
|
Где проводится профессиональная переподготовка "Системное администрирование Windows"? Что-то я не совсем понял как проводится обучение. |
Инспектор
Вы можете этот курс.
Опубликован: 04.07.2008 | Уровень: специалист | Доступ: платный | ВУЗ: Европейский Университет в Санкт-Петербурге
Лекция 8:
Концепция, устройство и администрирование файловой системы ZFS
RAID-Z
В ZFS предусмотрена реализация RAID-Z – организация программного RAID-массива с блоками переменной длины. Переменная длина дает значительный выигрыш в производительности, но меняет алгоритм восстановления данных, поскольку каждый блок в массиве может иметь разную длину. Кроме этого, в отличие от традиционных массивов RAID, в ZFS можно организовать не только однократный, но и двукратный контроль четности, и это защищает от одновременного сбоя двух физических носителей.
Легко видеть, что ZFS в самом деле гарантирует сохранность данных, если у вас достаточно надежное оборудование – по крайней мере один диск в запасе. Кстати, ZFS поддерживает и диски "горячего резерва" (spare disks), на которые ничего не записывается до момента, когда один из рабочих дисков RAID-Z выйдет из строя. Зато как только понадобится, сбойный диск будет исключен из пула дисков, а диск горячего резерва немедленно включен туда.
Для поддержки зеркалирования в ZFS реализована процедура ресинхронизации (resilvering) после замены сбойного диска исправным. Процедура выполняется автоматически.
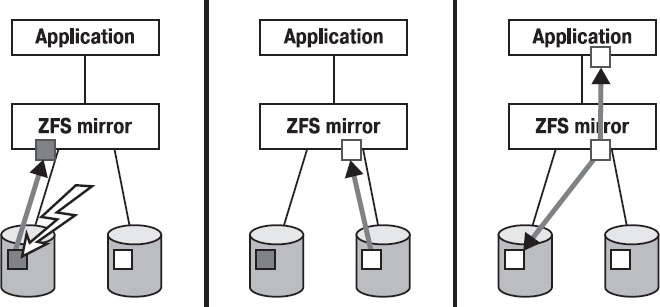
Если же диск не дает сбоев в целом, но какая-то часть даных оказалась повреждена (т.е. контрольные суммы не соответствуют данным), то происходит автоматическая запись на сбойный диск данных с "правильного" диска, как видно на рис. 8.7. Ошибочный блок данных показан серым цветом, корректный – белым. Вначале при выполнении чтения обнаруживается ошибочный блок (расхождение с контрольной суммой), приложению передается корректный блок данных с другого диска в зеркале, и затем сбойный блок на первом диске замещается корректным.
Резервирование метаданных
Все метаданные в ZFS пишутся на диск в нескольно разных мест для большей отказоустойчивости. В зависимости от ценности метаданных, делается три или – как минимум – две копии. В отличие от UFS, где на диск записывается несколько копий только суперблока, здесь делаются копии всех метаданных, причем если в пуле несколько устройств, ZFS старается разнести копии метаданных по разным устройствам.
Таким образом, для надежного хранения данных в ZFS предусмотрены:
- транзакционность;
- контрольные суммы в метаданных;
- программный RAID (RAID-Z), типов "зеркало", "RAID с однократной четностью", "RAID с двукратной четностью";
- диски горячего резерва для RAID-Z;
- "самовосстановление" данных, когда они записываются с избыточностью (т.е. с контролем четности или зеркалированием);
- тройное резервирование метаданных.
Масштабируемость ZFS
Минимальный размер устройства, которое может быть включено в пул ZFS, – 64 мегабайта.
Максимальный размер файла, который можно сохранить в ZFS, – 264 байт, т.е. 16 экзабайт. Это в 18 миллиардов (18,4 x 1018) раз больше, чем позволяют современные 64-битные файловые системы. Максимальный размер одной файловой системы ZFS такой же – 264 байт. Если создавать по 1000 файлов в секунду, то для достижения максимального количества файлов в ZFS (248 штук) понадобится примерно 9000 лет. Нетрудно видеть, что ZFS действительно создавалась так, чтобы избежать скорого достижения лимитов!
