| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 19.10.2012 | Уровень: специалист | Доступ: платный
Лекция 3:
Расширенная индексная нотация
Аннотация: Лекция посвящена использованию и средствам работы с массивами в Intel® CilkTM Plus, прежде всего расширенной. Рассматриваются поэлементные операции с массивами, операции сбора/распределения данных, использование массивов в качестве аргументов и другие вопросы.
Ключевые слова: язык программирования, структура данных, нотация, секция, сечение, компилятор, операторы, операции, ранг, операнд, оператор присваивания, пересечение, сложение, параметр, значение
Презентацию к лекции Вы можете скачать здесь.
Язык программирования должен предоставлять разработчику удобное средство отображения параллелизма данных в задаче на параллельную архитектуру. Языком, располагающим удобными и разнообразными средствами работы с массивами, является Fortran. В C/C++ нет удобных средств работы с массивами. C/C++ - доминирующий язык разработки приложений.
Массивы – основная структура данных в вычислительных приложениях.
Расширенная индексная нотация – главное отличие CilkTM от CilkTM Plus.
Определение:
{<имя массива или указатель на него>[<нижняя граница значений индекса>:<длина>[: <шаг изменения индекса>]]}
Символ ":" является указанием на множество элементов массива (секцию или сечение массива).
Символ ":", используемый без указания длины и шага, является указанием на множество всех элементов массива.

Синтаксис расширенной индексной нотации отличается от синтаксиса сечений в Fortran!
Использование расширенной индексной нотации является сигналом компилятору выполнить векторизацию кода. Компилятор векторизует код с расширенной векторной нотацией, отображая его на целевую архитектуру.
Примеры:
A[:] // Все элементы вектора A
B[3:5] // Элементы с 3 по 5 массива B
C[:][7] // Столбец 7 матрицы C
D[0:3:2] // Элементы 0,2 и 4 массива D
E[0:5][0:4] // 20 элементов с E[0][0] по E[5][4]
Большинство "стандартных" арифметических и логических операций C/C++ могут применяться к секциям массивов:
+, -, *, /, %, <,==,!=,>,|,&,^,&&,||,!,-(unary), +(unary),++,--, +=, -=, *=, /=, *(p)
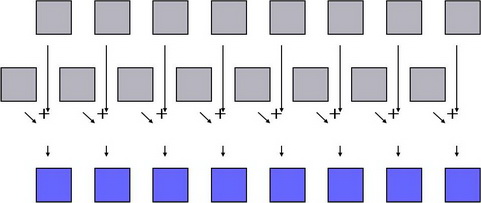
Операторы применяются ко всем элементам секции массива:
a[:] * b[:] // поэлементное умножение
a[3:2][3:2] + b[5:2][5:2] // сложение матриц 2x2
Операции могут выполняться с разными элементами параллельно.
Секции, используемые в качестве операндов, должны быть конформными (иметь одинаковые ранг и экстент):
a[0:4][1:2] + b[1:2] // так не должно быть!
Скалярный операнд автоматически расширяется до секции необходимой формы:
a[:][:] + b[0][1] // сложение b[0][1] со всеми элементами матрицы a
Оператор присваивания выполняется параллельно для всех элементов секции:
a[0:n] = b[0:n] + 1;
Ранги правой и левой частей должны совпадать. Допустимо использование скалярных величин:
a[:] = c; // c заполняет массив a
e[:] = b[:][:]; // ошибка!
