|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Инспектор
Вы можете этот курс.
Опубликован: 30.07.2013 | Уровень: для всех | Доступ: платный
Лекция 9:
Управление групповым трафиком
Такое выражение протокола MLDv2 на языке теории множеств имеет одну любопытную особенность. Когда составленная нами таблица предписывает послать
запрос, ограниченный группой и списком источников, может так оказаться, что список источников пуст. Например, в последнем правиле таблицы,
EXCLUDE/BLOCK, такая ситуация возникнет, если A — это подмножество Y: 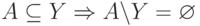 .
На первый взгляд, выходит, что надо послать запрос Q(Г,
.
На первый взгляд, выходит, что надо послать запрос Q(Г,  ), где — пустое множество.
Но, если мы составим такой запрос, то он окажется неотличим от запроса, ограниченного только группой, Q(Г) — см. формат запроса MLDv2.
Как разрешить эту двусмысленность? На самом деле, очень просто: запрос Q(Г, ) риторический и никакого ответа не
предполагает, а значит, и слать его совершенно ненужно. Ведь запрос всегда ставится в режиме INCLUDE, и на пустой список источников ответа
никогда не было бы в принципе. Иными словами, единственный режим слушателя, который мог бы вызвать ответ на Q(Г, ),
— это INCLUDE(), но этот режим эквивалентен прекращению приема группы.
), где — пустое множество.
Но, если мы составим такой запрос, то он окажется неотличим от запроса, ограниченного только группой, Q(Г) — см. формат запроса MLDv2.
Как разрешить эту двусмысленность? На самом деле, очень просто: запрос Q(Г, ) риторический и никакого ответа не
предполагает, а значит, и слать его совершенно ненужно. Ведь запрос всегда ставится в режиме INCLUDE, и на пустой список источников ответа
никогда не было бы в принципе. Иными словами, единственный режим слушателя, который мог бы вызвать ответ на Q(Г, ),
— это INCLUDE(), но этот режим эквивалентен прекращению приема группы.
Выражаясь на модном сегодня новоязе а-ля "1984", это не-режим не-слушателя.
Теперь нам осталось исправить всего несколько мелких деталей, чтобы считать нашу работу над MLDv2 завершенной. Для этого вернемся к нашему списку усовершенствований на стр. 188 и поглядим, что в нем осталось без внимания. Это оказывается взаимодействие между маршрутизаторами одного канала. Чтобы начать совместную работу, они должны, прежде всего, выбрать, кто из них будет генератором запросов. У нас уже есть готовая процедура выборов (стр. 185), которая оперирует только адресами маршрутизаторов и потому нас вполне устраивает.
В связи с этой процедурой возникает таймер, с помощью которого наблюдатель может обнаружить, что текущий генератор запросов ушел со сцены.
Этот таймер перезапускается на интервал OQPT (Other Querier Present Timeout, тайм-аут присутствия другого генератора запросов) всякий
раз, когда приходит запрос MLD. Если же происходит тайм-аут, значит, запросов давно никто не слал, и пора начать новые выборы. Стандарт
предлагает величину OQPT, равную 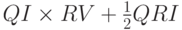 [§9.5 RFC 3810]. Однако на наш взгляд, добавка
[§9.5 RFC 3810]. Однако на наш взгляд, добавка
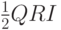 способна привести к тому, что новый генератор запросов возникнет слишком поздно и непрерывность маршрутизации
группового трафика будет нарушена. Убедиться в этом просто. Рассмотрите канал с одним слушателем и двумя маршрутизаторами. Один из
маршрутизаторов, очевидно, генератор, а второй наблюдатель. Когда генератор исчезает, наблюдатель ждет время OQPT, прежде чем послать серию
запросов. Затем слушатель вправе задержать свой отчет на время вплоть до QRI. В результате отчет может запоздать, придя через время
способна привести к тому, что новый генератор запросов возникнет слишком поздно и непрерывность маршрутизации
группового трафика будет нарушена. Убедиться в этом просто. Рассмотрите канал с одним слушателем и двумя маршрутизаторами. Один из
маршрутизаторов, очевидно, генератор, а второй наблюдатель. Когда генератор исчезает, наблюдатель ждет время OQPT, прежде чем послать серию
запросов. Затем слушатель вправе задержать свой отчет на время вплоть до QRI. В результате отчет может запоздать, придя через время
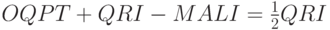 после того, как оставшийся маршрутизатор прекратил продвижение группы в канал по тайм-ауту MALI.
