|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Самостоятельная работа 5: Оптимизация вычислений в задаче матричного умножения. Оптимизация работы с памятью
Реализация блочного алгоритма умножения матриц
Один из способов улучшения доступа к памяти при реализации алгоритма умножения матриц – применение блочных алгоритмов. При использовании блочных алгоритмов повышается локальность доступа к памяти. Как правило, при повышении локальности доступа к памяти повышается эффективность ее использования за счет уменьшения количества кеш-промахов.
Использование блока квадратной формы
Реализуем блочный алгоритм. В первой версии будем использовать два предположения – блоки квадратные и порядок матрицы делится на размер блока без остатка.
Для реализации изменим прототип функции умножения (добавим в параметры размер блока):
// multBloc.h
#ifndef _MULT_
#define _MULT_
#include "routine.h"
//умножение матриц
void mult(ELEMENT_TYPE * A, ELEMENT_TYPE * B,
ELEMENT_TYPE * C, int n, int bSize);
#endif
Частично изменим функцию main:
#include <stdio.h>
#include "omp.h"
#include "multBlock.h"
int testThreadCount();
int main(int argc, char **argv)
{
double time_s, time_f;
int mic_th;
int n = 0, blockSize = 1;
if(argc < 3)
{
printf("<exec> <n> <block Size>");
return -1;
}
n = atoi(argv[1]);
blockSize = atoi(argv[2]);
…
time_s = omp_get_wtime( );
mult(A, B, C, n, blockSize);
time_f = omp_get_wtime( );
…
return 0;
}
Реализуем функцию блочного умножения:
//singleBlock.cpp
#include "mult.h"
#include "assert.h"
void mult(ELEMENT_TYPE * A, ELEMENT_TYPE * B,
ELEMENT_TYPE * C, int n, int bSize)
{
ELEMENT_TYPE s, err;
int i, j, k, ik, jk, kk;
assert(n % bSize == 0);
for(j = 0; j < n; j++ )
{
for(i = 0; i < n; i++ )
{
C[j * n + i] = 0;
}
}
for(jk = 0; jk < n; jk+= bSize)
for(kk = 0; kk < n; kk+= bSize)
for(ik = 0; ik < n; ik+= bSize)
for(j = 0; j < bSize; j++ )
for(k = 0; k < bSize; k++ )
#pragma simd
for(i = 0; i < bSize; i++ )
C[(jk + j) * n + (ik + i)] +=
A[(jk + j) * n + (kk + k)] *
B[(kk + k) * n + (ik + i)];
}
Скомпилируем и запустим код. На рис. 10.7 представлен результат выполнения блочного алгоритма на сопроцессоре Intel Xeon Phi.

увеличить изображение
Рис. 10.7. Результат выполнения блочного алгоритма на сопроцессоре Intel Xeon Phi.
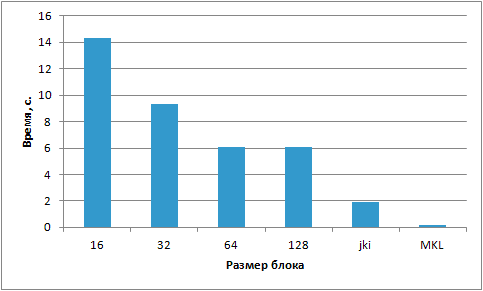
В таблице 10.7 приведены времена работы программной реализации блочного алгоритма при разных размерах блока:
| Размер блока: | 16 | 32 | 64 | 128 | jki | MKL seq. |
|---|---|---|---|---|---|---|
| N=1024 | 14,3 | 9,318 | 6,058 | 6,065 | 1,95 | 0,207 |
Из результатов экспериментов и рис. 10.8 видно, что блочный алгоритм вместо ускорения дал замедление.
В чем может быть причина?
Соберем отчет об оптимизации программы. Для этого можно использовать строку компиляции, представленную ниже:
icpc -mmic -mkl -openmp -opt-report=3 ./singleBlock.cpp ./mainBlock.cpp ./routine.cpp -osingleBlock
Далее приведена часть отчета об оптимизации:
… ./singleBlock.cpp(12:5-12:5):VEC:_Z4multPfS_S_ii: loop was not vectorized: loop was transformed to memset or memcpy ./singleBlock.cpp(10:3-10:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(29:13-29:13):VEC:_Z4multPfS_S_ii: LOOP WAS VECTORIZED loop skipped: multiversioned ./singleBlock.cpp(26:11-26:11):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(24:9-24:9):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(22:3-22:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(21:3-21:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(20:3-20:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 26=6 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 26=1 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 26=6, dist=6 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 29=8 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 29=6 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 29=8, dist=8 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 29=8 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 29=6 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 29=8, dist=8 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 29=4 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 29=2 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 29=4, dist=64
Из отчета видно, что компилятор добавил в код много вызовов программной предвыборки данных.
