализация
Понятие о денормализации
Начиная с этого раздела мы переходим к рассмотрению методик настройки физической структуры реляционной базы данных с целью удовлетворения требования к производительности базы данных. Эти методики представляют собой набор рекомендаций и эвристических правил по изменению физической структуры базы данных, которая была получена проектировщиком базы данных в результате создания первой итерации физической модели базы данных. Ясно, что использование этих методик носит опциональный характер.
В этом разделе будут описаны различные типы денормализации и методы реализации этого процесса. Кроме того, мы рассмотрим, как использовать для поддержки денормализации триггеры и как обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования модуля. Другими словами, обычно нельзя принять решение о денормализации на основании одной только модели данных. Когда проектировщик принимает решение о денормализации, то должен господствовать здравый смысл. Обычно стараются найти в приложении базы данных критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы обычно определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Если проектировщик базы данных прописал все транзакции базы данных, то он, вероятно, сможет определить наличие таких критических процессов.
Замечание. Использовать денормализацию только для упрощения SQL-запросов при обращении к базе данных является неправильным решением. Если вы хотите упростить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Чтобы повысить производительность запроса, можно ввести индексы. Как оптимизировать запрос, будет рассмотрено в последней лекции этого курса.
Как правило, денормализация уменьшает время запроса за счет DML -операций. Денормализацию следует рассматривать как расширение нормализованной модели данных, которое повысит производительность запросов. При принятии решения о денормализации определите, что является наиболее важным для приложения - избыточность данных или высокая производительность. Если проектировщик базы данных ведет журнал проектирования (некоторый внутренний документ произвольной формы, в котором фиксируются все принятые в процессе проектирования базы данных решения), то в него необходимо занести обоснованное решение о денормализации. Помните, что кроме денормализации существуют и другие пути повышения производительности. Денормализацию таблиц можно выполнять как на уровне логической модели данных, так и на уровне физической модели.
Нисходящая денормализация
Рассмотрим принципы денормализации на уровне логической модели реляционной базы данных. Нисходящая денормализация предлагает перенос атрибута из одной (родительской) сущности в подчиненную (дочернюю) сущность. Из рисунков 10.1 и 10.2 видно, что в денормализованной логической модели мы переместили фамилию клиента из сущности Customer (Клиент) в сущность Order (Заказ). Что дает введение избыточности (перенос атрибута) в данном случае? Единственный выигрыш заключается в том, что мы исключаем операцию соединения, если захотим вместе с заказом увидеть фамилию клиента.
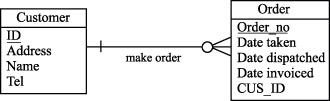
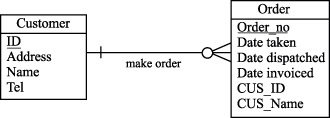
Таким образом, нисходящая денормализация - это процесс введения избыточных колонок в подчиненных таблицах с целью устранения операций соединения.
Однако устранение соединений посредством нисходящей денормализации редко оправдывает затраты на сопровождение дублирующей колонки в таблице ORDER. Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений, дающих небольшую реальную выгоду. Например, если клиент меняет фамилию, то нам приходится обновлять все заказы, чтобы отразить это изменение. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены или закрыты? Если бы не была проведена денормализация, то эти вопросы никогда бы и не возникли.
Нисходящая денормализация оправдана лишь в приложениях, где необходимо устранять операции соединения таблиц. Это имеет место в базах данных большого объема, таких как хранилища данных. При этом проблемы с каскадными обновлениями не возникает потому, что данные в хранилищах данных - архивные.
Восходящая денормализация
Восходящая денормализация предлагает перенос атрибута из подчиненной (дочерней) сущности в родительскую сущность, обычно в форме итоговых данных. На рисунках 10.3 и 10.4 показано, как это можно сделать для сущностей Order и Order Item (Позиция заказа).
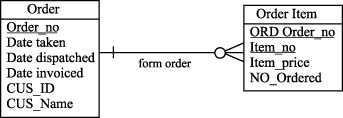
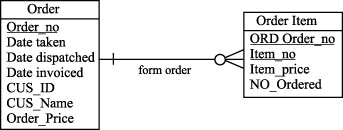
Например, если в вычисление общей суммы заказа в системы обработки заказов (суммирование колонок Item_Price в таблице Order Item ) приводит к снижению производительности, то мы можем повысить производительность этой операции, поместив сумму заказа в избыточном столбце таблицы ORDER. В нашем примере в избыточном столбце хранится сумма значений, но эти приемы применимы к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Таким образом, восходящая денормализация - это процесс введения избыточных колонок в родительских таблицах с целью устранения операций соединения с операциями агрегирования.
Чтобы представить последствия введения денормализации, рассмотрим процедуру сопровождения денормализованных таблиц Order и Order Item, которые сводятся к поддержке следующих бизнес-правил:
- Когда в таблицу Order Item добавляется новая строка, то цена заказа (колонка Order_Price ) в таблице Order увеличивается на цену новой позиции заказа (Item_Price).
- Когда строка удаляется из таблицы Order Item, то цена заказа в таблице Order уменьшается на цену старой позиции заказа (Item_Price).
- Когда изменяется цена в таблице Order Item, то цена заказа в таблице Order должна быть откорректирована на разницу между старой и новой ценами позиции заказа (Item_Price).
Поддержка перечисленных выше бизнес-правил создает дополнительную нагрузку на процессы, выполняющие DML -операции в таблице Order Item. Это и есть цена, которую мы вынуждены заплатить за повышение производительности запросов.
Внутритабличная денормализация
Внутритабличная денормализация выполняется в пределах одной таблицы, т.е. это процесс введения избыточных колонок в одной таблице с целью увеличения производительности запроса строки по производному значению. Например, если строка содержит две числовых колонки, X и Y, то значение Z, равное произведению X и Y (Z = X*Y), легко вычислить во время выполнения. Однако предположим, что есть запросы, в которых необходимо осуществить поиск по Z (например, Z принадлежит диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z, и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым - увеличение времени загрузки, вызванное необходимостью постоянно пересчитывать Z, или увеличение времени сканирования, обусловленное удлинением строк таблицы за счет хранения дополнительной колонки.
Приведем еще один часто встречающийся пример внутритабличной нормализации. Допустим, что одинаковый текст хранится в двух видах: с символами в верхнем и в нижнем регистре - для отображения и ввода данных с символами в верхнем регистре. Это бывает необходимо для обеспечения работы ускоренных запросов без учета регистра.
Примечание. Обеспечить приемлемую производительность для таблиц умеренного размера (до 10000 строк) в последнем случае можно и без внутритабличной деномализации, переработав запрос с использованием встроенной функции UPPER.
Денормализация методом "разделяй и властвуй"
Денормализация методом "разделяй и властвуй" - это процесс разбиения нормализованной таблицы на две и более таблиц и создание между ними отношения "один к одному" с целью устранения дополнительных операций ввода/вывода или по техническим причинам.
Использование этого приема носит причины технического характера. Во многих СУБД таблица не может иметь больше одного столбца типа LONG или LONG RAW. Допустим, что у вас есть таблица Films и нужно сохранить и окончательный вариант фильма ( LONG ), и вариант, который отсняли с множеством дублей ( LONG RAW ). Из-за вышеупомянутого ограничения в одной таблице это сделать нельзя, поэтому один из кодов нужно разместить в отдельной таблице. Проектировщику базы данных не остается ничего другого как разбить таблицу на две.
Иногда лучше вынести столбец LONG в отдельную таблицу, даже если вышеупомянутое ограничение не действует. Рассмотрим таблицу, строки которой содержат в начале ключевые колонки, потом неключевые колонки, а в конце - колонку типа LONG. Предположим, что в большинстве строк столбец LONG содержит данные. Если нет индексов по неключевым столбцам, то при выполнении запросов по любому из этих столбцов СУБД обычно будет осуществлять полное сканирование таблицы. При этом из-за наличия в таблице столбца LONG понадобятся дополнительные операции ввода/вывода.
Чтобы устранить эту проблему, разделите таблицу так, как показано на рис. 10.5.

Во многих СУБД таблица не может иметь более 254 столбцов, и если предложить таблицу с большим числом столбцов, то также возникнет причина для разделения такой таблицы на две. Обычно такие таблицы могут понадобиться только в следующих случаях:
- приложение полностью проектируется на базе унаследованной системы, и каждая таблица строится как точная копия файла унаследованной системы. При этом наследуется и структура, и все реляционные свойства в ней отсутствуют;
- выполняется слияние двух таблиц путем формирования в одной из них повторяющейся группы;
- речь идет о хранилище данных, в котором принято решение выполнить массовую нисходящую денормализацию. В этом случае следует создавать таблицы с максимальным для СУБД числом столбцов, так как любое другое решение, вероятно, обусловит необходимость массовых соединений "один к одному".
Согласно мнению известного специалиста в области проектирования реляционных баз данных Д. Энсора, "Хорошей мерой степени нормализации является число столбцов на таблицу. Эмпирическое правило гласит, что очень немногие первичные ключи имеют более двадцати действительно зависимых от них атрибутов".