Более подходящим значением для OQPT будет просто
после того, как оставшийся маршрутизатор прекратил продвижение группы в канал по тайм-ауту MALI.
Более подходящим значением для OQPT будет просто 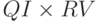 .
.
Когда маршрутизатор только включается в работу или участвует в выборах, ему надо позаботиться, чтобы его запрос наверняка услышали другие
маршрутизаторы, а также слушатели. Ради устойчивости к потере пакетов он передает такой запрос несколько раз (по умолчанию
RV [§9.7 RFC 3810]), разделяя повторы паузами (по умолчанию 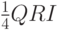 [§9.6 RFC 3810]).
[§9.6 RFC 3810]).
После выборов все маршрутизаторы кроме генератора запросов замолкают и ведут только пассивное наблюдение за чужими сообщениями MLD. Чтобы такая система работала устойчиво, состояние наблюдателей должно быть согласовано с генератором в том, что касается управляющих записей и таймеров. Для этого, в первую очередь, наблюдатели должны получить от генератора его текущие значения параметров QI и RV, так как от них зависит длина интервала MALI. Эти значения обозначают, соответственно, QQI (Querier’s QI) и QRV (Querier’s RV), чтобы подчеркнуть, что они исходят от генератора запросов.
Как следствие, формат запроса MLDv2 должен предусмотреть поля для этой информации. Значение QRV можно поместить в пакет как есть, в беззнаковом коде. Соответствующее поле тоже обозначают QRV (Querier’s Robustness Variable, RV генератора запросов) [§5.1.8 RFC 3810]. В то же время, значение QQI, если представить его как число миллисекунд в 16-битном беззнаковом коде, может расти только до 65,535 секунд, а кроме того, миллисекундная точность на всем диапазоне значений здесь излишня. Поэтому для передачи QQI мы чуть позже разработаем новый код. Он же пригодится и для передачи значений MRD (максимальной задержки отчета). Поле для хранения QQI в этом коде обозначают QQIC (Querier’s Query Interval Code, код интервала запросов генератора) [§5.1.9 RFC 3810].
Далее, когда дело доходит до быстрой проверки группы, в игру вступают интервал LLQI, счетчик повторов LLQC и тайм-аут LLQT. Значения этих параметры тоже должны быть согласованными, чтобы наблюдатель не удалил запись об источнике или не переключил режим фильтра группы раньше времени. Впрочем, эти параметры явным образом передавать не надо. Вот наше тому обоснование:
- По умолчанию значение LLQC совпадает с RV, а рекомендуемое значение RV уже объявляется генератором запросов в поле запроса QRV.
- При быстрой проверке максимальная задержка отчета, MRD, равна LLQI, а значение параметра MRD уже содержится в запросе. Поэтому наблюдателям достаточно выполнить обратную операцию и принять рабочее значение LLQI равным MRD из полученного запроса.
- Значение LLQT однозначным образом зависит от LLQI и
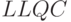 :
:
 .
.
Чтобы не быть голословными, сошлемся на существующие реализации. Например, именно так поступает модуль MLDv2 в XORP3 http://www.xorp.org/ : он принимает LLQC равным QRV, а LLQI равным MRD, если принят запрос с ненулевым адресом группы.
