Инспектор
Вы можете этот курс.
Опубликован: 22.12.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет путей сообщения
Лекция 7: Оптимальное программирование в архитектуре управления каждым тактом
Пример оптимизированной компоновки "длинных" командных слов для ВС с синхронными ИУ
Выше мы указывали, что все сделанное теперь требует перекомпоновки, сжатия каждого слова для получения командных слов переменной длины. Каждое слово (впереди указывается его длина) должно нести смысловую нагрузку: "что и какое именно устройство должно в данном очередном такте начать выполнять".
Рассмотрим еще один, более конкретный пример компоновки "длинного" командного слова для ВС, разрабатываемой в 1970-е годы. Проект, основанный на архитектуре "в остаточных классах", не получил должного освещения в годы "холодной войны", тем более, что авторы сами перестали настаивать на его воплощении. Но это был, по-видимому, первый в мире опыт реализации принципа "длинного" командного слова.
Пусть АЛУ процессора ВС состоит из трех многофункциональных блоков ИУ, работающих синхронно. Два блока — универсальные, они содержат специализированные по операциям ИУ (будем называть их основными ИУ) и с их помощью выполняют основной набор операций. Третий блок ИУ обеспечивает обмен СОЗУ (с регистрами которого и только которого работают основные ИУ) с памятью других уровней. Синхронизация работы блоков ИУ осуществляется заданием инструкции каждому из них в соответствующей части командного слова. Т.е. любое командное слово состоит из трех частей, в каждой из которых может быть записана одна инструкция. В первых двух частях содержатся инструкции первому и второму блокам основных ИУ, в третьей — инструкция ИУ обмена. Возможно отсутствие инструкций отдельным блокам ИУ, что эквивалентно простоям ИУ в их составе.
Для выполнения каждой основной инструкции назначается ИУ определенного типа из числа свободных. При отсутствии свободных ИУ для выполнения хотя бы одной инструкции командного слова выполнение этого командного слова (а следовательно, и программы) задерживается.
Предположим, что инструкции, назначенные для выполнения одновременно (в один машинный такт), выполняются назначенными для этого ИУ синхронно за одинаковое и равное для всех операций число машинных тактов t0 = 2.
Обмен выполняется за время t1 = 1.
Предположим, что в ВС для уплотнения записи программы используются элементы адресного распараллеливания, а именно:
- командное слово не выполняется, если хоть один операнд его инструкции, представленный адресом СОЗУ, совпадает хоть с одним результатом предыдущих t0-1 командных слов;
- внутри командного слова инструкции обладают приоритетом, убывающим слева направо.
Блокировка выполнения инструкции осуществляется в соответствии с адресным способом распараллеливания в том случае, если в ней в качестве операнда фигурирует адрес, являющийся в еще не выполненной инструкции более старшего приоритета адресом результата. Если выполнение второй основной инструкции задерживается, то вместе с ней задерживается выполнение и инструкции обмена. Таким образом, будем считать, что пропуск необходимого числа тактов производится автоматически.
Пусть необходимо написать оптимальную программу счета величин

 (7.1)
(7.1)
Программа до оптимизации, написанная "в линеечку", представлена на рис. 7.1.
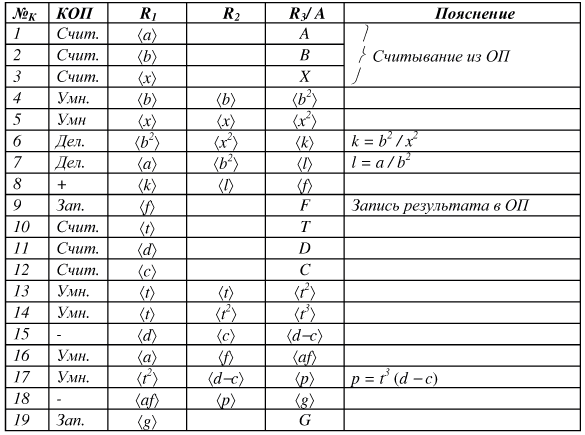
В позициях R1 и R2 указываются первый и второй адреса операндов. Это адреса СОЗУ. R3 — адрес результата в СОЗУ, A — адрес считывания или записи в ОП. Использован набор инструкций, содержание которых ясно из их записи.
