| Рабочим названием платформы .NET было |
Инспектор
Вы можете этот курс.
Опубликован: 28.06.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный технический университет им. Н.Э. Баумана
Лекция 3:
Структура программных компонентов
Особые секции PE-файла
Секции PE-файла, как правило, содержат исполняемый код и данные, которые не имеют специального смысла для загрузчика. Но из всякого правила бывают исключения, поэтому далее мы рассмотрим структуру секции импорта ".idata", а также особенности хранения таблицы релокаций в секции ".reloc". В состав PE-файла могут входить и другие особые секции, но мы не будем их обсуждать, так как они не встречаются в сборках .NET.
Секция импорта
В секции импорта перечисляются все dll-файлы, используемые программой, а также все функции и глобальные переменные, импортируемые из этих файлов. Для краткости будем называть такие функции и глобальные переменные символами.
Директория импорта в дополнительном заголовке PE-файла должна указывать на данные, расположенные в секции импорта.
Секция импорта содержит названия dll-файлов и имена импортируемых символов, представленные в виде ASCIIZ-строк. При этом используется непрямая схема хранения этих строк, потому что вся основная информация в секции импорта организована в виде таблиц, а строковые данные, в силу их произвольного размера, в таблицах хранить неудобно. Поэтому названия dll-файлов и имена символов компактно хранятся где-то внутри PE-файла (чаще всего - в каком-нибудь свободном месте секции импорта), и вместо них в таблицах записываются их RVA.
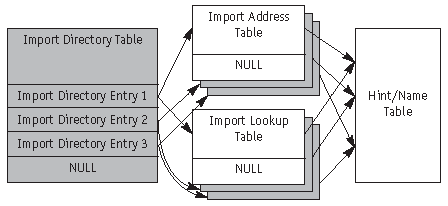
Схема секции импорта приведена на рис. 2.5. Ключевым элементом этой секции является таблица импорта (Import Directory Table), представляющая собой массив так называемых входов в таблицу импорта (Import Directory Entry). При этом самый последний вход в таблицу импорта заполнен нулями и сигнализирует о конце массива.
Каждому dll-файлу, используемому программой, соответствует ровно один вход в таблицу импорта. Этот вход содержит указатели (в форме RVA) на два идентичных массива, которые называются таблицей адресов импорта (Import Address Table, далее IAT) и таблицей имен импорта (Import Lookup Table, далее ILT). Элементы этих массивов описывают символы, импортируемые из данного dll-файла. При этом каждый массив заканчивается нулевым элементом.
Директория таблицы адресов импорта в дополнительном заголовке PE-файла должна указывать на таблицу адресов импорта (IAT).
У тех, кто внимательно прочитал предыдущий абзац, обязательно должен возникнуть вопрос: а зачем нужно хранить в секции импорта два идентичных массива ILT и IAT?
Дело в том, что раньше никакого ILT не было и секция импорта содержала только массив IAT. При загрузке программы происходило так называемое связывание, при котором информация из IAT использовалась для определения адресов импортируемых символов. Эти адреса записывались загрузчиком прямо в IAT (естественно, в образе PE-файла в памяти, а не на диске) поверх той информации, которая там содержалась.
Необходимость в дополнительном массиве ILT возникла после изобретения предварительного связывания, при котором таблица адресов импорта заранее заполняется адресами импортируемых символов. Предварительное связывание осуществляется утилитой BIND, которая вычисляет эти адреса и записывает их прямо в PE-файл на диске. Это позволяет несколько ускорить загрузку программы, но при этом возникают новые проблемы. А что если предварительно связанный dll-файл вдруг изменится? Ведь тогда все адреса могут поменяться? Увы, это так. Правда, загрузчик способен определить этот факт и вычислить новые адреса, и для этого ему как раз и нужна копия таблицы адресов импорта, которая находится в ILT.
Мы не будем рассматривать детали организации секции импорта, относящиеся к механизму предварительного связывания.
Вход в таблицу импорта представляет собой структуру, состоящую из нескольких полей:
long ImportLookupTableRVA;
RVA таблицы имен импорта (ILT). Ранее, до изобретения предварительного связывания, это поле называлось Characteristics.
long TimeDateStamp;
Это поле изначально равно нулю (в PE-файле на диске), но после загрузки dll-файла в него (уже в памяти) записывается время загрузки. (В предварительно связанном PE-файле в поле TimeDateStamp должно быть записано значение -1.)
long ForwarderChain;
Должно быть равно -1.
long NameRVA;
RVA ASCIIZ-строки, содержащей имя dll-файла.
long ImportAddressTableRVA;
RVA таблицы адресов импорта (IAT).
Теперь рассмотрим, как организованы наши идентичные массивы ILT и IAT. Их элементами являются 32-разрядные целые числа. Если старший бит (31-й) такого 32-разрядного числа установлен в 1, то оставшиеся 31 бит обозначают порядковый номер импортируемого символа. Если же старший бит равен 0, то это 32-разрядное число обозначает RVA структуры Hint/Name, в которой хранится имя импортируемого символа.
Структура Hint/Name состоит из трех полей:
short Hint;
Это поле является подсказкой для загрузчика. Оно содержит предполагаемый номер импортируемого символа. Загрузчик сначала ищет этот символ по указанному номеру. В случае неудачи он выполняет бинарный поиск символа по имени.
char Name[x];
Имя импортируемого символа в виде ASCIIZ-строки.
char Pad;
Это поле служит для выравнивания структуры по четной границе, то есть оно присутствует только тогда, когда структура имеет нечетный размер. Всегда равно нулю.
Секция релокаций
В секции релокаций (".reloc") содержится таблица исправлений (Fix-up Table), в которой перечислены все абсолютные адреса в PE-файле, которые надо исправить, если файл загружается по адресу, отличному от указанного в поле ImageBase.
Директория релокаций в дополнительном заголовке PE-файла должна указывать на таблицу исправлений.
Таблица исправлений разбита на блоки. Каждый блок описывает исправления, которые нужно внести в определенную страницу (4K байт) загруженного в память PE-файла. Каждый блок должен начинаться на 32-битовой границе.
В начале каждого блока располагается заголовок, состоящий из следующих полей:
long PageRVA;
Это поле содержит RVA страницы PE-файла, исправления в которой описываются данным блоком.
long BlockSize;
Суммарный размер блока в байтах, включая заголовок.
После заголовка следует массив 16-разрядных слов, каждое из которых описывает одно исправление. При этом старшие четыре бита каждого из этих слов задают тип исправления, а остальные 12 бит обозначают смещение относительно начала страницы, соответствующей данному блоку.
В сборках .NET в качестве типа исправления используется значение 3. Этот тип означает, что по заданному смещению относительно начала описываемой блоком страницы PE-файла находится 32-разрядное значение, которое необходимо исправить.
Рассмотрим, как загрузчик выполняет исправление образа PE-файла. Пусть ActualAddress - это адрес, по которому загружен PE-файл. И пусть delta - это смещение исправляемого 32-разрядного значения относительно начала страницы. Тогда адрес исправляемого значения вычисляется следующим образом:
FixupAddress = ActualAddress + PageRVA + delta;
Внесение исправления в 32-разрядное значение, которое находится по адресу FixupAddress, выполняется так (преобразования типов для простоты не указаны):
*FixupAddress += ActualAddress - ImageBase;