Но каким образом наблюдатели узнают, что началась быстрая проверка? Эту информацию можно извлечь из того, какого вида запрос:
- Если запрос общий, с нулевым адресом группы и пустым списком источников, то это явно не быстрая проверка, а начальный или периодический запрос. Из такого запроса надо извлечь только значения RV и QI.
- Если запрос ограничен только ненулевой группой, а список источников в нем пустой, то это
быстрая проверка, остались ли на канале слушатели группы в исключающем режиме. В этом случае
надо понизить интервал таймера на фильтре указанной группы до LLQT.
Согласно принципу Постела, получатель запроса должен сначала убедиться, что фильтр указанной группы работает в исключающем режиме.
- Если же запрос ограничен ненулевой группой и непустым списком источников, то он служит для быстрой проверки указанных источников данной группы. Для наблюдателя это повод понизить интервалы таймеров на всех перечисленных источниках данной группы до LLQT.
Конечно, наблюдателю не помешало бы убедиться, что запрос исходит именно от генератора запросов. Пунктуальная реализация может помнить адрес текущего генератора и обновлять его, если пришел запрос с еще меньшим адресом источника IPv6. Однако в этом случае придется также учесть сценарий с исчезновением генератора. На практике достаточно сравнить адрес источника запроса с собственным адресом наблюдателя и проигнорировать запрос, если наш локальный адрес меньше. Остальную работу по стабилизации системы здесь выполнит механизм выборов генератора. Ведь он гарантирует , что в конце концов останется ровно один активный генератор, который и станет диктовать остальным значения параметров.
Эта черновая схема взаимодействия между генератором запросов и пассивными наблюдателями неплохо выглядит на бумаге, однако она не учитывает, что пакеты иногда теряются. Увы, сейчас злая фея Реальность немного спутает нам карты и усложнит полученное решение.
В действительности генератор запросов никогда не знает, что запрос дошел до всех наблюдателей. Обратной связи от наблюдателей к генератору нет - и не будет, чтобы не усложнять протокол сверх меры. Поэтому единственное средство, доступное генератору, - это повторять запрос несколько раз, повышая тем самым вероятность успешной передачи информации. И если периодические запросы не надо дублировать, поскольку они и так повторяются с интервалом QI, то запросы для быстрой проверки приходится повторять еще по LLQC - 1 раз. Это поведение для нас не ново, ведь и до слушателей запрос может дойти не с первого раза. Тем не менее, появление на сцене наблюдателей вносит в нашу схему дополнительный элемент неопределенности.
Представим себе, что на канале заведомо один и только один групповой маршрутизатор — генератор запросов. В таком умозрительном случае маршрутизатор вправе прекратить повтор запроса, как только придет первый отчет о данной группе и, возможно, источниках. Действительно, зачем повторять запрос, если искомая информация уже получена? Вернемся теперь в объективную реальность, где маршрутизаторов вполне может быть несколько. В этом случае приход отчета не дает генератору права прекратить повтор, потому что кто-то из наблюдателей мог и не получить отчет или запрос. Действуя согласно принятой модели, что только повтор обеспечивает требуемую вероятность успеха, генератор обязан передать запрос LLQC раз, и ни разом меньше.
Какие сложности это вызывает? В нашей рабочей схеме каждый экземпляр запроса управляет таймерами наблюдателей, понижая их интервал до небольшой величины LLQT. Поэтому возможен, к примеру, такой сценарий с участием генератора, наблюдателя и слушателя, составленный для LLQC = 2:
- Генератор шлет первый экземпляр запроса Q(Г,S).
- Наблюдатель понижает таймеры на источниках S до LLQT.
- Слушатель после короткой паузы отвечает отчетом, подтверждая свой интерес к источникам S.
- Генератор и наблюдатель получают отчет и перезапускают таймеры S с длинным интервалом MALI.
- Генератор повторяет запрос Q(Г,S).
- Наблюдатель понижает таймеры на источниках S до LLQT.
- Слушатель не отвечает или отчет не доходит до наблюдателя.