На рис. 7.2 представлен информационный граф G, отражающий взаимосвязь инструкций. Другим цветом отмечены работы по обмену.
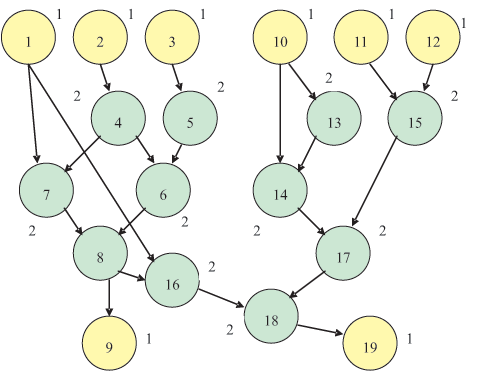
В графе G можно найти длину Tкр критического пути. Опыт подсказывает: практические возможности распараллеливания линейного участка программы таковы, что правомерно считать достаточным количество ИУ для выполнения оптимизированной программы за время Tкр. Значит, мы заранее можем для данного линейного участка считать заданным ограничение времени его выполнения T = Tкр. При необходимости легко предусмотреть в алгоритме динамическую коррекцию этого значения. Это позволяет использовать значения поздних сроков окончания выполнения работ и сформулировать более эффективное при данном применении решающее правило, приведенное ниже:
среди множества инструкций, выполнение которых может
начаться с данного момента времени, преимущественным правом назначения обладают инструкции, имеющие
минимальное значение позднего срока окончания выполнения
при текущем значении длины критического пути. Если несколько инструкций обладают минимальным
значением позднего срока окончания выполнения, то в первую очередь назначаются инструкции
с максимальным суммарным временем выполнения, которые
включают время выполнения данной инструкции и сумму времен выполнения всех инструкций (на основе
транзитивных связей!), использующих результат данной инструкции.
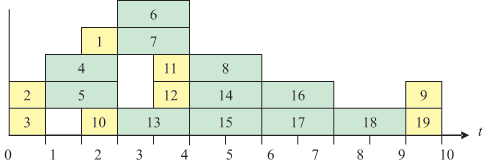
На рис. 7.3 представлена диаграмма выполнения работ (инструкций), иллюстрирующая нахождение поздних сроков окончания их выполнения при T = Tкр = 12.
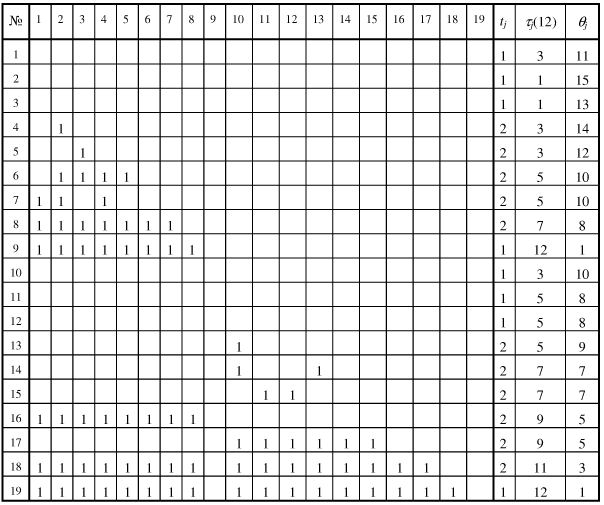
На рис. 7.4 представлена расширенная матрица следования S*,
где для j -й
инструкции, j = 1, ..., 19, указано время tj ее
выполнения, поздний срок
окончания выполнения 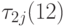 , а также значение
, а также значение  — суммарное время выполнения
всех инструкций, которым данная инструкция предшествует. Эти значения
отыскиваются в результате введения транзитивных связей в матрицу S, что также показано на рисунке.
— суммарное время выполнения
всех инструкций, которым данная инструкция предшествует. Эти значения
отыскиваются в результате введения транзитивных связей в матрицу S, что также показано на рисунке.