Допустимо пересечение правой и левой частей в операторе присваивания (в этом случае используются временные массивы):
a[1:s] = a[0:s] + 1; // используется старое значение a[1:s-1]
Поэлементные векторные операции
Пример:
a[:]+b[:]
Пример. Сложение двух массивов
#include <iostream>
int main() {
double a[4] = {1.,2.,3.,4.};
double b[4] = {5.,7.,11.,13.};
double c[4] = {0.,0.,0.,0.};
std::cout << "Вывод a:\n" << a[:] << " ";
std::cout << std::endl << std::endl;
std::cout << "Вывод b:\n" << b[:] << " ";
std::cout << std::endl << std::endl;
std::cout << "Вывод c:\n" << c[:] << " ";
std::cout << std::endl << std::endl;
c[:] = a[:] + b[:];
std::cout << "c = a + b:\n" << c[:] << " ";
std::cout << std::endl << std::endl;
}
#include <iostream>
int main() {
bool x[4] = {0, 0, 1, 1};
bool y[4] = {0, 1, 1, 0};
double a[4] = {1.,2.,3.,4.};
double b[4] = {5.,7.,11.,13.};
double c[4] = {0.,0.,0.,0.};
std::cout << "Вывод a:\n" << a[:] << " ";
std::cout << std::endl << std::endl;
std::cout << "Вывод b:\n" << b[:] << " ";
std::cout << std::endl << std::endl;
std::cout << "Вывод до c:\n" << c[:] << " ";
std::cout << std::endl << std::endl;
c[:] = x[:] && y[:] ? a[:] : b[:];
std::cout << " Вывод после c:\n" << c[:] << " ";
std::cout << std::endl << std::endl;
}
Пример. Реализация со встроенными функциями
#include <pmmintrin.h>
void foo(float* dest, short* src, long len, float a) {
__m128 xmmMul = _mm_set1_ps(a);
for(long i = 0; i < len; i+=8) {
__m128i xmmSrc1i = _mm_loadl_epi64((__m128i*) &src[i]);
__m128i xmmSrc2i = _mm_loadl_epi64((__m128i*) &src[i+4]);
xmmSrc1i = _mm_cvtepi16_epi32(xmmSrc1i);
xmmSrc2i = _mm_cvtepi16_epi32(xmmSrc2i);
__m128 xmmSrc1f = _mm_cvtepi32_ps(xmmSrc1i);
__m128 xmmSrc2f = _mm_cvtepi32_ps(xmmSrc2i);
xmmSrc1f = _mm_mul_ps(xmmSrc1f, xmmMul);
xmmSrc2f = _mm_mul_ps(xmmSrc2f, xmmMul);
_mm_store_ps(&dest[i], xmmSrc1f);
_mm_store_ps(&dest[i+4], xmmSrc2f);
}
}
Сравнение машинных кодов для обеих реализаций
Интринсики (встроенные функции)
movq (%rsi,%rax,2), %xmm1 #9.18
movq 8(%rsi,%rax,2), %xmm2 #10.18
pmovsxwd %xmm1, %xmm1 #9.18
pmovsxwd %xmm2, %xmm2 #10.18
cvtdq2ps %xmm1, %xmm3 #12.25
cvtdq2ps %xmm2, %xmm4 #13.25
mulps %xmm0, %xmm3 #15.18
mulps %xmm0, %xmm4 #16.18
movaps %xmm3, (%rdi,%rax,4) #18.21
movaps %xmm4, 16(%rdi,%rax,4) , #19.21
addq $8, %rax #5.34
cmpq %rdx, %rax #5.24
jl ..B1.3 # Prob 82% #5.24
Индексная нотация
movq (%rsi,%rcx,2), %xmm2 #2.45
pmovsxwd %xmm2, %xmm2 #2.45
cvtdq2ps %xmm2, %xmm3 #2.45
mulps %xmm1, %xmm3 #2.58
movaps %xmm3, (%rdi,%rcx,4) #2.15
movq 8(%rsi,%rcx,2), %xmm4 #2.45
pmovsxwd %xmm4, %xmm4 #2.45
cvtdq2ps %xmm4, %xmm5 #2.45
mulps %xmm1, %xmm5 #2.58
movaps %xmm5, 16(%rdi,%rcx,4) , #2.15
addq $8, %rcx #2.15
cmpq %r8, %rcx #2.15
jb ..B1.15 # Prob 44% #2.15