- Наблюдатель получает тайм-аут на источниках S и блокирует их.
- Синхронизация генератор-наблюдатель нарушена!
Аналогичный сценарий можно составить и для запроса Q(Г), ограниченного только группой. В нем у наблюдателя сработает таймер фильтра.
К сожалению, генератор запросов действует в условиях недостатка информации и поэтому не может дать стопроцентную гарантию того, что наблюдатель получит все необходимые сведения даже после сбоя сети. Видимо, лучшее, что мог сделать генератор на шаге 5 нашего сценария, — это сообщить наблюдателю: больше не понижай таймеры, так как источники S все еще востребованы в данной группе. Эту информацию можно закодировать одним битом в формате запроса. По смыслу этот бит — просто флаг, надо ли наблюдателям понижать соответствующие таймеры. Он возникнет на месте поля "резерв", поэтому его значение 1 отвечает новому поведению: не понижать таймеры. Отсюда его название: "подавить обработку маршрутизаторами" (Suppress Router-Side Processing), сокращенно "флаг S" [§5.1.7 RFC 3810].
Как генератор запросов определит, что пора установить этот флаг? Если мы предположим, что слушатели подтвердили свой интерес ко всем источникам
множества S в запросе, то будет достаточно отметить этот факт установкой флага S в том образе запроса, который генератор хранит в своей
оперативной памяти. Тогда последующие копии запроса уйдут с S = 1. Однако в действительности может оказаться, что подтвержден интерес только к
подмножеству источников 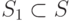 . Как генератору запросов разделить подмножества
. Как генератору запросов разделить подмножества
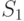 и
и 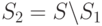 , когда придет время повторить запрос? Здесь ему помогут значения таймеров. Ведь у
подтвержденного подмножества таймеры перезапущены и снова отсчитывают длинный интервал MALI, тогда как у неподтвержденного
подмножества значения таймеров по-прежнему не превышают LLQT. Так как флаг S один на все сообщение, генератору придется разбить
запрос на два. В первом из них будет перечислено подмножество источников и установлен флаг S (S = 1); во втором же окажется
подмножество источников
, когда придет время повторить запрос? Здесь ему помогут значения таймеров. Ведь у
подтвержденного подмножества таймеры перезапущены и снова отсчитывают длинный интервал MALI, тогда как у неподтвержденного
подмножества значения таймеров по-прежнему не превышают LLQT. Так как флаг S один на все сообщение, генератору придется разбить
запрос на два. В первом из них будет перечислено подмножество источников и установлен флаг S (S = 1); во втором же окажется
подмножество источников 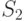 , а флаг S будет сброшен (S = 0).
, а флаг S будет сброшен (S = 0).
Флаг S имеет смысл и для запросов, ограниченных только группой. В этом случае речь идет о подтверждении исключающего режима. Так как маршрутизатор не может находиться в нем наполовину, делить будущие копии запроса ему точно не придется. Тем не менее, критерий, установить ли флаг S, может быть тем же, с точностью до замены таймера источника на таймер фильтра: если таймер фильтра по-прежнему не превышает LLQT, то S = 0, а если он вдруг стал больше LLQT, то значит, пора установить S = 1.
Теперь наблюдатели понижают таймеры не по любому запросу Q(Г) или Q(Г,S), а только если в нем S = 0. Для нас это повод уточнить условия, когда то же самое делает генератор запросов. Если бы наблюдателей не было вообще, генератор мог бы сделать это единожды, в самом начале серии запросов. Ведь вся наша арифметика тайм-аутов MALI и LLQT была основана именно на этой модели. С другой стороны, если бы наблюдатели существовали, но пакеты всегда достигали бы цели, генератор тоже мог бы понизить таймеры в начале серии, а флаг S установить сразу после первого запроса, чтобы наблюдатели поступили с таймерами так же. То есть первый запрос серии вызвал бы установку таймеров на всех маршрутизаторах канала, а последующие дубликаты запроса на них бы не влияли. Но в действительности первый запрос серии может потеряться, как любой другой. Именно поэтому генератор запросов устанавливает флаг S не раньше, чем он получит подтверждение, что энный запрос хоть до кого-то дошел (в данном случае до слушателя). Поэтому пусть ради синхронизации с наблюдателями генератор тоже продолжает понижать соответствующие таймеры до LLQT всякий раз, пока он передает запрос с S = 0.
