Инспектор

Вы можете этот курс.
Опубликован: 25.11.2008 | Уровень: для всех | Доступ: платный
Лекция 3:
Теоретико-графовые модели данных
Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться:
- шаблоны всех записей логических баз данных, доступных пользователю;
- указатели на текущий экземпляр сегмента данного типа — для всех типов сегментов.
Язык манипулирования данными в иерархической модели поддерживает в явном виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента.
Все операторы в языке манипулирования данными можно разделить на 3 группы. Первую группу составляют операторы поиска данных.
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя сегмента> WHERE <список поиска>;
список поиска состоит из последовательности условий вида:
<имя сегмента>.<имя поля>ОС <constant или имя другого поля данного сегмента или имя переменной>;
ОС — операция сравнения;
условия могут быть соединены логическими операциями И и ИЛИ { & , ? }.
Назначение:
Получить единственное значение.
Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ МОДЕЛИ WHERE Типовые модели.Стоимость <= $600 AND Типовые модели.Количество на складе >= 10
Данная команда всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента, удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя сегмента> WHERE <список аргументов поиска>
Назначение:
Получить следующий экземпляр сегмента для тех же условий.
Пример:
Напечатать полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ МОДЕЛИ WHERE Индивидуальные модели.Стоимость >= $500 WHILE NOT FAIL (пока не конец поиска) DO PRINT № заказа, Стоимость, Количество GET NEXT ИНДИВИДУАЛЬНЫЕ МОДЕЛИ END
Синтаксис:
GET NEXT <имя сегмента> WITHIN PARENT [ where <дополн.условия>]
Назначение:
Получить следующий для того же исходного.
Пример:
Получить перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10 с объемом 10 Гбайт.
GET UNIQUE СКЛАД WHERE Склад.Номер = 1 GET NEXT ИЗДЕЛИЕ WITHIN PARENT WHERE Изделие.Наименование = "Винчестер" GET NEXT ХАРАКТЕРИСТИКИ WITHIN PARENT WHERE ХАРАКТЕРИСТИКИ.Параметр = 10 AND ХАРАКТЕРИСТИКИ.Единицы Измерения = Гб AND ХАРАКТЕРИСТИКИ.Величина > 10 WHILE NOT FAIL (пока поиск не завершен) DO GET NEXT WITHIN PARENT end
Операторы поиска данных с возможностью модификации
- Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции над найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис:
GET HOLD UNIQUE <имя сегмента> WHERE <список поиска>
- Найти и удержать следующий с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис:
GET HOLD NEXT [WHERE дополнительные условия>]
- Получить и удержать следующий для того же родителя. Эта операция является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT WITHIN PARENT [ where <дополн.условия>]
Операторы модификации данных
- Удалить
Это первая из трех операций модификации.
Синтаксис:
DELETE
Эта команда не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр сегмента, найденный командами поиска с удержанием. А он всегда единственный текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента. Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
- Обновить
Синтаксис:
UPDATE
Как же происходит обновление, если мы и в этой команде не задаем никаких параметров. СУБД берет данные из рабочей области пользователя, где в шаблонах записей соответствующих внутренних переменных находятся значения полей каждого сегмента внешней модели, с которой работает данный пользователь. Именно этими значениями и обновляется текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый экземпляр сегмента.
INSERT <имя сегмента>
Эта команда позволяет ввести новый экземпляр сегмента, имя которого определено в параметре команды. Если мы вводим данные в сегмент, который является подчиненным некоторому родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим, набор операций поиска и манипулирования данными в иерархической БД невелик, но он вполне достаточен для получения доступа к любому экземпляру любого сегмента БД. Однако следует отметить, что способ доступа, который применяется в данной модели, связан с последовательным перемещением от одного экземпляра сегмента к другому. Такой способ напоминает движение летательного аппарата или корабля по заданным координатам и называется навигационным.
Сетевая модель данных
Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Базовыми объектами модели являются:
Элемент данных — то же, что и в иерархической модели, то есть минимальная информационная единица, доступная пользователю с использованием СУБД.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию "сегмент" в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи.
Следующим базовым понятием в сетевой модели является понятие "Набор". Набором называется двухуровневый граф, связывающий отношением "один-ко-многим" два типа записи.
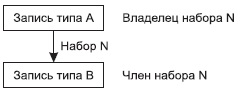
Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора.
Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение "многие-ко-многим" между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора.
Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
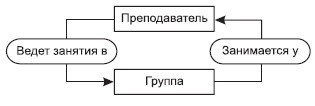
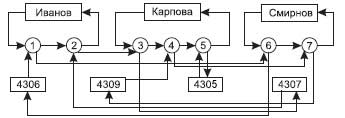
Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляров набора Занимается у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров данных наборов.
Среди всех наборов выделяют специальный тип набора, называемый "Сингулярным набором", владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи "Владелец набора". Например, сингулярный набор М.
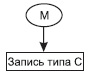
Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор.
В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.