Инспектор

Вы можете этот курс.
Опубликован: 04.06.2009 | Уровень: специалист | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 9:
Физические модели данных (внутренний уровень)
Аннотация: Лекция посвящена вопросам физической организации данных в памяти компьютера. Здесь описывается структура памяти компьютера и представлены структуры хранения данных в оперативной и внешней памяти.
Ключевые слова: представление, СУБД, структуры хранения, пользователь, представление данных в памяти ЭВМ, базы данных, время доступа, физические модели данных, поле, логическая запись, логический файл, слово, логический, логическая модель данных, физическая запись, процессор, прямая адресация, иерархическая модель, адрес, запись, предметной области, резюме, память, значение, указатель, длина, экземпляр записи, БД, табличная модель, индексирование, Метод половинного деления, В-дерево, хэш-функция, списковая структура
Цель лекции: дать представление об основных типовых способах организации данных в памяти ЭВМ в СУБД с оценкой соответствующих моделей по времени доступа к данным в базе данных и по объему занимаемой памяти.
Как уже отмечалось, концептуальная схема, специфицированная к СУБД, автоматически отображается в структуру хранения программами СУБД. Внешний пользователь может ничего не знать о том, как его представление о данных физически организовано в памяти вычислительной системы. Тем не менее от физического размещения данных в памяти ЭВМ существенно зависит время решения прикладных задач. В связи с этим, даже на одном из начальных этапов проектирования базы данных – этапе выбора СУБД, желательно знать возможности физических структур хранения, представляемых конкретными СУБД, и оценивать временные характеристики проектируемой базы данных с учетом этих возможностей.
Способы физической организации данных в различных СУБД, как правило, различны и определяются типом используемой ЭВМ, инструментальными средствами разработки СУБД, а также критериями, которыми руководствуются разработчики СУБД при выборе методов размещения данных и способов доступа к этим данным. Заметим, что наиболее распространенным критерием служит время доступа к данным, однако в качестве критерия может выбираться, например, трудоемкость реализации соответствующих методов.
В настоящей лекции будут рассмотрены типовые физические модели организации данных в конкретных СУБД.
Физические модели данных служат для отображения моделей данных. Основными понятиями модели данных являются поле, логическая запись, логический файл. Слово "логический" введено, чтобы отличать понятия, относящиеся к логической модели данных, от понятий, относящихся к физической модели данных. Основными понятиями физической модели данных, используемыми для представления логической модели данных, являются поле, физическая запись, физический файл. В частности, логическая запись, состоящая из полей, может быть представлена в виде физической записи (из тех же полей), логический файл – в виде физического файла. Прежде чем конкретизировать понятия, относящиеся к физической модели данных, рассмотрим структуру памяти ЭВМ.
9.1. Структура памяти ЭВМ
Важнейшей особенностью памяти ЭВМ, в значительной степени определяющей методы организации данных и доступа к ним, является её неоднородность. Существуют два разных типа памяти – оперативная (ОП) и внешняя (ВП), причем процессор работает только с данными из оперативной памяти ( рис. 9.1.).
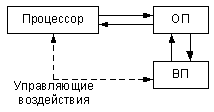
Как уже многократно отмечалось, базы данных создаются для работы с большими объемами данных, что обусловливает необходимость использования внешней памяти. Поэтому организация данных и доступа к ним должна учитывать как специфику каждого типа памяти, так и способы их взаимодействия.
Отметим основные свойства оперативной памяти:
- единицей памяти является байт;
- память прямоадресуема (каждый байт имеет адрес);
- процессор выбирает для обработки нужные данные, непосредственно адресуясь к последовательности байтов, содержащих эти данные.
Отметим основные свойства внешней памяти:
- минимальной адресуемой единицей является физическая запись ;
- для последующей обработки (например, работы с полями) запись должна быть считана в оперативную память;
- время чтения записи в ОП на несколько порядков выше времени обработки процессором записи из ОП;
- организация обмена осуществляется порциями, т.к. невозможно считать сразу всю базу данных.
9.2. Представление экземпляра логической записи
Логическая запись представляется в оперативной памяти следующим образом:
| Логическая запись | Последовательность байтов ОП | |||||||
|---|---|---|---|---|---|---|---|---|
| Поле 1 | Поле 2 | ... | Поле N | 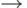 |
B1 | B2 | ... | BN |
| Тип поля | Bi – последовательность байтов ОП, используемая для хранения поля i | |||||||
| Характеристика поля | ||||||||
| Длина | ||||||||
Прямая адресация байтов позволяет процессору выбирать для обработки нужное поле.
Заметим, что указанное представление не делает различий для записей в сетевой, иерархической и реляционных моделях. В случае сетевой и иерархической моделей некоторые поля могут являться указателями, тогда последовательность байтов, используемая для хранения этих полей, содержит адрес начала последовательности байтов, соответствующей записи – члену отношения.
В большинстве современных СУБД используется формат записей фиксированной длины. В этом случае все записи имеют одинаковую длину, определяемую суммарной длиной полей, составляющих запись. В СУБД другие форматы записей (переменной длины, неопределенной длины) встречаются гораздо реже, поэтому в данной книге эти форматы не рассматриваются. Заметим, что поля записи, принимающие значения существенно разной длины в различных экземплярах записей, в предметной области встречаются достаточно часто. Примером может служить поле резюме в записи СОТРУДНИК. Резюме может составлять полстраницы текста, страницу и т.д. Возникает проблема – как эту информацию переменной длины представить в записи фиксированной длины. Возможным вариантом является установление размера соответствующего поля по максимальному значению. В этом случае у многих экземпляров записи указанное поле будет заполнено не полностью и, таким образом, память ЭВМ будет использоваться неэффективно. Более эффективный и часто используемый в СУБД прием организации таких записей состоит в следующем. Вместо поля (полей), принимающего значение существенно разной длины, в запись включается поле-указатель на область памяти, где будет размещаться значение исходного поля. Как правило, эта область является областью внешней памяти прямого доступа. В процессе ввода соответствующего значения в выделенной области занимается столько памяти, какова длина этого значения.
На рис. 9.2 представлен пример вышеуказанного представления экземпляров записей из N полей, причем поле N принимает значения соответственно разной длины у разных экземпляров записей.
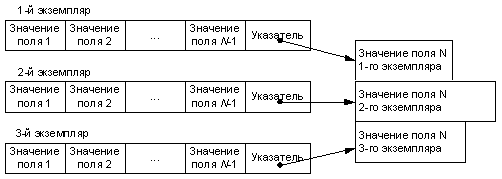
Конкретной реализацией такой схемы является поле типа МЕМО в СУБД (dBase III+, FoxPro, Access и т.д.).