Конечно, этот трюк нарушает четкость нашего плана, как согласовать тайм-аут записи с ритмом повторяемых запросов, но он помогает синхронизации маршрутизаторов канала. С одной стороны, теперь время жизни записи может продлиться дольше, чем это необходимо. Так, если заинтересованных слушателей не осталось и на запрос ответить некому, запись проживет интервал LLQT после последнего запроса, хотя по нашему первоначальному плану она прекратила бы свое существование через минимально необходимое время LLQI. С другой стороны, теперь выше вероятность того, что тайм-аут записи произойдет практически одновременно на всех маршрутизаторах.
Окончательные правила синхронизации между генератором запросов и пассивными слушателями оказываются такими:
-
Подготовка к передаче запроса — только для генератора [§7.6.3 RFC 3810]:
a. Запрос, ограниченный только группой Г: Если таймер фильтра Г меньше или равен LLQT, то флаг S надо сбросить в 0, а иначе установить в 1.
b. Запрос, ограниченный группой Г и списком источников S: Если все таймеры S меньше или равны LLQT, то флаг S надо сбросить в 0, а если больше — установить в 1. В смешанном случае запрос надо разбить на два, один с S = 0, а другой с S = 1.
-
Действия по приему или передаче запроса — как для генератора, так и наблюдателей [§7.6.1 RFC 3810]:
a. Если в запросе флаг S сброшен в 0:
i. Запрос, ограниченный только группой Г: Понизить таймер фильтра Г до LLQT.
ii. Запрос, ограниченный группой Г и списком источников S: Понизить таймеры источников из списка S до LLQT.
b. Если же в запросе флаг S установлен в 1, то текущие таймеры не трогать.
Эта процедура действительно способна помочь синхронизации между генератором запросов и наблюдателями после кратковременного сбоя в сети. Например, если в нашем вышеизложенном сценарии самый первый отчет слушателя дойдет до наблюдателя, но не дойдет до генератора, наблюдатель повысит таймеры до MALI, тогда как у генератора они продолжат отсчитывать короткий интервал LLQT. Однако затем генератор повторит свой запрос с S = 0, и наблюдатель снова понизит таймеры, так что синхронизация будет восстановлена.
На этом мы почти завершили усовершенствование MLD и практически готовы объявить вторую версию протокола готовой к применению. Последнее, о чем нам следует подумать, — это совместимость с первой версией.
У совместимости между протоколами, по большому счету, два аспекта. Первый из них — это совместимость сообщений, которыми обмениваются стороны протокола, а второй — совместимое поведение сторон в ответ на принятые сообщения. Конечно же, эти аспекты связаны между собой.
Совместимость сообщений — это, по сути, однозначность их интерпретации. Скажем, если в запросе MLDv2 мы изменим код поля "максимальная задержка отклика" , 4 В MLDv1 это поле обозначалось как MRD. то нам надо позаботиться, чтобы слушатель MLDv1 не применил к этому полю ошибочную интерпретацию. Продемонстрируем это на практике. Мы как раз собирались разработать новый код для значений QI и MRD в запросе, так что давайте сделаем его обратно совместимым с целым беззнаковым кодом.
Вот один из способов обеспечить такую совместимость: пусть старший бит поля указывает на способ его кодирования. Когда этот бит сброшен, остаток поля составлен в целом беззнаковом коде. Очевидно, что старая реализация не знает о такой роли старшего бита и примет его за нулевой старший разряд. В результате она получит то же самое численное значения поля, и совместимость будет достигнута. Пока маршрутизатор MLDv2 работает в режиме совместимости, он вправе пользоваться только этим кодом. Когда же совместимость не требуется, можно применить альтернативный код, на который укажет установленный старший бит поля.