Для оптимизации работы с памятью компилятор использует программную предвыборку данных. При генерации кода компилятор заранее не знает, чему будут равны параметры, передаваемые в функцию. Из-за этого компилятор должен генерировать код, используя введенные в нем эвристики. Эвристики срабатывают не всегда. Например, компилятор мог предположить, что внутренний цикл имеет большую длину и соответствующим образам вставил предсказание загрузки данных в кэш-память. В нашем случае цикл имеет малый размер (сомнительно, что большие блоки больших размеров приведут к хорошей локальности при доступе к данным). Как следствие, в кэш-память загружается много не используемых данных, что негативно влияет на производительность.
Попробуем помочь компилятору, используя задание размера блока в виде константы. Заметим, что в результате подобных действий компилятор иногда может избавиться от короткого цикла, полностью развернув его и реализовав с использованием векторной арифметики.
const int bSize = 64;
Еще раз соберем отчет компилятора об оптимизации:
./singleBlock.cpp(15:5-15:5):VEC:_Z4multPfS_S_ii: loop was not vectorized: loop was transformed to memset or memcpy ./singleBlock.cpp(13:3-13:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(30:17-30:17):VEC:_Z4multPfS_S_ii: LOOP WAS VECTORIZED ./singleBlock.cpp(27:11-27:11):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(25:9-25:9):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(23:3-23:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(22:3-22:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop ./singleBlock.cpp(21:3-21:3):VEC:_Z4multPfS_S_ii: loop was not vectorized: not inner loop Estimate of max_trip_count of loop at line 27=128 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 27=2 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 27=2, dist=8 Estimate of max_trip_count of loop at line 30=4 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 30=4 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 30=6 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 30=4, dist=2 Estimate of max_trip_count of loop at line 30=4 Total #of lines prefetched in _Z4multPfS_S_ii for loop at line 30=4 # of initial-value prefetches in _Z4multPfS_S_ii for loop at line 30=6 # of dynamic_mapped_array prefetches in _Z4multPfS_S_ii for loop at line 30=4, dist=2 Using second-level distance 2 for prefetching dyn-map memory reference in stmt at line 30
Из отчета видно, что предсказания компилятора существенным образом поменялись. В частности предсказаний загрузки данных в кэш-память стало меньше, также изменились их параметры.
Попробуем замерить время вычислений при разных размерах блока, заданных при помощи константы и через параметр функции. В таблице 10.8 приведены результаты сравнения.
| Размер блока: | 16 | 32 | 64 | 128 | jki | MKL seq. |
|---|---|---|---|---|---|---|
| N=1024\ Размер блока\ параметр | 14,3 | 9,318 | 6,058 | 6,065 | 1,95 | 0,207 |
| N=1024\ Размер блока\ константа | 3,68 | 1,4 | 1,45 | 3,48 | 1,95 | 0,207 |
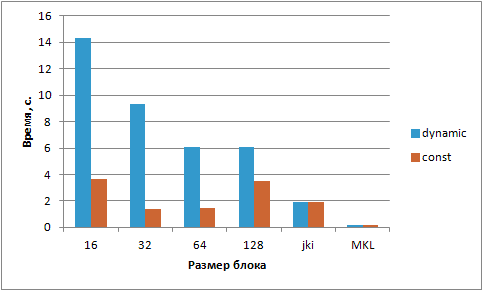
Рис. 10.9. Время работы алгоритма в зависимости от размера блока и типа его задания на Intel Xeon Phi
Из рис. 10.9 и таблицы 10.8 видно, что блочный алгоритм позволил уменьшить время вычислений. Время сократилось из-за уменьшения количества кэш-промахов.
Следует отметить, что вместо задания размера блока равного константе также можно попытаться использовать директивы компилятора, такие как #pragma loop_count, позволяющую компилятору подсказать информацию о характерных длинах цикла. Попробовать данные директивы предлагается самостоятельно.
В рассматриваемом примере приведены результаты только при четырех размерах блока. В качестве дополнительного задания предлагается найти оптимальный размер блока для рассматриваемых размеров матриц (1024, 2048 и 3072).
Svetlana Svetlana