Автор проекта ZFS Джефф Бонвик (Jeff Bonwick) подсчитал, что на 100%-е заполнение файловой системы ZFS потребуется больше энергии, чем для того, чтобы вскипятить океан. [ [ 8.3 ] ]
Так, Сет Ллойд (Seth Lloyd) в 2000 году в статье "Ultimate physical limits to computation" [ [ 8.4 ] ] показал, что 1 килограмм материи, ограниченный 1 литром объема, может произвести не более чем 1051 операций над не более чем 1031 битами информации. Заполненный до отказа 128-битный пул памяти будет содержать 2128 блоков = 2137 байт = 2140 бит. Минимальная масса, которая вместит такое количество информации, будет равна (2140 бит) / (1031 бит/кг) = 136 миллиардов килограммов.
Если вспомнить известную формулу зависимости массы и энергии E=mc2 и представить массу такого компьютера в форме энергии, это составит 1.2 x 1028джоулей.
Известно, что масса всех океанов на планете примерно равна 1.2 x 1028 кг, и что для того, чтобы превратить в кипяток 1 кг льда, требуется 400 000 джоулей, причем скрытая энергия на испарение добавит еще 2 000 000 джоулей на килограмм, итого 2,4 x 106 джоулей на килограмм. Стало быть, для испарения океанов надо порядка 2.4 x 106 Дж/кг x 1.4 x 1021 кг = 3.4 x 1027 Дж.
Выходит, заполнить 128-битную файловую систему действительно сложнее, чем вскипятить океан!
Конечно, в этом расчете Джефф не учел, что океан не находится в замороженном состоянии, но – согласитесь – потенциальный объем ZFS все равно впечаталяет! И вряд ли в ближайшие несколько десятилетий бизнес, выбравший ZFS, будет сталкиваться с проблемой переполнения файловой системы – скорее уж перестанет хватать электричества для питания дисковых массивов!
Производительность ZFS
Удивительно, но все эти возможности достались нам в ZFS без снижения производительности: для этого используется несколько важных технологий, среди которых конвейерный механизм ввода-вывода, подобный конвейерам центрального процессора.
Каждая операция ввода-вывода имеет свой приоритет и связанный с ним крайний срок выполнения. Чем выше приоритет, тем ближе крайний срок. С крайним сроком выполнения связывается логический адрес блока (LBA) для операции записи – чем более поздний срок ей назначен, тем меньше будет значение LBA: так достигается практически линейное движение по диску по мере выполнения все менее и менее "срочных" операций. Операции чтения с диска имеют больший приоритет, чем операции записи, потому что при записи асинхронный вызов write() возвратит управление приложению, как только данные попадут в кэш, а вызов read() – синхронный, потому что приложение вынуждено ждать, пока ему будут выданы данные с диска.
Кроме этого, ZFS осуществляет интеллектуальную предвыборку, подбирая схему предвыборки для каждого потребителя данных в отдельности, в отличие от других систем, которые делают предвыборку всегда одинаково – в расчете на последовательный доступ к данным.
При записи ZFS старается писать данные в последовательные блоки, благо схема copy-on-write исключает модификацию уже заполненных данными блоков. ZFS также поддерживает параллельную запись в один файл. Кроме этого, ZFS выбирает размер блока – от 512 байт до 128 Кбайт исходя из соображений производительности диска, а не его размера.
Когда в системе несколько устройств, ZFS балансирует нагрузку на них так, чтобы задействовать каждое с максимальной продуктивностью, и при добавлении нового диска к пулу автоматически заполняет его новыми данными так, чтобы достичь максимальной скорости доступа к данным. Если какое-то устройство в пуле замедлилось из-за сбоя или заполнения значительной части его объема, ZFS старается не записывать на него новых данных, чтобы не снижать общую скорость системы.