Наша цель — представить широкий диапазон значений с разумной точностью, а этому условию
отвечает код с плавающей запятой, похожий на
экспоненциальную (научную) нотацию чисел. В этом коде число приближенно записывают как
мантиссу в оптимальном диапазоне, помноженную на степень
основания системы счисления, в данном случае 2: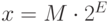 . Здесь M —
мантисса фиксированной точности, а E — целочисленный
порядок числа.
. Здесь M —
мантисса фиксированной точности, а E — целочисленный
порядок числа.
Двоичная мантисса фиксированной разрядности будет оптимальной, если все ее биты будут значащими. Это также называют нормализованной записью. Проще говоря, в мантиссе не должно быть ведущих нулей, потому что они не содержат информации. Следовательно, старший бит в M обязан быть равен единице, ведь иначе он будет незначащим. Поэтому установленный старший бит можно подразумевать, а не хранить явно, и этим выиграть еще один младший бит. Так мы компенсируем расход одного бита на указание способа кодирования поля.
Хотя обычно принимают, что в нормализованной записи запятая находится после самого старшего разряда мантиссы, нам сейчас удобнее поместить ее после самого младшего разряда, чтобы мантисса оставалась целой. Очевидно, что эти два представления однозначно преобразуются друг в друга простым сдвигом, то есть изменением порядка E на число явно хранимых разрядов мантиссы, если старший разряд подразумевается. Например, двоичная мантисса 1,0001 преобразуется в 10001 вычитанием 4 из порядка, чтобы значение закодированного числа оставалось неизменным.
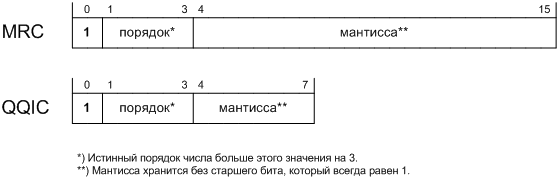
Применим такой код к 16-битному полю, где будет храниться значение MRD. Ввиду нового
кода это поле и обозначают по-другому: MRC
(Maximum Response Code, код максимальной задержки отклика) [§5.1.3 RFC 3810].
Пусть порядок занимает 3 бита. Еще один бит "съел" флаг
кода. Тогда на мантиссу остается 12 бит. Значения до 32767 мы уже можем представить в старом
коде, поэтому нам интересен диапазон от
 и выше. Этому отвечают значения порядка от 3:
и выше. Этому отвечают значения порядка от 3:
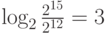 . Поэтому нам следует сместить
порядок на 3 для расширения диапазона. Двоичные значения поля мантиссы и поля порядка
будут представлены в обычном целом беззнаковом коде.
Тогда численное значение MRD в новом коде будет равно
. Поэтому нам следует сместить
порядок на 3 для расширения диапазона. Двоичные значения поля мантиссы и поля порядка
будут представлены в обычном целом беззнаковом коде.
Тогда численное значение MRD в новом коде будет равно
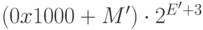 .
.
Рассчитайте, каковы минимальное и максимальное значения поля MRC в новом коде. (32 768 и 8 387 584.)
Тем же самым способом мы решим задачу о кодировании поля QQIC для хранения значений
QQI [§5.1.9 RFC 3810]. Это поле длиной 8 бит,
причем 3 из них отведены под порядок и 4 под мантиссу. Следовательно, численное значение поля,
когда его старший бит установлен, следует
вычислять так: 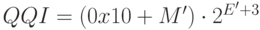 .
.
Рассчитайте, каковы минимальное и максимальное значения поля QQIC в новом коде. (128 и 31 744.)
Расширенные форматы полей MRC и QQIC в отчете MLDv2 показаны на рис. 8.8.
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |