
| Россия, Москва |
Инспектор
Вы можете этот курс.
Опубликован: 13.09.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Лекция 15:
Нечеткие и гибридные нейронные сети
Модель Мамдани-Заде как универсальный аппроксиматор
Модели нечеткого вывода позволяют описать выходной сигнал многомерного
процесса как нелинейную функцию входных переменных 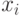 ,
, 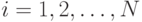 и
параметров нечеткой системы, например, при использовании в качестве
агрегатора оператора алгебраического произведения с последующей
дефазификацией относительно среднего центра. В модели Мамдани-Заде каждое
из
и
параметров нечеткой системы, например, при использовании в качестве
агрегатора оператора алгебраического произведения с последующей
дефазификацией относительно среднего центра. В модели Мамдани-Заде каждое
из 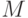 правил определяется уровнем активации условия
правил определяется уровнем активации условия
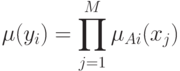
где  - значение
- значение 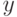 , при котором значение
, при котором значение 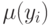 максимально. Пусть — центр
максимально. Пусть — центр 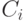 нечеткого множества заключения
нечеткого множества заключения  -го правила вывода. Тогда
дефазификация относительно среднего центра дает
-го правила вывода. Тогда
дефазификация относительно среднего центра дает
![\begin{align*}
y=(\sum_{i=1}^M C_i[\prod_{j=1}^N \mu_{Ai}(x_j)])/ \sum_{i=1}^M
\prod_{j=1}^N \mu_{Ai}(x_j)
\end{align*}](/sites/default/files/tex_cache/8ae04da64939f73024621c2c2aaacded.png)
Приведенные формулы модели Мамдани-Заде имеют модульную структуру, которая идеально подходит для системного представления в виде многослойной структуры, напоминающей структуру классических нейронных сетей. Такие сети мы будем называть нечеткими нейронными сетями. Характерной их особенностью является возможность использования нечетких правил вывода для расчета выходного сигнала. Обучение таких сетей сводится к расчету параметров функции фазификации.
Нечеткие сети TSK (Такаги-Сугено-Канга)
Схема вывода в модели TSK при использовании правил и 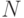 переменных
переменных 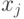 имеет вид
имеет вид 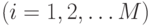
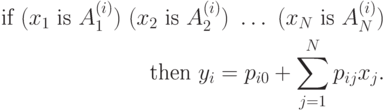
Условие 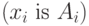 реализуется функцией фазификации
реализуется функцией фазификации
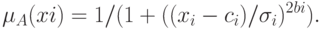
При правилах агрегированный выходной результат сети имеет вид
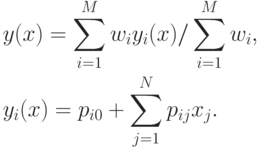 |
( 1) |
Веса 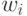 интерпретируются как значимость компонентов
интерпретируются как значимость компонентов 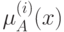 . Тогда
формуле (1) можно поставить в соответствие многослойную нейронную
сеть
рис. 3.
. Тогда
формуле (1) можно поставить в соответствие многослойную нейронную
сеть
рис. 3.
1. Первый слой выполняет фазификацию каждой переменной. Это
параметрический слой с параметрами 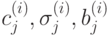 , подлежащими
адаптации в процессе обучения.
, подлежащими
адаптации в процессе обучения.
2. Второй слой выполняет агрегирование отдельных переменных, определяя
результирующее значение коэффициента принадлежности 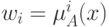 для
вектора
для
вектора  (непараметрический слой).
(непараметрический слой).
3. Третий слой - генератор функции TSK, рассчитывает значения
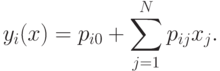
В этом слое также производится умножение 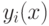 на , сформированные в
предыдущем слое. Здесь адаптации подлежат веса
на , сформированные в
предыдущем слое. Здесь адаптации подлежат веса  , определяющие функцию следствия модели TSK.
, определяющие функцию следствия модели TSK.
4. Четвертый слой составляют два нейрона-сумматора, один из которых
рассчитывает взвешенную сумму сигналов  , а второй - сумму
весов
, а второй - сумму
весов  (непараметрический слой).
(непараметрический слой).
5. Пятый слой из одного нейрона - это нормализующий слой, в котором выходной сигнал сети агрегируется по формуле (1).
Таким образом, в процессе обучения происходит уточнение параметров только первого (нелинейного) и третьего (линейного) слоев.