Встроенное сжатие данных (для каждой файловой системы можно разрешить компрессию) не только уменьшает занимаемый данными объем на диске, но и уменьшает требуемый объем ввода-вывода вдвое-втрое. Поэтому в системах с быстрым слабо нагруженным процессором включение сжатия ускоряет ввод-вывод.
Вот еще некоторые приемы, которые помогают повысить производительность ZFS – пусть не всегда, но в определенных случаях.
Пустые блоки, если файл содержит таковые, не копируются физически при копировании файла.
В чем здесь идея? Предположим, мы записали 1 байт в начале файла, затем отступили от начала 1 гигабайт, и записали еще один значимый байт в файл. Получили файл размером в 1 гигабайт и 1 байт, который в середине содержит гигабайтное пространство, заполненное нулями. При копировании такого файла нет смысла переписывать все эти нули, это бы значительно снизило скорость операции. Поэтому было найдено решение, логично вытекающее из структуры ZFS: файл в ZFS – это дерево блоков, каждый блок косвенной адресации содержит поле, в котором указывается число блоков, лежащих одним уровнем ниже него (см. рис. 8.8) [ [ 8.5 ] ].
![Файл с нулевыми блоками внутри (рисунок взят из [5]). Файл состоит из 9 блоков, три из которых на 100% заполнены нулями.](/EDI/14_08_14_2/1407964674-31059/tutorial/411/objects/8/files/08_08.jpg)
Рис. 8.8. Файл с нулевыми блоками внутри (рисунок взят из [5]). Файл состоит из 9 блоков, три из которых на 100% заполнены нулями.
Строго говоря, как именно обращаться с файлами, содержащими обширные поля нулей внутри себя, решает не файловая система, а каждое приложение индивидуально. В случае с ZFS файловая система умеет работать с расширенной функцией lseek, в которой поддерживаются операции SEEK_HOLE (найти следующую область нулей, размером не менее переданного lseek аргумента) и SEEK_DATA (найти следующую за областью нулей область единиц, не менее переданного аргумента размером). В Solaris такая функциональность реализована, а пользоваться ей или нет – дело разработчика программы.
Еще один момент – место под файл выделяется согласно простому, но эффективному эмпирическому алгоритму: при выборе блоков для размещения файла выбираются вначале устройство, на которое будет происходить запись, затем область диска – более удаленая от центра диска или менее удаленная, и наконец – собственно блоки. Выбор делается в соответствии с весом каждого устройства, области и блока; вес определяется по правилам, которые в следующих версиях ZFS могут измениться для повышения эффективности. Текущие правила, например, включают предпочтительность записи данных на свободные внешние дорожки дисков, потому что конструкция современных дисков дает двукратное превышение пропускной способности диска при такой записи – по сравнению с внутренними дорожками. Естественно, что это некие усредненные данные – на практике реальный прирост производительности будет зависеть от размера записываемого блока, от размера файла, от конструкции диска и от того, как соотносится размер кэша диска с размером файла и блока.
Что касается цифр, то любое тестирование можно провести так, чтобы нужный продукт выглядел более выигрышно. Поэтому все, что я считаю важным подчеркнуть в отношении известных результатов тестирования ZFS, сводится к перечню тестовых операций, в которых она уже показала значительное (2-6 раз) превышение производительности по сравнению с UFS: [ [ 8.6 ] ]
- открытие файла, резервирование пространства под его расширение и однократная запись в файл;
- последовательная модификация (перезапись) всех данных в файле порциями по 32К;
- создание файла размером 1/2 в свободной памяти посредством записи в него порциями по 1Мб, затем двукратное последовательное чтение всего файла;
- параллельная синхронная запись в 100-мегабайтный файл четырьмя потоками.
Разумеется, количество тестов будет расти с ростом промышленного использования ZFS, так что в скором времени появятся новые результаты.
Александр Тагильцев